

一、 前言
数据挖掘(DM data mining)是从大量的,不完全的,有噪声的,模糊的,随机的数据中,提取隐含在其中的,人们事先不知道的,但又是潜在的有用的信息和知识的过程。而我们的图书馆的数据库中积累了大量的读者借阅历史数据,这些数据中隐藏着大量重要信息,利用这些信息我们可以挖掘出读者对图书资源的借阅偏好模式。于是我们便利用微软SQL SERVER 2005中的数据挖掘关联规则模块建立一个在线书目推荐服务系统,以提高图书馆的服务水平。
二、 问题分析
关联规则是描述数据库中数据项之间所存在的关系的规则,即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。在SQL SERVER 2005 中的关联规则用的是优先关联族算法,即FP-树频集算法[HPY00]。该算法在从大数据量中寻找频繁项集非常有效,在效率上较之Apriori算法有巨大的提高。具体运作时分两步分析:第一步通过已过精确计算的表达式寻找出项集;第二步是基于频繁项集产生规则。第二步需要的时间会明显少于第一步。下面我们了解下该算法涉及的一些关键指标:
|
指标名 |
含义 |
|
支持度 (Support) |
支持度对项集形成有影响。 用于描述项集出现频度的指标,最低支持度(Minimum_Support)意为只对达到指定频度的项集感兴趣,如果指定最低支持度为小于1的值则微软关联规则认为你只对频度达到指定百分比的项集感兴趣。比如0.03表示项集支持度只有占到总项集数的3%才能形成项集。最大支持度(Maximum_Support)则指定了项集出现频度的上限,超过上限的项集也不是我们感兴趣的。 |
|
概率 (Probability) |
概率对规则的形成有影响。 一条规则中有A的条件下会有B(A=>B)的概率是指 Probability (A => B) = Probability (B|A) = Support (A, B)/ Support (A) 指定一定的最低概率值就可以限制形成的规则数。 |
|
重要性 (Importance) |
重要性对项集和规则形成均有影响。 它的定义如下: Importance (A => B) = log (p(B|A)/p(B|not A)) 从定义知如果该值为0表示A和B没有关联性,正值表示一旦拥有A则再拥有B的概率会增长,负值表示一旦拥有A则再拥有B的概率会降低。 |
三、 数据准备
我们收集了兰州商学院图书馆2002年到2005年的读者借阅数据,数据库具体关系如下:
“一次借阅标识”意义在于形成用户借阅的项集,举例说:甲乙(单次借阅标识分别是1和2)两人一次都借了3本书丙(单次借阅标识分别是3)一次借了两本,得到如下表所示记录:
|
借阅历史表 |
||
|
借阅流水号(主键) |
单次借阅标识(外键) |
书名 |
|
1 |
1 |
C#编程事件 |
|
2 |
1 |
.Net核心编程 |
|
3 |
1 |
.Net网络编程 |
|
4 |
2 |
ASP.NET高级编程 |
|
5 |
2 |
.Net核心编程 |
|
6 |
2 |
.Net网络编程 |
|
7 |
3 |
Windows API 速查手册 |
|
8 |
3 |
C#编程事件 |
单次借阅标识表 |
|
|
单次借阅标识(主键) |
|
|
1 |
|
|
2 |
|
|
3 |
如此我们便只要通过“单次借阅标识”即可区分不同用户的单次借阅。因为在每次借阅书籍时会先在单次借阅标识表中插入自增标识码,当借阅历史表增加新记录时便使用刚插入的自增标识码作为“单次借阅标识”,这样两张表便形成一对多的关系。之所以要有上面两张表,是因为SQL SERVER 2005在训练关联规则模型时要有事例表和嵌套表。所谓事例表即存放鉴定一次事务的标识信息的表,用户完成他的一次借阅(当然可以不止借一本)就是一次事务,一次事务只用一个标识。我们设定单次借阅标识字段为自增字段就恰恰满足这点,所以单次借阅标识表就成了我们的事例表。嵌套表即为事例表中事务的具体细节内容表,其间用“单次借阅标识”来将各条记录形成项集。
四、 开发步骤
我们用“SQL Server Business Intelligence Development Studio”建立书目推荐服务程序,具体步骤如下:
一、训练模型
1. 选择商业智能项目中Analysis Services项目,建立BookHistoryAS项目
2. 建立数据源,指定我们的SQL Server 2005实例为数据源,并指定初始数据库为我们存放借阅历史数据的数据库。
3. 建立数据源视图,将上面提及的“借阅历史”表“单次借阅标识”表都选择进来。
4. 建立挖掘结构
① 选择“从现有关系数据库或数据仓库”中训练和开发模型。
② 选择“Microsoft 关联规则”挖掘模型。
③ 指定“单次借阅标识”表为事例表,“借阅历史”表为嵌套表。
④ 按图(一)设定键列和可预测列。
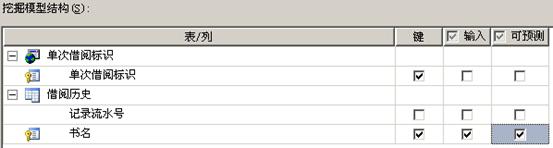
图(一)
之所以设定书名为可预测列是为后面的关联预测作准备。
⑤ 为自己设定的规则命名。
5.设置关联规则算法的参数。具体参数如图(二),各参数含义前面已做解释,在此不赘述。值得说明的是因为我们的借阅历史和书目数据量都较大,我们将最大项集计数(MAXIMUM_ITEMSET_COUNT)设置得大些400000,以免达到上限而无法生成任何有效规则。因为我校规定的单次借阅书籍上限是10本,所以将最大项集容量(MAXIMUM_ITEMSET_SIZE)设置成10,我们认为至少有两次相同的项集出现才生成规则,所以设置最小支持度(MINIMUM_SUPPORT)为2。

图(二)
6.右键单击刚建立好的挖掘模型选“处理…”,开始训练模型。
7.处理完毕后打开“挖掘模型查看器”选项卡,下面会出现“项集”、“规则”、“依赖关系网络”三个子选项卡。“项集”中会列出各项集支持度,大小和各项集包含的具体项; “规则”中则显示规则的预测概率、重要性和具体内容,我们通过查看该图可以了解训练出的规则的具体形式;“依赖关系网络”则将规则用图形化的方法表示出来,非常直观,如图(三):
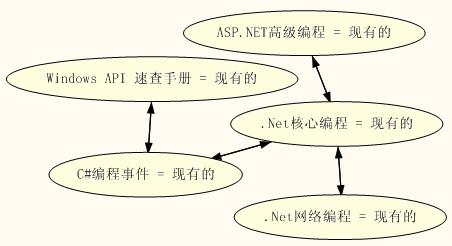
图(三)
8.打开挖掘模型查看器,选择查看器下拉列表中的“Microsoft 挖掘内容查看器”。找到NODE_DESCRIPTION字段查看第一条记录里的模型摘要信息,该信息对进一步调整参数有帮助。特别是里面的规则数(RULE_COUNT)如果偏少则对预测很不利,可以适当降低概率参数和重要度参数。调整参数后重复1-7步直到训练出满意的模型。
9.给建立的挖掘模型添加一个角色并将只读权限赋给EveryOne成员,如果不赋权则当ASP.NET程序访问数据库时会提示读取权限不足。
二、建立在线查询服务
实现思路:我们建立两个ASP.NET页面,第一个是搜索页面负责从数据库模糊匹配用户输入的关键字提取相关书籍。当用户选择一本书后转到关联预测的页面,这个页面负责列出与被选书籍最相关的5本推荐书目,如果没有相关匹配规则则列出最受欢迎的5本书。如下是主要开发步骤:
第一个页面只是简单的数据查询而已,我们略去具体代码,看到实现效果如图(四):

图(四)
点击查看后会传递该书书名到子页面,子页面实现效果如图(五):

图(五)
子页面核心预测代码如下:
 //创建数据库连接对象 Microsoft.AnalysisServices.AdomdClient.AdomdConnection con = new Microsoft.AnalysisServices.AdomdClient.AdomdConnection("Data Source=ELFSERVER;Catalog=booklib; Integrated Security=SSPI"); con.Open(); string Sql = "SELECT FLATTENED TopCount(Predict([Book Name],INCLUDE_STATISTICS,EXCLUSIVE),$AdjustedProbability,5) "//我们在此使用调整后的概率($AdjustedProbability),因为如果几乎所有人在借了A书后又借B书,那么推荐B书的意义就不大了,调整后的概率会降低上面提及的B书的概率,从而给出更有意义的建议。 + "FROM [AllInIt]"//AllInIt是自己建立的挖掘名称 + "PREDICTION JOIN (SELECT (" + "SELECT '" + Request.QueryString["BookName"] + "' as [书名]"//获取从前页传递过来的BookName参数 + ") as [Book Name])" + "as T on [AllInIt].[Book Name].[书名] = T.[Book Name].[书名]"; string strCommand = sql; Microsoft.AnalysisServices.AdomdClient.AdomdCommand cmd = (Microsoft.AnalysisServices.AdomdClient.AdomdCommand)con.CreateCommand(); cmd.CommandText = strCommand; Microsoft.AnalysisServices.AdomdClient.AdomdDataAdapter da = new Microsoft.AnalysisServices.AdomdClient.AdomdDataAdapter(cmd); DataSet ds = new DataSet(); ds.RemotingFormat = SerializationFormat.Binary; da.Fill(ds);//将获取的数据绑定到GridView控件 this.GridView1.DataSource = ds.Tables[0].DefaultView; this.GridView1.DataBind(); con.Close();
//创建数据库连接对象 Microsoft.AnalysisServices.AdomdClient.AdomdConnection con = new Microsoft.AnalysisServices.AdomdClient.AdomdConnection("Data Source=ELFSERVER;Catalog=booklib; Integrated Security=SSPI"); con.Open(); string Sql = "SELECT FLATTENED TopCount(Predict([Book Name],INCLUDE_STATISTICS,EXCLUSIVE),$AdjustedProbability,5) "//我们在此使用调整后的概率($AdjustedProbability),因为如果几乎所有人在借了A书后又借B书,那么推荐B书的意义就不大了,调整后的概率会降低上面提及的B书的概率,从而给出更有意义的建议。 + "FROM [AllInIt]"//AllInIt是自己建立的挖掘名称 + "PREDICTION JOIN (SELECT (" + "SELECT '" + Request.QueryString["BookName"] + "' as [书名]"//获取从前页传递过来的BookName参数 + ") as [Book Name])" + "as T on [AllInIt].[Book Name].[书名] = T.[Book Name].[书名]"; string strCommand = sql; Microsoft.AnalysisServices.AdomdClient.AdomdCommand cmd = (Microsoft.AnalysisServices.AdomdClient.AdomdCommand)con.CreateCommand(); cmd.CommandText = strCommand; Microsoft.AnalysisServices.AdomdClient.AdomdDataAdapter da = new Microsoft.AnalysisServices.AdomdClient.AdomdDataAdapter(cmd); DataSet ds = new DataSet(); ds.RemotingFormat = SerializationFormat.Binary; da.Fill(ds);//将获取的数据绑定到GridView控件 this.GridView1.DataSource = ds.Tables[0].DefaultView; this.GridView1.DataBind(); con.Close();
五、 结束语
数据挖掘是数据库技术发展的结果,目前己经成功地应用于各个领域,但大部分集中在银行、金融、大型商业数据库等赢利性领域中,在高校、政府等一些非赢利性机构中应用很少,本文对关联规则的数据挖掘在高校图书馆系统中的应用进行了探索,并用SQL Server Business Intelligence Development Studio 和ASP.NET实现了基本功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号