
python | 豆瓣音乐排行榜数据爬取分析及可视化
python | 豆瓣音乐排行榜数据爬取分析及可视化
一、选题背景
其实简单的对信息的下载,我们用不到爬虫出马,简单的一个单机下载,就可以解决下载的问题,但是对于想要多个音乐(排行榜里),有一定规律的音乐进行下载我们就可以看到Python给我们带来的便利,其实也是一种对数据进行搜集的一种方式。希望通过简单的音乐排名的爬取可以让我们更加了解python,并且对音乐数据背后带来的信息进行分析。对于音乐爬取,这个不涉及到版权的问题,爬取上应该没有太多的限制,那我们要找的就是一个音乐排行榜进行爬取学习,分析。我这里找的是豆瓣音乐本周音乐人最热单曲排行榜。我们确定我们想要的数据对应的排行了,这样我们对于我们的目标就又近了一步。
二、设计方案
1、名称
豆瓣音乐排行榜数据爬取分析及可视化
2.内容与数据特征分析
爬取歌曲播放量的数据,分析各类数据之间的特征与关系
3.设计方案概述
通过访问网页源代码,爬取数据,分析html页面,标记需要的数据标签,对数据提取、处理、可视化、绘制图形、保存数据。
三、主题页面的结构特征分析
1、主题页面的结构与特征分析
数据来源:https://music.douban.com/chart
从下方网站页面截图可看出,页面结构大致分为三部分,我们需要爬取的数据基本在左下边,其他的可以不去考虑。
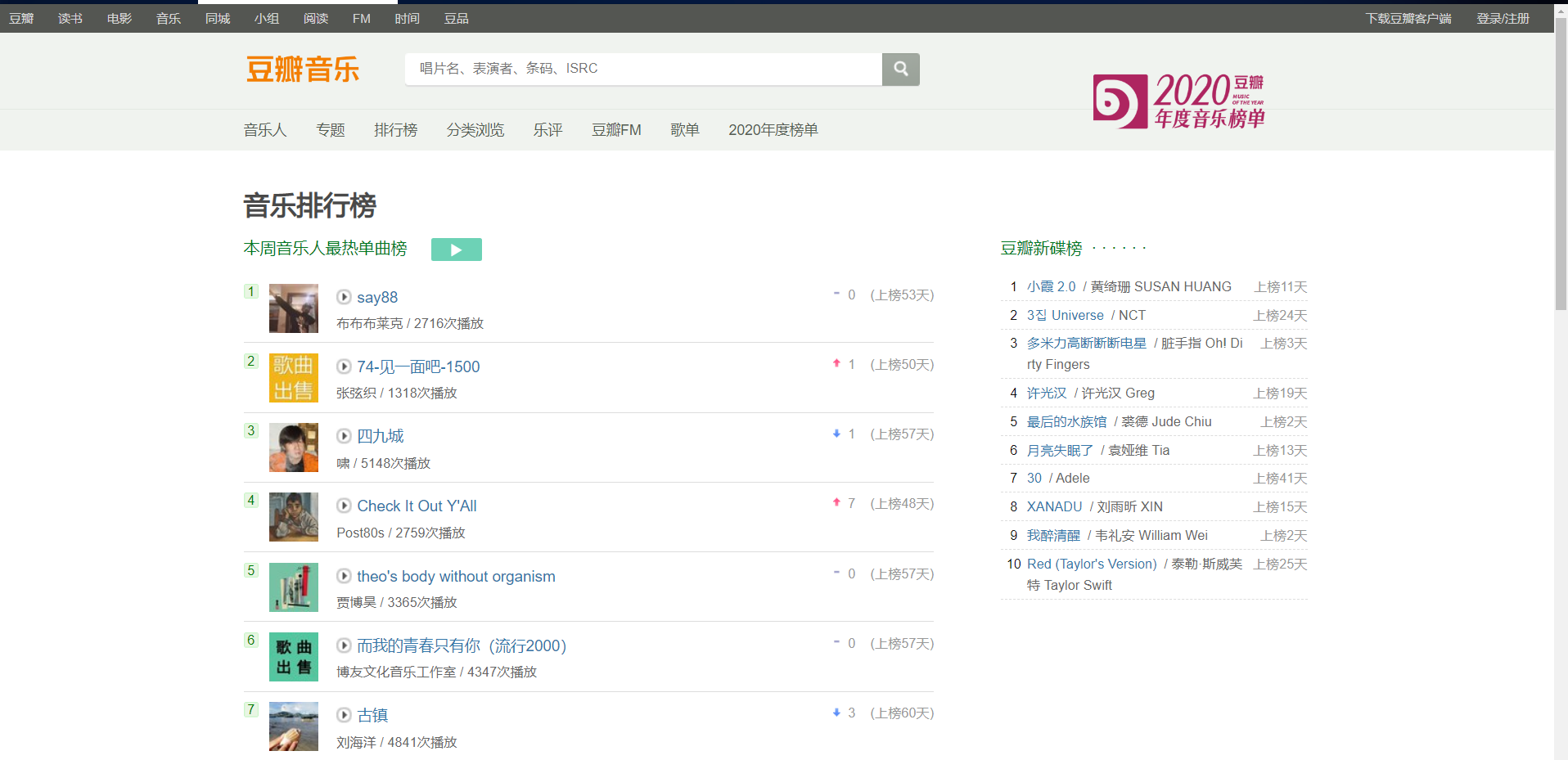
2、Htmls页面解析
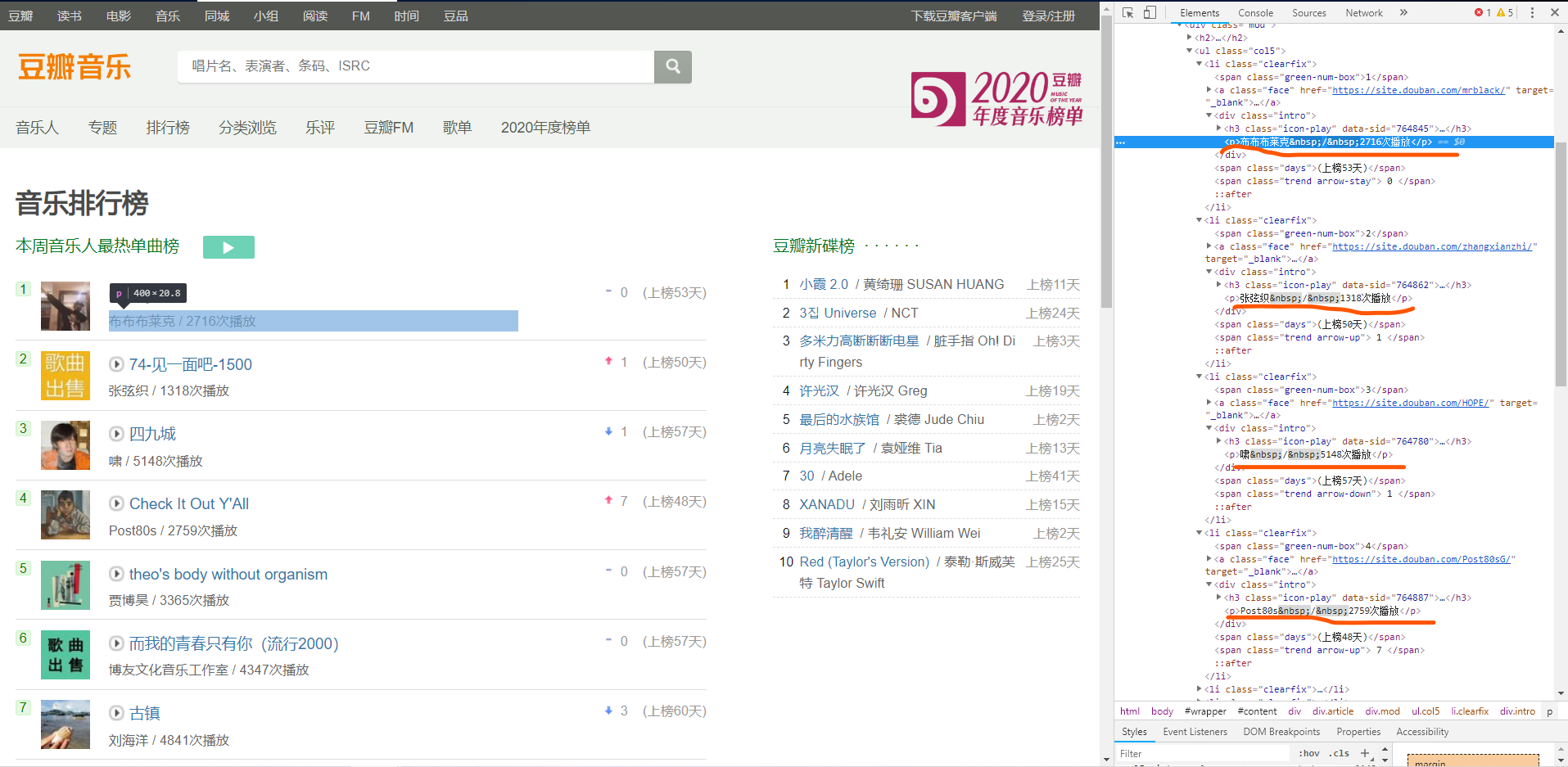
3.节点(标签)查找方法与遍历方法(必要时画出节点树结构)
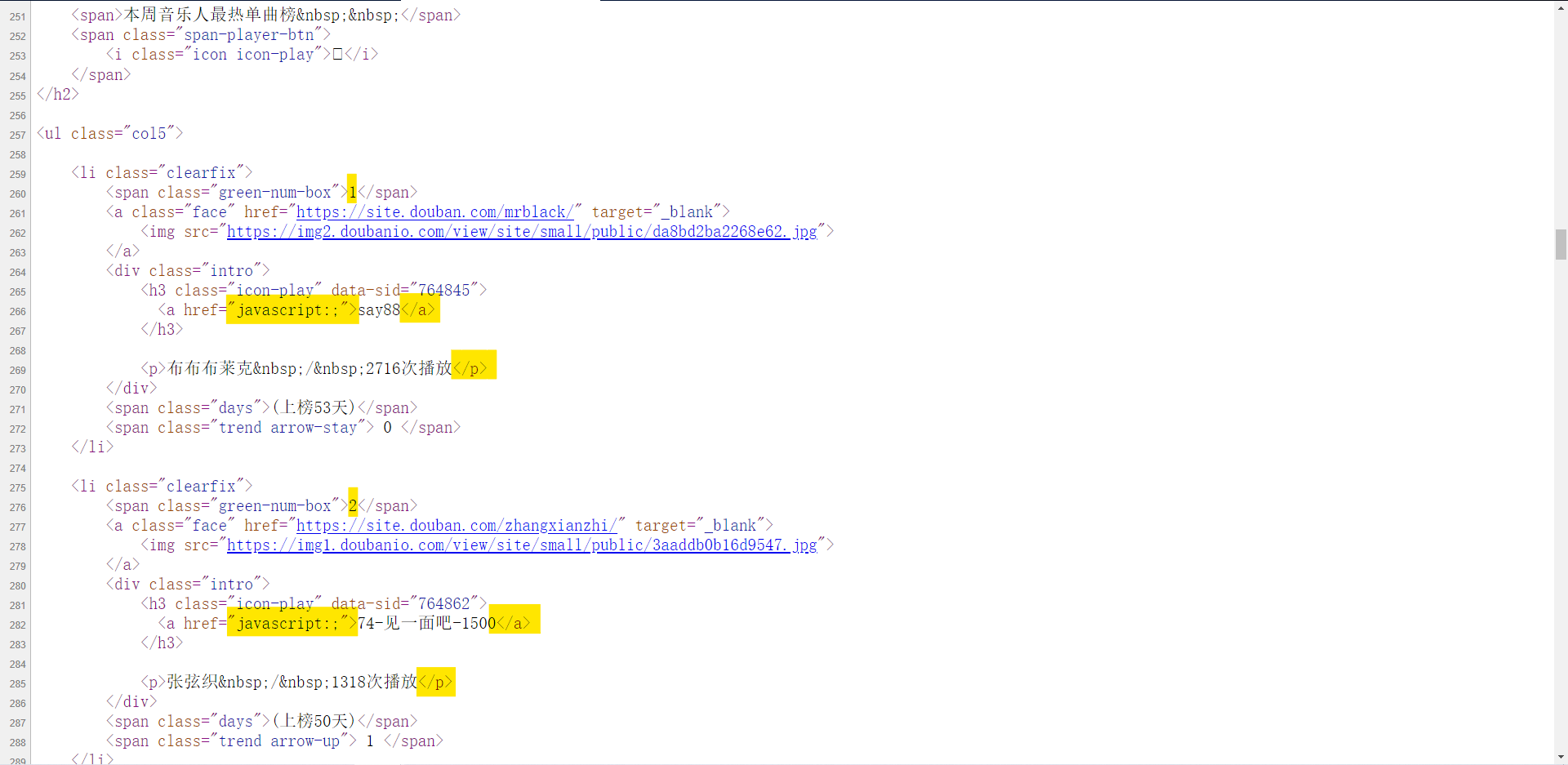
四、网络爬虫程序设计
1、数据爬取与采集
1 #-*- coding = utf-8 -*- 2 from bs4 import BeautifulSoup 3 #进行网页解析 4 5 import re 6 #进行文字匹配 7 8 import urllib.request,urllib.error 9 #制定URL,获取网页数据 10 11 import xlwt 12 #进行excel操作 13 14 import sqlite3 15 #进行SQLite数据库操作 16 17 18 #开始爬取数据 19 def getData(url): 20 datalist = [] 21 html = askURL(url) 22 soup = BeautifulSoup(html,"html.parser") 23 i=1 24 for item in soup.find_all('li', class_="clearfix"): 25 data = [] 26 item = str(item) 27 pm = i 28 i=i+1 29 data.append(pm) 30 findgm = re.compile(r'javascript:;">(.*?)</a>') 31 gm = re.findall(findgm, item)[0] 32 data.append(gm) 33 if i<=11: 34 findbfl = re.compile(r'\xa0/\xa0(.*?)</p>') 35 bfl = re.findall(findbfl, item)[0] 36 data.append(bfl) 37 else: 38 findbfl2 = re.compile(r'\xa0/\xa0(.*?)\n') 39 bfl2 = re.findall(findbfl2, item)[0] 40 data.append(bfl2) 41 datalist.append(data) 42 if i==16: 43 break 44 return datalist 45 46 47 48 def askURL(url): 49 head = { 50 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 51 } 52 request = urllib.request.Request(url, headers=head) 53 html = "" 54 try: 55 response = urllib.request.urlopen(request) 56 html = response.read().decode("utf-8") 57 except urllib.error.URLError as e: 58 if hasattr(e, "code"): 59 print(e.code) 60 61 if hasattr(e, "reason"): 62 print(e.reason) 63 64 return html 65 66 67 68 url = ("https://music.douban.com/chart") 69 html=askURL(url) 70 datalist = getData(url) 71 print(datalist) 72 savepath = ".\\豆瓣音乐本周音乐人最热单曲排行榜.xls" 73 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 74 75 #创建workbook对象 76 sheet = book.add_sheet('豆瓣音乐本周音乐人最热单曲排行榜',cell_overwrite_ok=True) 77 78 #创建工作表 79 #列名 80 col = ("排名","歌名","播放量") 81 82 #创建表头 83 for i in range(0,3): 84 sheet.write(0,i,col[i]) 85 86 #输入数据 87 for i in range(0,15): 88 #将播放量数据转化为纯数字格式 89 datalist[i][2] = datalist[i][2].replace('次播放','') 90 data = datalist[i] 91 for j in range(0,3): 92 sheet.write(i+1,j,data[j]) 93 94 book.save(savepath) 95 96 print('已输出表格!') 97 print("爬取完毕!")
2、读取数据
1 import pandas as pd 2 3 #导入数据 4 df_gm = pd.read_excel("豆瓣音乐本周音乐人最热单曲排行榜.xls",encoding='utf-8') 5 6 #显示数据表格 7 df_gm.head(15)
输出内容如下:
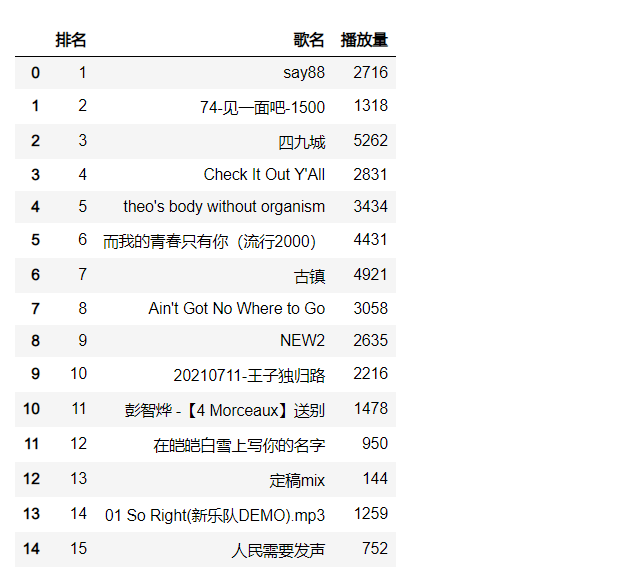
3、数据清洗和处理
(1)查看是否有重复行,有重复行返回True,没有重复行返回False
1 df_gm.duplicated()

(2)判断数据行中是否存在缺失值,有缺失值返回True,没有缺失值返回False
1 df_gm.isnull().any(axis=1)
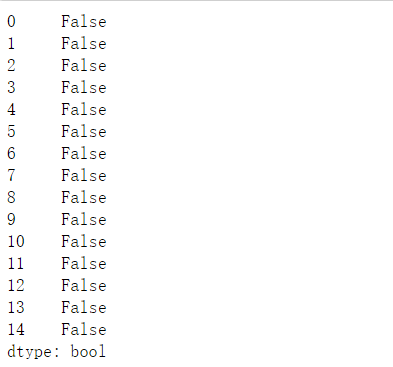
(3)查看是否有空值,有空值返回True,没有空值返回False
1 df_gm.isnull()

(4)查看是否存在异常值
1 df_gm.describe()
4、数据分析与可视化
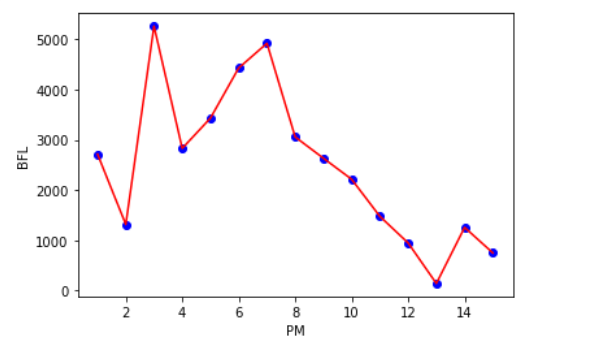
(1)散点折线图
1 #绘制散点折线图 2 import pandas as pd 3 import numpy as np 4 import matplotlib.pyplot as plt 5 df_gm = pd.read_excel("豆瓣音乐本周音乐人最热单曲排行榜.xls") 6 7 #散点 8 plt.scatter(df_gm.排名,df_gm.播放量,color='b') 9 10 #折线 11 plt.plot(df_gm.排名,df_gm.播放量,color='r') 12 13 #添加x轴标签和y轴标签 14 plt.xlabel('PM') 15 plt.ylabel('BFL') 16 17 plt.show()
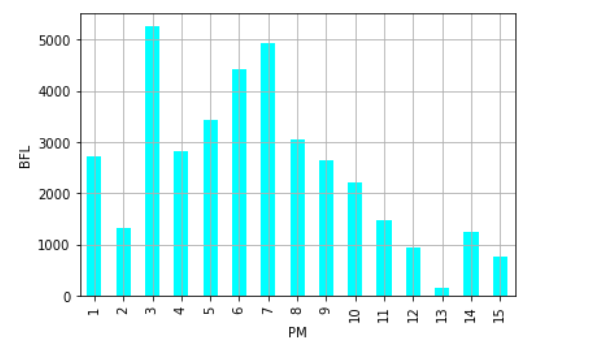
(2)数据柱形图
1 #绘制数据柱形图 2 import matplotlib.pyplot as plt 3 import pandas as pd 4 import numpy as np 5 6 kuake_df=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 7 data=np.array(kuake_df['播放量'][0:15]) 8 9 #添加x轴标签和y轴标签 10 plt.xlabel('PM') 11 plt.ylabel('BFL') 12 13 s = pd.Series(data, index) 14 s.plot(kind='bar',color='cyan') 15 16 #添加网格 17 plt.grid() 18 19 plt.show()
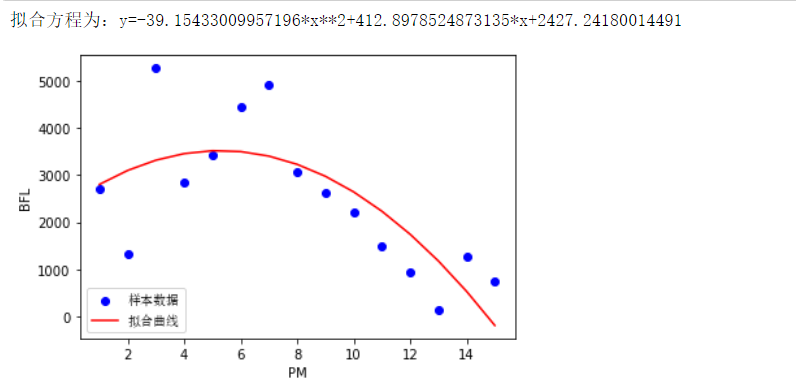
(3)线性回归方程
1 #线性回归方程 2 import pandas as pd 3 from sklearn import datasets 4 from sklearn.datasets import load_boston 5 from sklearn.linear_model import LinearRegression 6 df_gm=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 7 predict_model=LinearRegression() 8 X=df_gm[["排名"]] 9 Y=df_gm["播放量"] 10 predict_model.fit(X,Y) 11 np.set_printoptions(precision=3,suppress=True) 12 print("回归方程系数为{}".format( predict_model.coef_)) 13 print("回归方程截距:{0:2f}".format( predict_model.intercept_))

1 #绘制线性回归方程图 2 import matplotlib.pyplot as plt 3 import matplotlib 4 import numpy as np 5 import scipy.optimize as opt 6 df_gm=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 7 x0=np.array(df_gm['排名']) 8 y0=np.array(df_gm['播放量']) 9 def func(x,c0): 10 a,b,c=c0 11 return a*x**2+b*x+c 12 def errfc(c0,x,y): 13 return y-func(x,c0) 14 c0=[0,2,3] 15 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 16 a,b,c=c1 17 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 18 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 19 plt.plot(x0,y0,"ob",label="样本数据") 20 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 21 #添加x轴标签和y轴标签 22 plt.xlabel("PM") 23 plt.ylabel("BFL") 24 plt.legend(loc=3,prop=chinese) 25 plt.show()
5、完整代码
1 #-*- coding = utf-8 -*- 2 from bs4 import BeautifulSoup 3 #进行网页解析 4 5 import re 6 #进行文字匹配 7 8 import urllib.request,urllib.error 9 #制定URL,获取网页数据 10 11 import xlwt 12 #进行excel操作 13 14 import sqlite3 15 #进行SQLite数据库操作 16 17 18 #开始爬取数据 19 def getData(url): 20 datalist = [] 21 html = askURL(url) 22 soup = BeautifulSoup(html,"html.parser") 23 i=1 24 for item in soup.find_all('li', class_="clearfix"): 25 data = [] 26 item = str(item) 27 pm = i 28 i=i+1 29 data.append(pm) 30 findgm = re.compile(r'javascript:;">(.*?)</a>') 31 gm = re.findall(findgm, item)[0] 32 data.append(gm) 33 if i<=11: 34 findbfl = re.compile(r'\xa0/\xa0(.*?)</p>') 35 bfl = re.findall(findbfl, item)[0] 36 data.append(bfl) 37 else: 38 findbfl2 = re.compile(r'\xa0/\xa0(.*?)\n') 39 bfl2 = re.findall(findbfl2, item)[0] 40 data.append(bfl2) 41 datalist.append(data) 42 if i==16: 43 break 44 return datalist 45 46 47 48 def askURL(url): 49 head = { 50 "User-Agent": "Mozilla / 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome / 96.0.4664.110 Safari / 537.36" 51 } 52 request = urllib.request.Request(url, headers=head) 53 html = "" 54 try: 55 response = urllib.request.urlopen(request) 56 html = response.read().decode("utf-8") 57 except urllib.error.URLError as e: 58 if hasattr(e, "code"): 59 print(e.code) 60 61 if hasattr(e, "reason"): 62 print(e.reason) 63 64 return html 65 66 67 68 url = ("https://music.douban.com/chart") 69 html=askURL(url) 70 datalist = getData(url) 71 print(datalist) 72 savepath = ".\\豆瓣音乐本周音乐人最热单曲排行榜.xls" 73 book = xlwt.Workbook(encoding="utf-8",style_compression=0) 74 75 #创建workbook对象 76 sheet = book.add_sheet('豆瓣音乐本周音乐人最热单曲排行榜',cell_overwrite_ok=True) 77 78 #创建工作表 79 #列名 80 col = ("排名","歌名","播放量") 81 82 #创建表头 83 for i in range(0,3): 84 sheet.write(0,i,col[i]) 85 86 #输入数据 87 for i in range(0,15): 88 #将播放量数据转化为纯数字格式 89 datalist[i][2] = datalist[i][2].replace('次播放','') 90 data = datalist[i] 91 for j in range(0,3): 92 sheet.write(i+1,j,data[j]) 93 94 book.save(savepath) 95 96 print('已输出表格!') 97 98 print("爬取完毕!") 99 100 101 102 import pandas as pd 103 104 #导入数据 105 df_gm = pd.read_excel("豆瓣音乐本周音乐人最热单曲排行榜.xls",encoding='utf-8') 106 107 #显示数据表格 108 df_gm.head(15) 109 110 #查看是否有重复行,有重复行返回True,没有重复行返回False 111 df_gm.duplicated() 112 113 #判断数据行中书是否存在缺失值,有缺失值返回True,没有缺失值返回False 114 df_gm.isnull().any(axis=1) 115 116 # 查看是否有空值,有空值返回True,没有空值返回False 117 df_gm.isnull() 118 119 #查看是否存在异常值 120 df_gm.describe() 121 122 123 124 #绘制散点折线图 125 import pandas as pd 126 import numpy as np 127 import matplotlib.pyplot as plt 128 129 df_gm = pd.read_excel("豆瓣音乐本周音乐人最热单曲排行榜.xls") 130 131 #散点 132 plt.scatter(df_gm.排名,df_gm.播放量,color='b') 133 134 #折线 135 plt.plot(df_gm.排名,df_gm.播放量,color='r') 136 137 #添加x轴标签和y轴标签 138 plt.xlabel('PM') 139 plt.ylabel('BFL') 140 141 plt.show() 142 143 144 145 #绘制数据柱形图 146 import pandas as pd 147 import numpy as np 148 import matplotlib.pyplot as plt 149 150 kuake_df=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 151 data=np.array(kuake_df['播放量'][0:15]) 152 153 #添加x轴标签和y轴标签 154 plt.xlabel('PM') 155 plt.ylabel('BFL') 156 157 s = pd.Series(data, index) 158 s.plot(kind='bar',color='cyan') 159 160 #添加网格 161 plt.grid() 162 163 plt.show() 164 165 166 167 #线性回归方程 168 import pandas as pd 169 from sklearn import datasets 170 from sklearn.datasets import load_boston 171 from sklearn.linear_model import LinearRegression 172 173 df_gm=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 174 predict_model=LinearRegression() 175 176 #设定X和Y变量 177 X=df_gm[["排名"]] 178 Y=df_gm["播放量"] 179 predict_model.fit(X,Y) 180 np.set_printoptions(precision=3,suppress=True) 181 print("回归方程系数为{}".format( predict_model.coef_)) 182 print("回归方程截距:{0:2f}".format( predict_model.intercept_)) 183 184 185 186 #绘制线性回归方程图 187 import matplotlib.pyplot as plt 188 import matplotlib 189 import numpy as np 190 import scipy.optimize as opt 191 192 df_gm=pd.read_excel(r'C:\Users\20832\豆瓣音乐本周音乐人最热单曲排行榜.xls') 193 194 x0=np.array(df_gm['排名']) 195 y0=np.array(df_gm['播放量']) 196 def func(x,c0): 197 a,b,c=c0 198 return a*x**2+b*x+c 199 def errfc(c0,x,y): 200 return y-func(x,c0) 201 202 c0=[0,2,3] 203 c1=opt.leastsq(errfc,c0,args=(x0,y0))[0] 204 a,b,c=c1 205 print(f"拟合方程为:y={a}*x**2+{b}*x+{c}") 206 207 chinese=matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simsun.ttc') 208 plt.plot(x0,y0,"ob",label="样本数据") 209 plt.plot(x0,func(x0,c1),"r",label="拟合曲线") 210 211 #添加x轴标签和y轴标签 212 plt.xlabel("PM") 213 plt.ylabel("BFL") 214 215 plt.legend(loc=3,prop=chinese) 216 plt.show()
五、总结
1、一步步分析,在进行爬虫爬取的时候要注意,有时候的参数是可以省略的,因此在构造请求信息的时候就可以省略参数的信息。
2、通过这次的期末设计项目学习,我深深的感觉到自己不论是知识层面上还是动手实践能力上都很欠缺,学无止境。虽然本学期即将结束,但我们的学习永远不会有终点。希望通过本次总结,我可以更好的认清自己的优缺点,取长补短,在今后的学习中不断提升自己的能力!
