[中平] 网络爬虫:从入门到放弃
确实刚开始又难又无聊
——那为什么要学?
——因为什么都不容易啊
一.什么是网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
———摘自百度百科
简单来说,网络爬虫就是模拟访问互联网,从网络上抓取所需数据的一段程序。我们可以根据需要制作各种各样的爬虫,在合法范围内爬取任何你在互联网上看到的数据。
二.网页结构
网页一般由三部分组成,分别是 HTML(超文本标记语言)、CSS(层叠样式表)和 JavaScript(活动脚本语言)。
- HTML
HTML 是整个网页的结构,相当于整个网站的框架。其中包含网页中的元素及其内容。
带“<”、“>”符号的叫做 HTML 的标签,并且标签都是成对出现的。
常见的标签如下:
.. 表示标记中间的元素是网页
.. 表示用户可见的内容
<div>..</div> 表示框架
<p>..</p> 表示段落
<li>..</li> 表示列表
<img src="">.. 表示图片
<h1>..</h1> 表示标题
<a href="">..</a>表示超链接
写一个简单的 HTML 代码
打开一个记事本,然后输入下面的内容:
<html>
<head>
<title> Test </title>
</head>
<body>
<div>
<p> Hello World</p>
</div>
</body>
输入代码后,保存记事本,然后修改文件名和后缀名为"Test.html";

点开后可看到只有一行Hello World的网页;
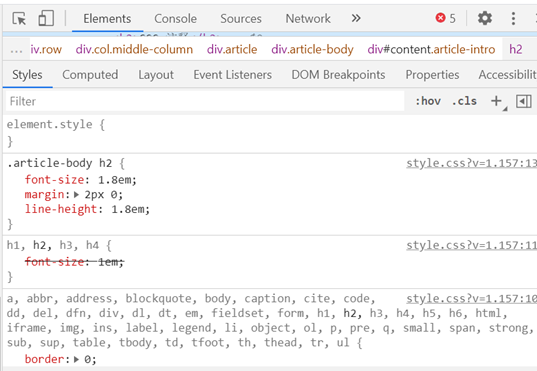
- CSS
CSS描述应如何显示HTML中的各个元素,例如规定字体大小、颜色等;
点击F12在下方样式(Styles)栏中可查看网页CSS代码:
- JavaScript
JavaScript可改变HTML中的元素,使网页呈现时可产生动态或变化效果;
三.突然想讲一句话:URL统一资源定位器 差不多就是网址的意思
四.爬虫的基本原理
基本原理简单说就两个字:模拟
网络爬虫就是模拟人类上网的过程,因此先了解请求一个网页时会发生什么;
1.Request请求:向服务器发送访问请求;
2.Response响应:服务器在接收到用户的请求后,会验证请求的有效性,然后向用户(客户端)发送响应的内容,客户端接收服务器响应的内容,将内容展示出来;

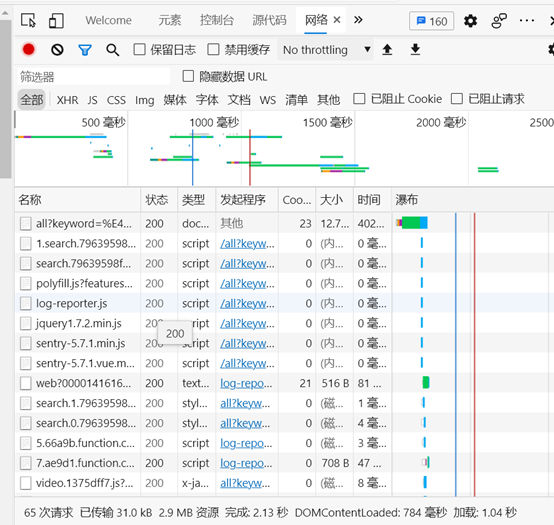
在F12的网络(Network)选项中,可以反映我们打开一次网页请求的情况;
每一条线代表一次请求,而这个线它会时不时增加,因为有交互的过程,就会产生新的请求;
想让请求停止发出,可按下左上角的小红圈;
每一个请求都有这么些东西:
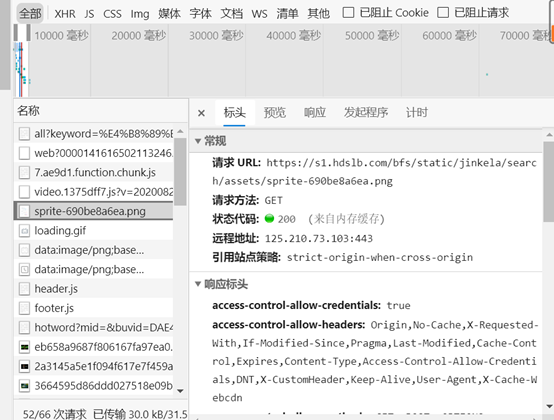
Response Headers响应标头:是我们发给服务器的,表示我们的适配条件;

例如这个表示我们使用的浏览器(这个Chrome暗示了我用了Google)
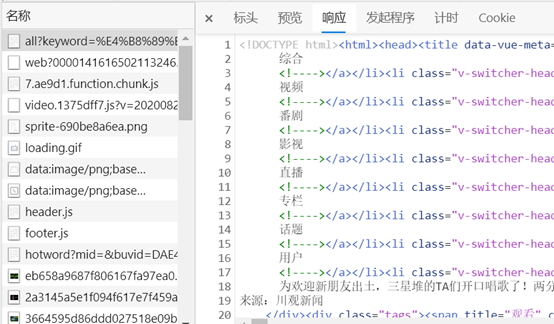
Response响应:服务器给我们的;
因此网络爬虫的模拟也需要经历发送请求,解析响应的过程;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号