

第二次作业
学习笔记
当初在课堂学的时候,虽然有老师解惑,但终究自己基础不足,上课又有时间限制,所以大概只能理解一半,通过后面复习,基本将之前还有疑惑的问题解决了,虽然其中一些公式推导的过程还比较难算,而且部分概念容易混淆。这篇学习笔记主要是为了记录一下自己觉得需要掌握记住的,或者是自己没有完全理解吃透的
第一章模式识别基本概念
-
模式识别分为“分类”和“回归”
-
分类输出量是离散的类别表达,即输出待识别模式所属的类别
-
回归输出量是连续的信号表达(回归值),输出量可以是多个维度
-
回归是分类的基础:离散的类别值是由回归值做判别决策得到的
-
模式是关于已有知识的一种表达方式,即函数f(x)

-
-
模式识别:根据已有的知识的表达,针对待识别模式,判别决策其所属的类别或者预测其对应的回归值。本质上是一种推理过程
- 模式:特征提取+回归器+判别函数
- 特征提取:从原始输入数据提取更有效的信息
- 回归器:将特征映射到回归值
- 判别函数有sign:二类分类;max:多类分类,取最大的回归值所在维度的类别
-
模型通过机器学习方法获得
- 目标函数,也称代价函数或损失函数
- 在有无数个解的情况下,需要额外添加一个标准,通过优化该标准来确定一个近似解,即目标函数
- 优化算法:最大化或最小化目标函数的技术
-
学习方式
-
监督式学习
- 训练样本和输出真值都给定的机器学习算法
- 最常见的学习方式
- 通常使用最小化训练误差作为目标函数进行优化
- 举例:
-
无监督式学习
- 只给定训练样本、没有给输出真值情况下的机器学习算法
- 无监督式学习算法的难度远高于监督式算法
- 根据训练样本之间的相似程度来进行决策
- 举例:聚类、图像分割
-
半监督式学习
- 既有标注的训练样本、又有未标注的训练样本情况下的学习算法
- 看作有约束条件的无监督式学习问题:标注过的训练样本作为约束条件
- 举例:网络流数据
-
-
泛化能力,通俗来讲就是指学习到的模型对未知数据的预测能力。通常通过测试误差来评价学习方法的泛化能力
-
过拟合:模型训练阶段表现很好,但是测试阶段表现很差,模型过于拟合训练数据
-
提高泛化能力
-
模型选择,选取合适的多项式阶数M
-
正则化,在目标函数中加入关于参数的正则项,超参数:正则系数λ
\[\frac{1}{2}\sum_{n=1}^N(y(x_n,w)-t_n)^2+\frac{\lambda}{2}||w||_2^2 \] -
调参:几乎每个机器学习算法都有超参数,调参需要依据泛化误差,但不能基于测试集,因此从训练集中分出一个验证集,基于验证集调参
-
-
-
评估方法
- 留出法,将数据集随机分成训练集和测试集
- K折交叉验证,将训练集分割成K个子集,从中选取单个子集作为测试集,其他K-1为训练集,重复K次,每个子集被测试一次,将K次的评估值取平均,作为最终评估结果
- 留一验证:取数据集中的一个样本做测试集,每个样本测试一次,取平均
-
性能指标
-
准确率(正确率)=所有预测正确的样本/总的样本 (TP+TN)/总
- 如果阳性和阴性数量失衡,识别不好
-
-
精度= 将正类预测为正类 / 所有预测为正类 TP/(TP+FP)
-
召回率 = 将正类预测为正类 / 所有正真的正类 TP/(TP+FN)
-
混淆矩阵:列是预测值,行是真值,对角线的值越大性能越好
-
PR曲线,横轴召回率,纵轴精度,曲线越往右上凸性能越好
-
ROC曲线:接收者操作特征(receiver operating characteristic)
-
roc曲线上每个点反映着对同一信号刺激的感受性。
-
纵轴:真正类率(true postive rate TPR),也就是召回率
-
横轴:假正类率(false postive rate FPR),阴性中被错误识别为阳的
理想目标:TPR=1,FPR=0,即图中(0,1)点,此时ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
-
-
ROC对各类样本分布不敏感,PR曲线对各类样本分布敏感
-
-
AUG曲线:Area Under Curve被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。
第二章 基于距离的分类器
-
MED分类器 最小欧式距离分类器Minimum Euclidean Distance Classifier
-
距离:欧式距离
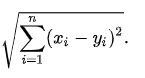
-
比较方法,那个点到两个类的欧式距离更小就属于哪个类
-
最小距离分类法原理简单,容易理解,计算速度快,但是因为其只考虑每一类样本的均值,而不用管类别内部的方差(每一类样本的分布),也不用考虑类别之间的协方差(类别和类别之间的相关关系),所以分类精度不高,因此,一般不用它作为我们分类对精度有高要求的分类。
-
-
特征白化
- 目的:去除特征之间的相关性:解耦\(W_2\);对特征进行尺度变化:白化\(W_1\),使每维特征的方差相等\[W=w_2w_1 \]
- 目的:去除特征之间的相关性:解耦\(W_2\);对特征进行尺度变化:白化\(W_1\),使每维特征的方差相等
-
MICD分类器 最小类内距离分类器Minimum Intra-class Distance Classifier
-
距离:马氏距离
-
比较方法,那个点到两个类的马式距离更小就属于哪个类
-
缺点,马氏距离会选择方差较大的那一个类
-

第三章贝叶斯决策与学习
-
MAP分类器 最大后验概率分类器Maximum posterior probability Classifier
- 后验概率 :
- \(P(c_i)\)类的先验概率
- \(P(x|C_i)\)观测似然概率
- \(P(x)=\sum_jP(x|c_j)P(c_j)\)所有类样本x的边缘概率
- 比较方法,属于哪个类的后验概率比较大就属于哪个
- 后验概率 :
-
贝叶斯分类器
-
贝叶斯分类器在MAP分类器基础上,加入决策风险因素
-
选择方法,选择决策风险最小的类
-
损失期望\(R(\alpha_i|x)=\sum_{j}\lambda_{ij}P(C_j|x)\)
-
\(\lambda_{ij}\)指样本真值为j,判别为i的损失
-
在决策边界小于阈值t的决策都会被拒绝
-
-
后验概率需要知道先验概率和观测似然概率概率,可通过机器学习算法得到
-
监督式学习,参数化方法
-
最大似然估计
- 待学习的概率密度函数记作\(P(X|\theta) \theta\)是待学习的参数
- 联合概率密度\(p(x_1,x_2...x_n|\theta)=\prod_{n=1}^N{p(x_n|\theta)}\)该函数称为似然函数
- 为最大化似然函数,求关于参数p的偏导,令偏导为0
- 先验概率的最大似然估计就是该训练样本出现的频率
- 高斯分布均值和方差的最大似然估计等于样本的均值和协方差
- 均值是无偏估计,协方差是有偏估计
-
贝叶斯估计:给定参数𝜃分布的先验概率以及训练样本,估计参数θ分布的后验概率
-
该概率分布的先验概率已知:𝑝(𝜃)

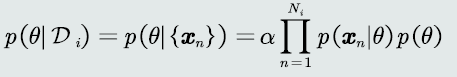
-
贝叶斯估计具备不断学习的能力。
-
它允许最初的、基于少量训练样本的、不太准的估计。
-
随着训练样本的不断增加,可以串行的不断修正参数的估计值,从而达到该参数的期望真值。
对于贝叶斯估计还不是很理解,感觉晕晕的。。。课件的例题可以理解,但是其他理论的就说不上来
-
-
-
无参数估计:三个估计概率密度p(x)基于k/NV
-
KNN估计
- 给定x,找到其对应的区域R使其包括k个训练样本
- 第k个训练样本的距离为\(d_k(x)\)则体积为\(2d_k(x)\)
- 概率密度估计表达为\(p(x)\approx \frac {k}{2d_k(x)}\)
- 训练样本N越大,k越大,概率估计的越准确
- 优点可以自适应确定x相关的区域R的范围
- 缺点:不是连续函数,不是真正的概率密度表达,概率密度函数积分是∞而不是1,要存所有样本,区域R由第k个决定,易受噪声影响
-
直方图估计
- R的确定:
- 将特征空间分为m个各自,每个格子为一个R
- 平均分格子大小,每个格子体积设V=h固定
- 相邻格子不重叠
- 每个格子里样本不固定
- 优点,固定格子,减少噪声污染,不用存样本
- 缺点,x落在相邻格子交界处,意味着当前格子不是以模式x为中心,估计不准确;固定区域R,缺乏自适应能力,导致过于尖锐或平滑
- R的确定:
-
核密度估计
-
区域R:以任意待估计模式x为中心、固定带宽h,确定一个区域R
-
统计k

- 优点:类似于knn可以自适应;基于所有样本,不受噪音影响;如果核函数连续,概率密度也连续,核密度比直方图更平滑
- 缺点,要存所有样本
- 带宽h决定了估计概率的平滑程度,选取原则,是有更好的泛化能力
-
-
线性判据

- w的作用:决定了决策边界的方向,\(w_0\)的作用:决定决策边界的偏移量,使其能够满足两个类输出值分别为正负

- 从解域中找到最优解:设计目标函数,加入约束条件

- 感知机算法
- 预处理:在几何上,通过在特征空间上增加一个维度,使决策边界过原点,翻转\(C_2\)类样本使所有样本在平面同一侧

-目标函数:思想:被错误分类的样本最少
- 求偏导

- 梯度下降法

- 预处理:在几何上,通过在特征空间上增加一个维度,使决策边界过原点,翻转\(C_2\)类样本使所有样本在平面同一侧
- 并行感知机

- 过程:
- 初始化参数,a0,步长,阈值
- 迭代更新:基于当前梯度更新a,更新集合\(Y_k\)
- 停止迭代:所有训练样本的输出都大于0,或更新值小于阈值
- 过程:
- 串行感知机:训练样本一个一个给出
- 思想:当前样本被错误分类的程度最小
- 目标函数:如果当前训练样本被错误分类,最小化器输出值取反
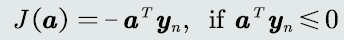

- 收敛性:如果训练样本线性可分,感知机则理论上收敛于一个解
- 当样本位于决策边界时,对样本决策有很大的不确定性

- Fisher线性判据
- 可以看作把原空间各点投影到新的一维空间\(y=w^Tx+w_0\)
- 投影最佳标准:投影后使不同类别样本分布的类间差距尽可能大,同时使类内样本分布的离散程度尽快拿小



- 求解:对w求偏导,设偏导为0,\(f_FLD(x)=w^T x+w_0=(\mu_1 -\mu_2)^T S_w ^{-1}(x-\mu)\)
- 完整过程

- 支持向量机
- 思想:使两个类中与决策边界孫的训练样本到决策边界之间的间隔最大
- 支持向量:就是两个离决策边界最近的训练样本
- 目标函数

- 拉格朗日乘数法
- 常用来解决条件优化问题
- 思路




- 拉格朗日对偶问题
- 支持向量机学习算法
待补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号