


面试题以及一些问题概述
2024/2/27
1 数据库三大范式是什么 (关系型数据库设计表规范)
用于规范化数据库中的数据结构,提高数据的一致性和减少数据冗余的。
1. 第一范式(1NF):要求数据库表中的每个字段都是原子性的,不可再分。
也就是说,每个字段中的数据不能包含多个值或多个属性。如果一个字段中包含了多个值,就需要将其拆分成多个独立的字段。
2. 第二范式(2NF):在满足第一范式的基础上,要求数据库表中的非主键字段必须完全依赖于主键。 (例如图片表,图片的……)
也就是说,每个非主键字段必须完全依赖于主键,而不能依赖于其他非主键字段。
如果存在部分依赖或传递依赖的情况,就需要将其拆分成多个独立的表。
3. 第三范式(3NF):在满足第二范式的基础上,要求数据库表中的非主键字段之间不能存在传递依赖关系。
(一对多的观念)
依赖关系(如果我们通过某张表,知晓与该表没有关系,但是与第三张表有关的信息,叫做传递依赖)----不能间接相关
也就是说,每个非主键字段之间应该是互相独立的,不能通过其他非主键字段推导出来。如果存在传递依赖的情况,就需要将其拆分成多个独立的表。
2 mysql有哪些索引类型,分别有什么作用
Mysql索引 可以从 存储方式,逻辑角度,实际使用角度进行分类
存储方式分为 B-树索引和HASH索引两类 (了解)
B-树索引可以进行全键值、键值范围和键值前缀查询,也可以对查询结果进行 ORDER BY 排序。但 B-树索引必须遵循左边前缀原则,要考虑以下几点约束:
查询必须从索引的最左边的列开始。
哈希索引
HASH 索引不是基于树形的数据结构查找数据,而是根据索引列对应的哈希值的方法获取表的记录行
逻辑区分
-主键索引(聚簇索引)---》主键,表不建立主键,也会有个隐藏字段是主键,是主键索引,mysql是基于主键索引构建的b+树,不能没有主键,如果按主键搜索,速度是最快的---》一定会有主键索引
-辅助索引(普通索引)-->咱们给某个字段加索引,django index=True,通过该字段查询,会提高速度,如果字段 变化小(性别,年龄),不要建立普通索引
-CREATE INDEX index_id ON tb_student(id);
-唯一索引(unique)
-不是为了提高访问速度,而是为了避免数据出现重复
-唯一索引通常使用 UNIQUE 关键字
-CREATE UNIQUE INDEX index_id ON tb_student(id);
-组合索引(联合索引)
-django 中:
class Meta:
index_together=(name,course)
-CREATE INDEX index_name ON table_name (column1, column2, column3);
-全文索引-->基本不用---》
全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。
在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
全文索引允许在索引列中插入重复值和空值。
不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
创建全文索引使用 FULLTEXT 关键字
3 事务的特性和隔离级别 (事务是为了提高 mysql 并发操作性能)
事务的四大特性:
原子性(Atomicity):事务是最小的工作单元,不可再分。 与第一范式不一样, 另指 全做/全不做
一致性(Consistency):事务必须保证多条DML语句同时成功或同时失败。
隔离性(Isolation):一个事务不会影响其他事务的运行,互不干扰。事务之间隔离大小取决于隔离级别。
持久性(Durability):事务一旦提交成功,它对数据库中数据的改变就是永久性的
-----------------conn.commit
第一级别:读未提交 (Read Uncommited)
对方事务还未提交,但当前事务可以读取到对方未提交的数据
读未提交存在脏读现象:表示读到了脏的数据,因为还未提交到硬盘,数据及其不稳定。(所有数据库都是从第二级别起步,第一级别太低)
第二级别:读已提交 (Read Commited)
当前事务只能读取到对方事务已经提交的数据。由于未提交的读不到,则解决了脏读现象。
存在的问题:不可重复读,即可能每次读的数据不一样,做不到数据从头到尾查的数据是一样的
第三级别:可重复读 (Repetable Read) 解决脏读,不可重复读, 存在幻读
开始读取数据时(事务开启)不再允许修改
第四级别: 序列化读 (Serializable) (串行化)
解决了所有问题 (因为串行执行,不会存在同时执行)
但是效率低,牺牲 并发性,需要事务排队
mysql是个cs架构的软件,允许客户顿或者同一个客户端同时对数据进行操作
同时对数据进行操作,就会出现并发安全
mysql 为了保证效率,,又要保证安全,, 才有事务隔离级别
-------------------------------------------------------------------------------------------------------------------------------mySQL,,,postgreSQL,,
2024/2/28
脏读,不可重复读,幻读 ,mysql5.7以后默认隔离级别是什么? (出现的原因,,设置的隔离级别不同,又因并发开启事务操作)
脏读、幻读和不可重复读是数据库中的三种并发问题,它们可能会导致数据的不一致性
脏读(Dirty Read): 回滚导致, 事务隔离级别设置成了 读未提交
读未提交
指挡圈事务读取了另一个事务未提交的数据;读到并一定最终存在的 [常发生于转账与取款操作]
不可重复读(Non-repeatable Read):
前后多次读取,数据内容不一致。
(指的是A事务在两次读取同一数据之间,另一个事务B修改了该数据,导致第A事务两次读取的结果不一致)
幻读(Phantom Read):
前后多次读取,数据总量不一致 ----查时存在
(指一个事务在两次查询之间,另一个事务插入了新的数据,导致第一个事务两次查询的结果不一致)
注:
幻读,并不是说两次读取获取的结果集不同,幻读侧重的方面是某一次的 select 操作得到的结果所表征的数据状态无法支撑后续的业务操作。
更为具体一些:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读
MySQL 5.7版本以后,默认的隔离级别是可重复读(Repeatable Read)。 会存在幻读
在可重复读隔离级别下,事务可以看到其他事务已经提交的数据,但是不会看到其他事务尚未提交的数据。
这意味着在同一个事务中,多次读取同一数据会得到相同的结果
什么是qps,tps,并发量,pv,uv
QPS:
Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
估算自己项目的QPS 取决于并发量和平均响应时间
0.1s * 10 =1s 假设并发量是1 平均响应时间是0.1 QPS是10
TPS:
TransactionsPerSecond,意思是每秒事务数, 包括一条信息进入和一条信息退出,加上一次用户数据库访问
过程包括客户端请求服务端、服务端内部处理、服务端返回客户端。
什么是并发量? ,, ,
并发量指的是同一时刻向服务器处理的请求数量。
QPS=并发量 / 平均响应时间
并发量=QPS * 平均响应时间 例如当前QPS =1w 每个请求响应 2s 并发量= 2w
什么是PV?
访问量,Page View, 指网站页面浏览量或者点击量,页面被刷新一次就计算一次。如果网站被刷新了1000次,那么流量统计工具显示的PV就是1000 。
什么是UV?
独立访客,Unique Visitor,同一个客户端访问网站记为一次,在一段时间内不论刷新多少次,都只记为一次。
了解 * * * ** DAU(日活) DAU(Daily Active User),日活跃用户数量。常用于反映网站、app、网游的运营情况。 DAU通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户),与UV概念相似 # MAU(月活) MAU(Month Active User):月活跃用户数量,指网站、app等去重后的月活跃用户数量
什么是接口幂等性问题,如何解决?
同一个接口,多次发出同一个请求,必须保证只执行一次
——其任意多次执行对资源本身所产生的影响均与一次执行的影响相同
(增加了服务器逻辑复杂,成本,降低效率)
-get 获取数据天然幂等
-put 修改数据天然幂等
-修改库存(数字加减):不幂等
-delete 删除 天然幂等
-post 新增数据,会出现不幂等的情况,要把它做成幂等性的
解决方案主要分为两个技术方向,一个是客户端防止重复调用,另一个是服务端进行校验。
服务端的校验分为 ①分布式锁解决方案 ②唯一索引解决方案 ③乐观锁解决方案 ④token解决方案
token机制 1、下单接口的前一个接口,只要一访问,后端生成一个随机字符串,存到redis中,把随机字符串返回给前端 2、然后调用业务接口请求时,把随机字符串携带过去,一般放在请求头部 3、服务器判断随机字符串是否存在redis中,存在表示第一次请求,然后redis删除随机字符串,继续执行业务。 4、如果判断随机字符串不存在redis中,就表示是重复操作,直接返回重复标记给client,这样就保证了业务代码,不被重复执行
乐观锁机制---》更新的场景中
update t_goods set count = count -1 , version = version + 1 where good_id=2 and version = 1
-扣减id为2的商品库存---》进入到扣减页面---》数据库中查一下这个数据的version号[假设是10]
-访问扣减库存接口---》带着之前的version来了
-后端的sql如下:
update t_goods set count = count -1 , version = version + 1 where good_id=2 and version = 10
-第一次可以顺利扣减
-第二次:带的版本号还是10---》sql执行失败了--->扣减不了了
# 唯一主键
这个机制是利用了数据库的主键唯一约束的特性,解决了在insert场景时幂等问题。但主键的要求不是自增的主键,这样就需要业务生成全局唯一的主键
# 唯一ID(unique)
调用接口时,生成一个唯一id,redis将数据保存到集合中(去重),存在即处理过
前端来到下单页面,前端生成唯一id,只要下单,带着这个唯一id到后端---》后端取出来--》存到reids中--》继续后续操作---》带着同样的id过来,redis中有了,这个就不继续执行了
# 防重表
使用订单号orderNo做为去重表的唯一索引,把唯一索引插入去重表,再进行业务操作,且他们在同一个事务中。这个保证了重复请求时,因为去重表有唯一约束,导致请求失败,避免了幂等问题。
这里要注意的是,去重表和业务表应该在同一库中,这样就保证了在同一个事务,即使业务操作失败了,也会把去重表的数据回滚。这个很好的保证了数据一致性。
# 前端:
按钮只能点击一次
开源项目 sql审核平台
-https://gitee.com/cookieYe/Yearning
-https://gitee.com/rtttte/Archery
------------------------------------------------------------------------------------------
2024/2/29
1 什么是gil锁,有什么作用 (解决需要多进程,释放需要限制 ticks计数=100)
1 GIL:又称全局解释器锁。本质就是一个互斥锁,
互斥锁(多线程编程的同步机制,保护任意时刻仅一个线程对共享资源的访问,而不会在访问的中途被其他线程介入)
4. 保证 cpython进程 每个线程 获得这锁 才能执行
2 使得在同一进程内任何时刻仅有一个线程在执行 (被 gil锁 限制 开三个线程 会执行一个)
3 gil锁只针对于cpython解释器----》
JPython
PyPy
CPython
————————gil锁会限制
为什么有它 是因为python自带垃圾回收机制,它是一个线程,运行则回收,假如开了多个线程,进行回收时,保证其他线程不能运行, 原来是单核 所以加锁 没影响, 但是如今多核,开多线程不能使用 多核。
***作用:***
1 保护Python对象免受多线程并发访问的破坏。
2 确保在多线程环境中只有一个线程执行Python字节码。 (防止并发)
3 GIL的存在使得在CPU密集型任务中,Python的多线程并不能充分发挥多核CPU的优势。
因为只有一个线程能够执行字节码,其他线程会被阻塞。
2 python的垃圾回收机制(GC)是什么样的
垃圾回收:编程语言在运行过程中会定义变量--->申请了内存空间---》后期变量不用了---》应该释放不同语言垃圾回收的方式是不一样的,python是使用如下三种方式做gc,以引用计数为主,
标记-清除和分代回收两个算法为辅
(1)引用计数算法(reference counting):
每个对象(变量)都有一个引用次数的计数属性,如果对象被引用了,那这个数就会 加1,如果引用被删除,
引用计数就会 减1,那么当该对象的引用计数为0时,就说明这个对象没有被使用,垃圾回收线程就会
把它回收掉,释放内存。 ——当一个被引用时,会加一,但是失去引用时 会减少 当为0时 就是没被引用,就要释放
-有问题:循环引用问题---》.引用计数不为0 变量应该回收
(2) 标记-清除算法(Mark and Sweep):
-解决引用计数无法回收循环引用的问题
对象之间通过引用连在一起,节点就是各个对象,从一个根对象向下找对象,可以到达的标记为
活动对象,不能到达的是非活动对象,而非活动对象就是需要被清除的。
通过循环引用的,导致它本身还剩下一次引用 无法消除 l=[1,2[3,4]]
[1,2[3,4]] 没有标记根 不能到活动对象 【3,4】 要被清除
(3) 分代回收算法(Generational garbage collector):
-分代回收是解决垃圾回收效率问题
算法原理是Python把对象的生命周期分为三代,分别是第0代、第1代、第2代。
每一代链表都有总数阈值,当达到阈值(最高的限制)的时候就会触发GC(垃圾回收机制)回收,将需要清除的清除掉,不需要清除的移到下一代。以此类推,第2代中的对象存活周期最长的对象。对象就是那些数据,长时间未消除的, 三代触发时间不同
注意:python垃圾回收最核心是:
引用计数----》标记清除解决引用计数的循环引用问题---》分代回收解决垃圾回收的效率问题。
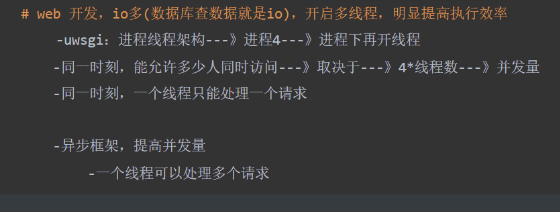
3 解释为什么计算密集型用多进程,io密集型用多线程
只针对于cpython解释器(其他语言,都开多线程即可,能够利用多核优势)
-计算是消耗cpu:代码执行,算术,for都是计算
-io不消耗cpu:打开文件,写入文件,网络操作都是io
-如果遇到io,该线程会释放cpu的执行权限,cpu转而去执行别的线程
-由于python有gil锁,开启多条线程,同一时刻,只能有一条线程在执行
-如果是计算密集型,开了多线程,同一时刻,只有一个线程在执行
-多核cpu,就会浪费多核优势
-如果是计算密集型,我们希望,多个核(cpu),都干活,同一个进程下绕不过gil锁
-所以我们开启多进程,gil锁只能锁住某个进程中得线程,开启多个进程,就能利用多核优势
-io密集型---》只要遇到io,就会释放cpu执行权限
-进程内开了多个io线程,线程多半都在等待,开启多进程是不能提高效率的,反而开启进程很耗费资源,所以使用多线程即可
————————————————————————————————————————————————————————————————————————————————————
2024/3/4
1 为什么有了gil锁还要互斥锁

- GIL 本身就是大的互斥锁
gil锁只有一个线程下执行 互斥锁保护数据的安全 - 互斥锁(多线程编程的同步机制,保护任意时刻仅一个线程对共享资源的访问,而不会在访问的中途被其他线程介入)
- 多个线程操作同一个变量 会出现 数据安全问题
- 临界点 :一段代码或一段程序片段,同一时间只能被一个线程执行, 多个线程操作会出现 并发安全
线程遇到 io / 时间片转轮,时间片到了,就会自动切换 --释放gil锁
GIL和互斥锁的区别(为什么要一起用):
- GIL不确定执行到哪里会释放访问权,换其他的线程执行;
- 互斥锁可以控制线程切换执行的位置,即锁住 临界区
2 进程,线程和协程
1.进程,线程和协程的含义
进程:是资源分配的最小单位,一个应用程序运行起来,至少有一个进程,进程管理器中就可以看到一个个的进程
线程:是cpu调度,执行的最小单位,一个进程下至少有一个线程
协程:单线程下的并发,程序层面控制的任务切换
进程是计算机操作系统中进行资源分配和调度的最小单位。
- 当一个应用程序被执行时,至少会创建一个进程。
- 每个进程都有自己独立的内存空间和系统资源,包括文件描述符、网络连接等。在进程管理器中,我们可以看到运行中的各个进程。
线程是操作系统进行任务调度和执行的最小单位。
- 一个进程中至少有一个线程,也可以创建多个线程。
- 线程共享进程的内存空间和系统资源,可以并发执行不同的任务。
- 通过在不同的线程之间切换执行,实现了多任务的效果。
- 线程之间的切换由操作系统的调度器负责。
协程是一种更加轻量级的并发编程方式,它是由程序自身控制的任务切换。
- 在单线程下使用协程可以实现并发执行多个任务。
- 不同于线程的抢占式调度,协程采用协作式调度,即一个任务让出执行权给另一个任务。
- 协程之间的切换不依赖于操作系统的调度器,相比于线程具有更高的执行效率和更小的资源消耗。
总结:
-
进程是资源分配的最小单位,一个应用程序至少包含一个进程;
-
线程是CPU调度和执行的最小单位,一个进程至少包含一个线程;
-
协程是单线程下的并发编程方式,由程序自身控制任务切换,具有高效和低资源消耗的特点。
进程:
import multiprocessing
def worker():
print("子进程执行")
if __name__ == '__main__':
p = multiprocessing.Process(target=worker)
p.start()
p.join()
print("父进程执行")
解释:
使用Python的multiprocessing模块实现了一个简单的进程。
首先定义一个子进程,然后使用multiprocessing.Process方法创建一个新的进程对象。
调用start方法启动子进程,join方法等待子进程结束后再返回父进程。
最后在父进程中输出一句话。
线程
import threading
def worker():
print("子线程执行")
if __name__ == '__main__':
t = threading.Thread(target=worker)
t.start()
t.join()
print("主线程执行")
解释:
使用Python的threading模块实现了一个简单的线程。
首先定义一个子线程,然后使用threading.Thread方法创建一个新的线程对象。
调用start方法启动子线程,join方法等待子线程结束后再返回主线程。
最后在主线程中输出一句话。
协成
def coroutine():
for i in range(10):
yield i
if __name__ == '__main__':
coro = coroutine()
for val in coro:
print(val)
解释:
使用Python的生成器实现了一个简单的协程。
首先定义一个生成器函数,使用yield关键字返回一个值。
然后定义一个生成器对象,并循环读取生成器中的值。
在这个例子中,生成器中有10个数字,使用for循环逐一读取生成器中的数字并输出。
注意,在这个例子中协程的调度是由Python解释器负责的。
因此,虽然代码中使用了yield关键字,但是协程的切换实际上是由Python解释器在调度时自动完成的。
3.使用案例
当需要运行多个独立的任务等计算密集型,可以使用多进程。例如,一个电商网站可能需要同时处理订单、库存管理、用户管理等多个独立的任务,这时可以使用多进程来分别处理这些任务。
在需要同时处理多个IO密集型任务时,可以使用多线程。例如,一个网络服务器需要同时处理多个客户端的请求,这时可以使用多线程来处理每个客户端的IO操作。
协程适合于需要高并发、轻量级任务的场景。例如,一个实时聊天应用可能需要同时处理大量的用户消息,这时可以使用协程来处理每个用户的消息,以提高并发处理能力。另外,爬虫、数据抓取等需要大量并发请求的场景也适合使用协程来提高效率。
,,,,,,,,,
#1 子类重写父类方法----》继承后的 重写
class Animal:
def run(self):
print('动物走路')
class Person(Animal): # 子类又 叫 派生类
# 重写父类方法
def run(self):
print('人走路')
def run(self,name):
print('人走路')
# 子类的派生方法
def speak(self):
print('说话')
#2 派生方法
#3 重写父类方法时,参数个数不一样,子类对象调用时会怎么样?
子类重写的方法,跟父类中参数或返回值不一样---》java重载
#4 对象的绑定方法,类的绑定方法,静态方法如何实现,有什么作用
3 什么是鸭子类型
鸭子类型是Python面向对象编程中的一个概念,鸭子类型是多态一种形式,其中只要对象实现了相应的方法,函数就可以在对象上执行操作。
在鸭子类型中,关注点在于对象的方法或属性,而不是关注对象所属的类型。
- 在鸭子类型中,并不关注对象的具体类型或继承关系,而是关注对象的行为是否满足特定的需求。
- 如果一个对象拥有与特定数据类型相符合的方法、属性或行为,那么它就可以被视为该数据类型的实例,即使它并没有显式地继承或声明实现该数据类型。
优点:
- 允许我们使用任何提供所需方法和属性的对象,而不需要编写子类;
- 减少公共基类和接口的定义,从而减少了复杂的继承链,同时也减少了多重继承的使用;
- 调用方只管调用,不管对象是什么类型,从而屏蔽不同类型对象之间的差异;
举例:定义一个动物类,鸭子和大鹅有共同的属性,都会叫,他们就是鸭子类型
多态是面向对象编程中的一个重要概念,指的是同一类事物具有多种不同的形态或表现方式 在程序中,多态性则是指不考虑对象具体类型的情况下使用对象,即一个对象可以具有多个不同的类型。 这使得我们能够以更加灵活和通用的方式处理各种不同类型的对象。 例如 假设我们有一个Animal类,以及它的三个子类:人、狗和猫。 这些子类都继承自Animal类,但又具有各自特定的行为和属性。 利用多态性,我们可以统一地对待这些不同的子类对象,而无需关心它们具体是哪个子类。 """ 1.多态是面向对象的特点之一,其他的两个特点是继承,和封装 2. 多态指的是事物的多种形态 3. 多态带来的特性:在不考虑对象的具体的类型下,直接调用对应的方法或者属性 """ import abc # 内置的abc模块 abstract class 抽象类 # 类变成了抽象类有什么特点:1.只能被继承,不能被实例化 ---->抽象类可以限制子类里必须有父类定义的方法 class Animal(metaclass=abc.ABCMeta): # 这个类就变成了抽象类 @abc.abstractmethod def speak(self): # 类里面的方法就变成了抽象方法 pass # 父类里面的方法不再实现具体的功能,只是定义继承父类的子类中一定要有这个方法 """父类中如何限制子类中的方法名,父类中定义的方法名,在子类中一定要有,哪怕是空""" class People(Animal): # 只要继承了Animal里面一定要有speak这个方法 def speak(self): pass class Pig(Animal): def speak(self): pass class Dog(Animal): def speak(self): pass obj = People()
——————————————————————2024/3/5————————
1 什么是猴子补丁,有什么用途
猴子补丁:动态修改或扩展代码的技术,通在不修改源代码的情况下,改变代码的执行方式或增加功能 -Monkey Patching是在 运行时(run time) 动态替换属性(attributes)或方法 -Python的类是可变的(mutable),方法(methods)只是类的属性(attributes);这允许我们在 运行时(run time) 修改其行为。这被称为猴子补丁(Monkey Patching), 它指的是偷偷地更改代码。

虽然装饰器和猴子补丁 用途差不多,但装饰器不能改变执行方式
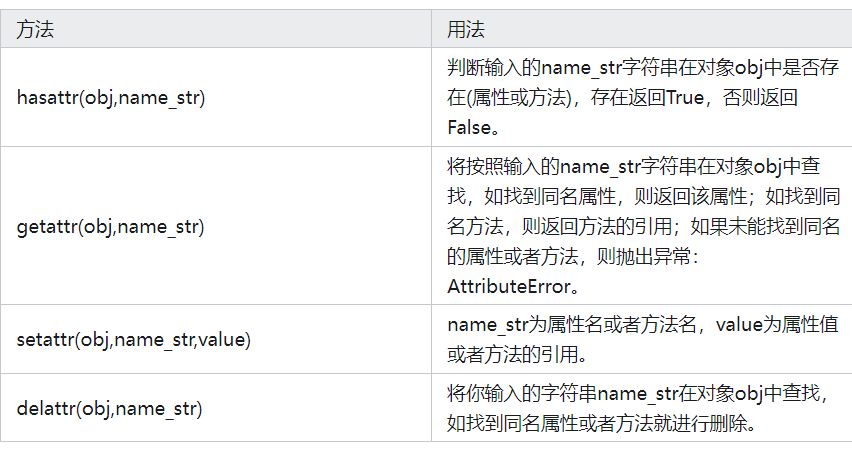
2 什么是反射,python中如何使用反射
反射:是程序在运行过程中通过字符串来操作对象的属性和方法
使用反射:
getattr(obj,name)返回属性或方法
setattr(obj,key,value)
hasattr(obj,key)
delattr(obj,key)
# 可使用反射的地方:
1、反射类中的变量 : 静态属性,类方法,静态方法
2、反射对象中的变量、对象属性、普通方法
3、 反射模块中的变量
4、反射本文件中的变量
场景:
动态导入模块
配置文件解析
ORM框架
3 http和https的区别
https://zhuanlan.zhihu.com/p/561907474 1 端口:http:80,https:443 2 数据展现形式:http:明文,https:密文 3 http页面响应速度比https快,https还有ssl握手 HTTP 由于是明文传输,主要存在三大风险:窃听风险、篡改风险、冒充风险
https= http+ssl
————————————————2024/3/6————————
1 从浏览器输入一个地址,到看到页面信息,经历的过程
#https://blog.csdn.net/m0_52165864/article/details/126313277
1.就是浏览器输入一个域名,(地址不带端口,默认端口就是80端口),就要做域名解析(也就是DNS解析),把域名解析成IP地址+端口的形式,然后就是查看浏览器缓存(以前访问过这个地址,浏览器就会自动加缓存),直接从从缓存中获取,(就比如F5刷新,浏览器的无痕窗口),dns解析:先解析本地host文件,然后就是自己配置的dns,如果还没有就去全球十三个根dns,如果还没解析到,就会报错(本地的host文件可以修改,)
2.解析后,拿到ip地址和端口后,准备建立TCP连接(TCP是可靠连接,处于传输层,进行三次握手,建立连接)
3.向解析出来的地址发送http的get请求,(可以说说http协议)
4.请求到了后端,后端服务使用nginx转发,(nginx就是反向代理服务器),nginx将http请求转发给web框架(django,flask)如果是django,经过django生命周期,到达视图函数,返回响应
5.后端服务器将http响应的形式返回给客户端、浏览器
6.浏览器将响应体渲染在浏览器中,(http响应又有响应状态码,响应头,响应体)
7.四次挥手断开TCP连接(连接不一定会断开)
本地配置host文件,st
2 左连接,右连接,内连接,全连接:MySQL不能直接支持
-数据通常不在同一张表中,这就涉及到连表操作,而表间连接方式有很多
-内连接:把两张表中共有的数据,连接到一起
-左连接:以左表为基准,把左表所有数据都展示,有可能右表没有,用空补齐
-右连接:以右表为基准,把右表所有数据都展示,有可能左表没有,用空补齐
-全连接:以左右两表数据作为基准,左右两表数据都展示,有可能左或表没有,用空补齐
# 笛卡尔积
select * from book,publish where book.publish_id=publish.id;
第一个表
id name age publish_id
1 xx 11 1
2 yy 12 1
第二个表
id name age
1 xx 11
2 yy 12
1 xx 11 1 1 xx 11
1 xx 11 2 yy 12
2 yy 12 1 1 xx 11
2 yy 12 1
# 左右键连接
2 左连接,右连接,内连接,全连接:MySQL不能直接支持
select * from book left join publish on book.publish_id=publish.id;
book.publish_id=99
publish.id没有99
3 union和union all的区别?
-作用:select 出来结果,union,union all都是对结果进行合并,并对结果进行排序,求并集,字段类型和列都要一致才能用 -union 会去除重复的数据,去重和排序操作 -union all 不会去除重复的数据,不会去重和排序 select name,id form user; id name 1 lqz 2 zs select name,id form book; id name 1 lqz 2 西游记 select name,id form user union all select name,id form book; id name 1 lqz 1 lqz 2 zs 2 西游记 select name,id form user union all select name,id form book; id name 1 lqz 2 zs 2 西游记
4 一句sql查询慢,如何排查优化
# 1 orm 原生sql
# 2 接口响应速度慢---》定位到是sql问题
-索引优化:分析sql有没有走索引----》EXPLAIN SELECT * FROM orders WHERE name = 123;
在表中添加合适的索引可以显著提升查询效率。可以通过 EXPLAIN 命令来查看查询计划,判断是否使用了索引,如果没有使用索引,就需要考虑添加索引
-避免全表扫描:避免在大表上进行全表扫描,可以通过限制查询条件或者使用分页查询来解决
-使用分页,避免全表搜索,扫码
-优化查询语句:
EXPLAIN SELECT * FROM orders WHERE name like 123%;
-优化sql,不要写 前面的模糊查询
-尽量使用主键查询,尽量不模糊匹配
-数据库表结构优化
-大表拆成小表
-做数据库读写分离
-分库分表
轮播图表更新,就删除redis缓存 -----django信号
自定义命令 python manage.py .runserve
——————————————2024/3/8
tcp 三次握手和四次挥手
SYN=1 建立链接 ACK=1 收到,允许 seq:随机数 ack:回应请求+1 FIN:断开
tcp协议 处于 osi7层协议的传输层 可靠连接
三、、、指在tcp链接时
第一次握手:客户端向服务器发送一个连接请求,【携带一个随机数 syn=1 seq=随机数】
第二次握手,服务端回应客户端建立连接请求 【ACK=1 ack=随机数+1】,服务器发送建立连接另一个随机数【SYN=1,seq=另一个随机数】
第三次握手,当客户端回应服务端 建立连接请求【ACK=1,ack=另一个随机数】
四、、、在tcp断开链接
一: 客户端发送 断开请求【FIN=1 ,seq=随机数】
二: 服务器收到请求后,回复请求 【ACK=1,ack=随机数】
三: 服务器发送断开请求 【FIN=1,seq=另一个随机数 , ACK=1,ack=随机数+1】
四:客户端收到请求 回复请求 【ACK=1,ack=另一个随机数+1】
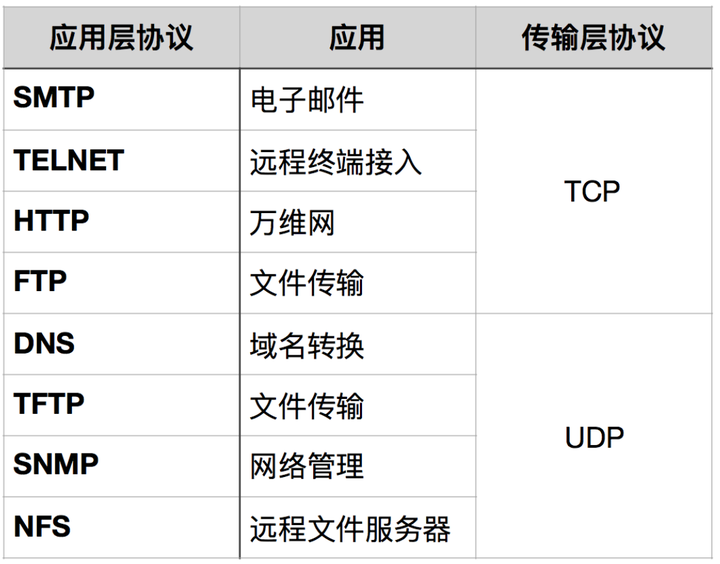
osi七层协议(网络体系)七层,每层有哪些
应用层 :HTTP,FTP,NFS 提供应用接口 表示层:Telnet,SNMP 处理信号,翻译与加密 会话层:SMTP,DNS 建立,管理表示层实体间通话
传输层(端口):TCP,UDP 提供可靠数据传输服务
网络层:IP,ICMP(网络是否可达), 负责数据包路由转发
数据链路层:,ARP(地址解析协议),PPP(点对点协议)
负责将比特流阻止成数据帧,并在物理媒介上传输
物理层:IEEE 802.1A,IEEE 802.11 负责物理媒介上传输
tcp和udp的区别?
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接 2、TCP提供可靠的服务。传送的数据不出错按时到达
UDP尽最大努力交付,即不保证可靠交付 3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的 UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等) 4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信 5、TCP首部开销20字节;UDP的首部开销小,只有8个字节 .....字节8个 6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道 # 为何基于tcp协议的通信比基于udp协议的通信更可靠? tcp:可靠 对方给了确认收到信息,才发下一个,如果没收到确认信息就重发 udp:不可靠 一直发数据,不需要对方回应 #udp用在哪里了? 当应用程序对传输的可靠性要求不高,但是对传输速度和延迟要求较高时,可以用UDP协议来替代TCP协议在传输层控制数据的转发。 UDP适合于实时数据传输,如语音和视频通信,因为它们即使偶尔丢失一两个数据包,也不会对接收结果产生太大影响。例如:我们在看视频的时候偶尔丢一两个包也不影响体验。 #为什么有了TCP还要有UDP https://zhuanlan.zhihu.com/p/145946470
————————————————2024/3/10
1 wsgi uwsgi uWSGI,cgi,fastcgi 分别是什么?这些是与Web服务器和应用程序通信的一些不同协议和接口标准。
web服务器又称
客户端(浏览器,app)跟服务端(web框架)之间的东西,服务器中间件
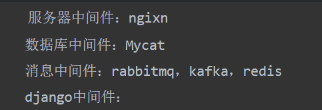
1.WSGI(同步事件) ---服务器:uwsgi,gevent,fcgi,werkzeug(flask),bjoern: 2.WSGI是一种python定义的Web服务器与web应用程序之间的标准接口协议。 3.它定义了一个规范,使得Web服务器和Python应用程序之间可以进行通信,使得不同的Web服务器可以与不同的Python框架和应用程序进行交互。 4.WSGI的目标是提供一个通用的接口,使得开发者可以将其Python应用程序部署到多个不同的Web服务器上,而无需修改应用程序的代码。 ****ASGI与WSGI类似,ASGI描述了Python Web应用程序和Web服务器之间的通用接口。
与WSGI不同的是,ASGI允许每个应用程序有多个异步事件---- Uvicorn,Daphe
5.uWSGI: ----服务器:django,flask 6.uwsgi:uWSGI是一个Web服务器网关接口的实现,同时也是一个应用服务器。 7.它实现了WSGI标准,并提供了额外的功能,如负载平衡、进程管理、异步处理等。 8.uWSGI的设计目标是高性能和灵活性,可以用于部署Python和其他语言的应用程序。 9.CGI(Common Gateway Interface): 10.CGI是一种通用的协议,用于在Web服务器和外部程序之间传递数据。 11.在CGI模型中,每个HTTP请求都会启动一个新的进程,执行一个外部脚本或程序,然后将结果返回给Web服务器。 12.尽管CGI是一个通用的接口,但由于每个请求都需要启动一个新的进程,它的性能相对较低,因此在现代Web开发中较少使用。 13.FastCGI:-----服务器:Apache,Nginx, Microsoft , IIS 14.FastCGI是CGI的改进版本,旨在提高性能。 15.与每个请求启动一个新进程的CGI不同,FastCGI使用长连接(persistent connections),在多个请求之间保持一个进程的状态,从而减少了进程启动和关闭的开销。 16.FastCGI在一些Web服务器和应用程序之间成为一种常见的协议,以提高性能和效率。 总体而言,WSGI定义了一种Python特定的Web服务器与应用程序通信的标准接口,而uWSGI实现了这个接口并提供了其他功能。CGI和FastCGI则是通用的协议,用于不同语言的Web服务器与应用程序之间的通信。
2 如何自定制上下文管理器
自定义上下文管理器是在Python中创建可使用 with 语句的一种方式,管理资源的分配和释放
要自定义上下文管理器,你需要创建一个类并实现两个特殊方法:__enter__ 和 __exit__。 下面是一个简单的示例,演示了如何自定义上下文管理器: class MyContextManager: def __enter__(self): # 进入上下文时的操作 print("Entering the context") return self def __exit__(self, exc_type, exc_value, traceback): # 离开上下文时的操作 print("Leaving the context") if exc_type is not None: # 如果在上下文中发生了异常,exc_type会是异常的类型 print(f"An exception of type {exc_type} occurred with message: {exc_value}") # 返回 True 表示已处理异常,返回 False 表示将异常传播到调用者 return True # 使用自定义的上下文管理器 with MyContextManager() as context: print("Inside the context") # 如果需要,在此执行更多操作 在上面的示例中,MyContextManager 类定义了 __enter__ 和 __exit__ 方法。当 with 语句进入代码块时,__enter__ 方法被调用,并返回一个上下文管理器的实例。当离开代码块时,无论是正常离开还是由于异常离开,都会调用 __exit__ 方法。 在 __exit__ 方法中,参数 exc_type、exc_value 和 traceback 分别代表引发的异常的类型、值和回溯信息。如果 __exit__ 方法返回 True,表示异常已经被处理,否则异常将被传播到调用者。
3 Python是值传递还是引用传递

在 Python 中,传递参数的方式是按对象引用传递(传递的是引用地址,也就是变量所对应的内存空间的地址)
(可不谈)函数接收的是实际参数对象的引用,而不是对象的副本。在函数内部,对这个引用的操作可能影响到原始对象。 值传递是将参数的副本传递给函数,因此函数接收的是参数值的一个副本,而不是参数本身,内部任何修改不会影响到原始变量的值。
引用传递是将参数的地址或引用传递给函数。 这意味着函数接收的是对原始数据的引用,而不是数据的副本。
然而,对于可变对象和不可变对象,表现会有一些不同:
1.不可变对象(例如整数、字符串、元组): 可变:(列表 ,字典,集合)
2.无法在函数内部修改原始对象,因为不可变对象的值在创建后不可更改。
3.在函数内部对不可变对象的操作实际上是创建了一个新的对象,而不是修改原始对象。 def modify_immutable(x): x = x + 1 print("Inside function:", x) num = 10 modify_immutable(num) print("Outside function:", num) 输出: Inside function: 11 Outside function: 10 4.可变对象(例如列表、字典): 5.在函数内部可以修改原始对象,因为可变对象的值是可以修改的。 6.如果在函数内修改了可变对象,这样的修改会在原始对象上生效。 def modify_mutable(lst): lst.append(4) print("Inside function:", lst) my_list = [1, 2, 3] modify_mutable(my_list) print("Outside function:", my_list) 输出: Inside function: [1, 2, 3, 4] Outside function: [1, 2, 3, 4] 虽然 Python 的参数传递机制是按对象引用传递的,
但是针对(可变和不可变),在函数内对参数的修改可能有不同的效果。
这一点与“传值”和“传引用”的严格定义略有不同,因此通常会说 Python 中的参数传递是“传对象引用”。
——————————————————2024/3/11
1 什么是迭代器,生成器,装饰器
- 迭代:一种不依赖于索引取值的方式,不需要关注它的位置,只要能够一个个取值,它就称之为迭代,python中就是for循环,内部调用对象.__next__()
- 可迭代对象:python中可以被for循环的对象或可以变量.__next__()取值即为可迭代对象;str, list, dict, tuple, set, 文件对象都是可迭代对象

- 迭代器:可迭代对象调用__iter__()就得到了迭代器,迭代器有__iter__和__next__方法
- 自定义迭代器:写个类,类中重写__iter__和__next__方法,这个类的对象就是迭代器
下面是一个示例,展示如何在Python中自定义迭代器:
class MyIterator:
def __init__(self, data):
self.data = data
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index >= len(self.data):
raise StopIteration
value = self.data[self.index]
self.index += 1
return value
这个自定义迭代器接受一个数据列表作为参数,并使用data属性来存储数据。初始化时,设置index为0来追踪当前迭代到哪个位置。
__iter__方法返回迭代器对象本身,这是迭代器模式的标准实现。
__next__方法用于获取下一个元素。如果index超过了数据列表的长度,那么抛出StopIteration异常来停止迭代。否则,返回当前索引位置的值,并将index增加1以准备迭代到下一个元素。
下面是使用自定义迭代器的示例:
pythonCopymy_list = [1, 2, 3, 4, 5]
my_iter = MyIterator(my_list)
for element in my_iter:
print(element)
输出:
1
2
3
4
5
这样,我们就可以根据自己的需求定义迭代器,实现按照特定规则和顺序进行迭代。
1.文件对象即是可迭代对象又是迭代器对象
2.迭代器一定是可迭代对象,可迭代对象不一定是迭代器
3.当元素被取完的时候,再去利用__next__取值,会抛出异常
迭代取值 1.只能从前往后挨个取值,不能倒回去,除非重新生成一个新的迭代器
2.支持所有数据类型
索引取值
1.重复取值
2.不支持所有的数据类型,支持可以索引取值(列表、元组、字符串)的数据类型
- 生成器
是迭代器的一种,生成器一定是迭代器,迭代器不一定是生成器
- 函数中如果存在 yield 关键字,在调用函数之前,还是一个普通函数,一旦调用函数,就把函数变成了生成器
- 生成器表达式,也可以做出生成器 (i+1 for i in [1,2,3])
比如有一堆数据,要放到列表中,但你没放,而放到了生成器中 for 循环生成器---》可以惰性取值(不是把值一次性放在某一个可迭代对象里,而是循环一次取一个),可以节省内存
- 代码遇到 yield 关键字,会被冻结,再次执行 next() ,代码从上一次被冻结的位置继续往下执行
- yield 和 return 的对比 '''
yield 1. 可以有返回值
2. 函数遇到yield不会结束,只会'冻结'
3. yield关键字把函数变成了生成器,支持迭代取值了
return 1. 可以有返回值
2. 遇到return关键字直接结束函数运行 '''
- 在哪里用过生成器?
1.读取文件,for循环内部其实就是在用生成器
2.django中orm查询一个表所有内容 Book.objects.all()--->内部应该也是一个生成器
3.redis中hash类型hscan 和 hscan_iter
4.类似于这种场景可以用到它的:比如我要取数据,但是数据量比较大,不要一次性把把数据取到内存中,而是一点点取值,这样就可以把它做成一个生成器,可以节约内存
# 装饰器
- 名称空间:存放变量值和变量名关系的地方
内置的名称空间:在python解释器中存在
全局的名称空间:在py文件中,顶格写的代码都在全局名称空间中 查看:print(globals())# 字典形式
局部的名称空间:在函数体代码执行完产生的数据 查看:print(locals()) # 一定写在函数内部
- 闭包函数:
闭:定义在函数内部的函数
包:内部函数使用外部函数名称空间中得名字 多了一种给函数传参的方式 ,,(外部作用 引用)
- 装饰器,本身是一个闭包函数 在不改变被装饰对象的内部代码和原有调用方式的基础上再添加额外的功能
- 运用场景 flask的路由就是基于装饰器
django的信号也可以用装饰器方式注册
django中局部去除csrf认证
为接口记录访问日志 认证。。
给类加装饰器,,在类实例化得到对象时,为对象加入跟多熟悉或方法
- 语法糖 每次调用函数都要写2行很别扭,引入语法糖
书写规范:
1.语法糖要紧贴再被装饰对象的头上
2.原理:把紧贴着的被装饰对象自动传给装饰器函数
- 双层语法糖 写的时候从上往下写,执行的原理是从下往上,实际执行是从上往下 调用的时候虽然名字一样,但是并不是原函数,被装饰器伪装了,实际是最上层语法糖的返回值
- 装饰器修复技术 print(func_name)
打印函数名和help(func_name)可以帮助看清本质 from functools import wraps
'在装饰器outer函数里写'
2 django的信号用过吗?如何用,干过什么
# Django提供的一种通知机制,他是设计模式观察者模式(X发布订阅X),在发生某种变化的时候,通知某个函数执行
- 23种设计模式
1.装饰器模式————装饰器
2.迭代器模式————迭代器,不依赖索引取值从容器对象中访问一个个元素,还不暴露对象的内部细节
3.代理模式————真正用一个东西时,没有使用该东西,而是让代理去拿;flask中的request就是代理对象,真正的对象在后面藏着。通过一个代理对象来控制对实际对象的访问
4.[单例模式](https://www.cnblogs.com/10086upup/p/17606300.html)
5.观察者模式————观察者模式也叫发布-订阅模式,其定义如下: 定义对象间一种一对多的依赖关系,使得当该对象状态改变时,所有依赖于它的对象都会得到通知,并被自动更新。
运用在Django的信号中 https://www.cnblogs.com/liuqingzheng/p/10038958.html
- 内置信号 内置信号用起来简单,只需要写个函数,跟内置信号绑定,当信号被触发,函数就会执行 -
使用方式:2种
1.connect连接
2.使用装饰器@receiver
# 当User表创建用户,记录日志
# 方式一
1.写一个函数,放在__init__里,因为代码要执行
from django.db.models.signals import post_save
import logging
def callback(sender,**kwargs):
logging.debug('%s创建了一个%s对象'% (sender._meta.,odel_name,kwargs.get('instance').title))
2.绑定内置信号
post_save.connect(callback)
3.等待触发
# 方式二 使用装饰器
from django.core.signals import request_finished
from django.dispatch import receiver
@receiver(request_finished) # 本质就是用了connect
def my_callback(sender, **kwargs):
print("Request finished!")
- 自定义信号
1.定义信号(一般创建一个py文件)
import django.dispatch
pizza_done = django.dispatch.Signal( providing_args=["toppings", "size"])
2.绑定信号
def callback(sender,**kwargs):
print('callback')
print(sender,kwargs)
pizza_done.connect(callback)
3.触发信号: 信号.send
from 路径 import pizza_done
pizza_done.send(sender='seven',toppings=123, size=456)
# 信号发送者sender
https://www.cnblogs.com/liuqingzheng/articles/9803403.html
# 应用场景
- 记录日志
- 做双写一致性的缓存更新(据库中插入数据,把数据同步到别的位置)
- 一旦生成订单,发送邮件
- 用户删除发短信通知
- 用户修改密码,发信号让token失效
#钉钉通知 django集成钉钉
双写一致性 ----》 信号和缓存
通过信号实现,只要book表插入条记录 redis同步
- 用户登陆后,系统向他发送最新动态信息。
- 数据库数据发生变化后,实现缓存数据同步变化、实现数据审计等
- 订单中商品数量影响库存数量,即不同模型的联动更新。
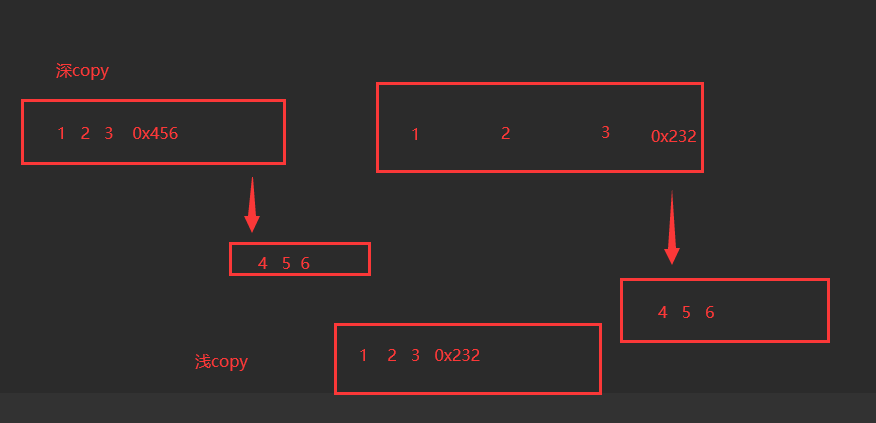
3 什么是深拷贝,什么是浅拷贝,如何使用
# 无论深拷贝还是浅拷贝都是用来复制对象的
# 如果是浅copy,只会复制一层,如果copy的对象中有可变数据类型,修改可变数据类型还会影响拷贝的对象。(可变类型的数据被copy时,会申请新的内存空间,同时指向了同一个内存空间。)
使用场景:当我们只需要复制数据结构的第一层,并且不想在新的数据结构中做任何修改会影响原始数据结构时,可以使用浅拷贝。
# 如果是深copy,完整复制,无论可变或不可变,都是创建出新的来,以后再改原对象,都不会对copy出的对象造成影响 https://www.cnblogs.com/lmygbl/p/10124827.html
使用场景:当我们需要完全独立的数据结构副本,以便在副本上做任何修改而不影响原始数据结构时,应使用深拷贝。
对不可变类型数据深copy:
如果不可变类型对象没有内嵌可变类型对象,此时的深copy和浅copy相同,只是copy了引用,
如果内嵌了可变类型,这时的深copy就是完全复制了这个不可变对象,id就不相同了
****.一般在爬虫开发中,爬取的数据存放在字典中,在循环爬取过程中,需要引用字典来存储数据
或者在回调函数中进行传递,因为字典是可变类型,相同key的下一组数据在循环存入时,会覆盖
原来字典的值,因此在字典传递时,对字典进行深copy,这样传递出去的字典就是一个独立的数据,
不在受后面操作的影响,保证了数据的独立性
——————————————————2024 / 3 /12
1 并发 并行
(一)并发 Concurrency 系统具有同一时间段内处理多个任务的能力 所有操作系统都支持并发,单核cpu也可以并发 (二)并行 Parallelism 并行是指同一时刻处理多个任务的能力。比如同时执行A和B。 ***并行必须是cpu支持
(三)并发和并行的区别
并发轮流处理,而并行同时处理。
并发和并行的区别就是一个人同时吃三个菜和三个人每人吃一个菜;
单核不能并行,只能并发。
多核或者多cpu既能并行,也能并发。
串行
多个任务依次进行,每个任务必须等待上一个任务完成才能开始
#扯出去
1.python开启多线程,即便有多核CPU也只能并发,无法进行。
原因是有GIL锁
2.python开启多进程+多核CPU才能并行
3.io密集型使用多线程(大部分都是io不消耗CPU,开多进程没有用),计算密集型使用多进程(提高CPU利用率)
2 同步 异步(程序调用的角度)
(一)同步 synchronous 同步就是在执行某个请求的时候,是有序的完成,需要一件一件来完成。 (二)异步 asynchronous 异步就是在执行某个请求的时候,不需要等待它完成就可以,是无序的,可以立即切换到另一个任务。 (三)区别 区别在于消息通信方向相反。 同步是调用方通知被调用方,异步是被调用方通知调用方。同步是调用方主动查询,异步是调用方被动接收。
适用范围 当需要执行I/O操作时,使用异步操作比使用多线程更合适。 长时间CPU运算的场合,使用多线程更合适。例如耗时较长的图形处理和算法执行。 我们用过的异步 -借助与其它框架:scrapy、celery
-fastapi:异步web框架 -sanic:异步web框架
比如,甲方委托乙方生产衣服,甲方隔两天问乙方生产完了吗,这叫同步;甲方不问,而是等到乙方生产完了通知甲方,这叫异步。
多线程和异步都可以避免阻塞,但异步和多线程不是一个概念。
多线程编程简单。有调度开销。并且线程间的共享变量可能造成死锁的出现。
异步使用回调的方式,没有调度开销,在设计良好的情况下,处理函数可以不必使用共享变量,减少了死锁的可能。编写异步操作的复杂程度较高,程序主要使用回调方式进行处理,与普通人的思维方式有些出入,而且难以调试。
3 阻塞 非阻塞(程序执行的角度)-------一定是有io操作 才涉及
阻塞与非阻塞关注的是程序在等待调用结果时候的状态。。
(一)阻塞 Blocking
程序在等待某个操作完成期间,无法继续干别的事。
(二)非阻塞 Non-blocking
程序等待某个操作中,不会被阻塞,可以继续干别的事
(三)区别
在于是否释放cpu
阻塞是cpu空转,白白浪费;
非阻塞是cpu不会空转。
CPU空转是指CPU在工作时呈空闲状态,即CPU正在执行指令,但是这些指令却并没有对数据进行处理,也没有对计算机系统的其他部分进行操作,这时CPU出于等待状态,
例子
1.同步阻塞:
老张在厨房用普通水壶烧水,一直在厨房等着(阻塞),盯到水烧开(同步)
2.同步非阻塞:
老张在厨房用普通水壶烧水,在烧水过程中,就到客厅去看电视(非阻塞),然后时不时去厨房看看水烧开了没 (同步,主动询问)
3.异步阻塞:
老张在厨房用响水壶烧水,一直在厨房中等着(阻塞),不用盯着,而是等到水壶发出响声(异步),老张知道水烧开了
4.异步非阻塞:
老张在厨房用响水壶烧水,在烧水过程中,就到客厅去看电视(非阻塞),当水壶发出响声(异步),老张就知道水烧开了
————————————————————2024/3 /13
1 什么是IPC,如何进行进程间通信(需要另一个进程产生的数据)
# 线程间通信:https://zhuanlan.zhihu.com/p/489305763
任何两个程序 取出消息,比如在django中的一个消息,从中取出, 用redis(更好)
-共享内存(共享变量)---》线程间变量是共享的---》lock---》
临界区---》数据错乱---》互斥锁---》死锁问题(科学家吃面)---》递归锁(可重入锁)---》各种各样的锁 -IPC:Inter-Process Communication,进程间通信 -两种情况: -同一台机器上的两个进程通信 -不同机器上的两个进程进行通信 -如何通信: -如果都是python写的,同一台机器上的进程可以用queue做进程间通信 -消息队列:redis就可以做消息队列,RabbitMQ,kafka -socket套接字:展现形式: 1 服务和服务之间通过接口调用(http调用) 2 RPC调用:远程过程调用 3 socket客户端和服务端
---socker通信,,两个机器之间通过底层 套接字,
进程是操作系统资源分配的基本单位,而线程则是处理器任务调度和执行的基本单位,
同时进行会造成数据安全问题,因为多个线程并发安全达到临界区..需要串行,避免就需要互斥锁,
会出现死锁;需要递归锁解决死锁问题
2 正向代理,反向代理
https://www.cnblogs.com/liuqingzheng/p/10521675.html 代理其实就是一个中介,A和B本来可以直连,中间插入一个C,C就是中介 -正向代理:代理的是客户端 VPN 爬虫代理池 -反向代理:代理的是服务端 nginx # 看一下:https://blog.csdn.net/lsc_2019/article/details/124630025 # 正向代理(Forward Proxy) 正向代理是位于客户端和目标服务器之间的代理服务器。
当客户端发出请求时,请求首先发送到正向代理服务器,然后由代理服务器转发请求给目标服务器。
这种情况下,目标服务器不知道请求来自于哪个客户端,而只知道请求来自代理服务器。 主要用途包括: - 为内部网络提供访问外部网络的权限控制,例如公司内部的员工访问互联网。 - 保护客户端的隐私,因为目标服务器只知道代理服务器的IP地址而不知道实际客户端的IP地址。 - 加速访问,通过缓存常用资源。 # 反向代理(Reverse Proxy) 反向代理是位于目标服务器和客户端之间的代理服务器。
当客户端发出请求时,请求首先发送到反向代理服务器,然后由代理服务器决定将请求转发给哪个后端目标服务器。
这种情况下,客户端不知道后端目标服务器的信息。 主要用途包括: - 提供负载均衡,将客户端的请求分发到多个后端服务器,以提高性能和可靠性。 - 隐藏后端服务器的结构和信息,提高安全性。(Nginx转发请求) - 缓存内容,以减轻后端服务器的负载。 - SSL终结,将SSL/TLS握手交给代理服务器处理,减轻后端服务器的计算负担。
3 什么是粘包
# 只存在于基于TCP协议的套接字编程中的现象 -因为TCP是流式协议,tcp客户端发送的多个数据包就会像水流一样流向TCP服务端,
多个数据包就会'粘'在一起,区分不开是几个数据包,造成了粘包现象。 # 原因 1.缓冲区: 发送方将多个数据包写入缓冲区,而接收方并不总是能够立即读取缓冲区中的数据,这可能导致多个数据包一起发送给接收方。 2.优化: 操作系统或网络设备可能会对数据进行优化,将多个小的数据包合并为一个较大的数据包,从而提高传输效率。这可能导致接收方无法正确地分辨每个原始数据包。 3.并发: 在多线程或多进程的情况下,多个发送者同时发送数据,接收者可能会在接收数据时混淆数据包的边界。 # 解决方法 -1 每个包设置结束标志 http协议采用这种 /r/n/r/n -2 每个包设置固定大小的头,头中包含包的大小
——————————————————————2024 /3 /14
1 http协议详情,http协议版本,http一些请求头
#1 http是超文本传输协议,它是基于Tcp之上的应用层协议(osi七层) #2 特点: 1 基于请求响应--》服务端不能主动给客户端推送消息---》websocket协议 2 无状态无连接---》不知道是谁,不能做会话保持(客户端与服务端消息回复,保持双方的聊天状态)
---》才使用cookie,session,token 3 基于tcp之上的应用层协议---》osi七层 #详情: -请求协议: 请求首行:请求方式(get,post,delete),请求地址,请求http协议版本号/r/n分割 ;整个结束用双/r/n 请求头:key:value (cookie,useragent,referer,x-forword-for)---
x-forword-for 是识别通过HTTP代理或负载均衡方式,连接到原始IP地址,http请求头字段
referer是请求页面的来源页面的地址
useragent 用户代理--识别系统
cookie识别数据
请求体:编码方式 -响应协议: 响应首行:http协议版本,响应状态码(1xx,2xx),响应单词描述 响应头:key:value (cookie,响应编码。。。) 跨域问题的响应头(自己设置的响应头)acssess ,regain 响应体:html格式:浏览器中看到的 json格式给客户端使用
GET请求和POST请求的区别
post更安全(不会作为url的一部分) post发送的数据更大(get有url长度限制) post能发送更多的数据类型(get只能发送ASCII字符) post比get慢 post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作
# 协议版本 -0.9: HTTP协议的最初版本,功能简陋,仅支持请求方式GET,并且仅能请求访问HTML格式的资源
-1.0:****节约资源 但是1.0版本的工作方式是每次TCP连接只能发送一个请求(默认短链接),当服务器响应后 就会关闭这次连接,下一个请求需要再次建立TCP连接,就是不支持keep-alive -1.1: 引入了持久连接(persistent connection),即TCP连接默认不关闭,可以被多个请求复用, 不用声明Connection: keep-alive。客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。 -2.0: 多路复用:对于 HTTP/1.x,即使开启了长连接,请求的发送也是串行发送的,在带宽足够的 情况下,对带宽的利用率不够,HTTP/2.0 采用了多路复用的方式,可以并行发送多个请求, 提高对带宽的利用率 -3.0: HTTP3.0又称为HTTP Over QUIC,其弃用TCP协议,改为使用基于UDP协议的QUIC协议来实现
UDP(无连接的传输协议) QUIC(安全加密传输的协议)
2 如何实现服务器给客户端发送消息,websocket是什么?用过吗
# 服务端主动向客户端发送消息 # http的无连接,基于请求响应 # 1 轮询: 客户端向服务端循环发送http请求,一旦服务端有最新消息,从当次http响应中带回,客户端就能收到变化 # 2 长轮回(web版微信采用此方式) 客户端和服务端保持一个长连接(http),等服务端有消息返回就断开, 如果没有消息,就会hold住,等待一定时间,然后再重新连接,也是个循环的过程 # 3 websocket协议 客户端发起HTTP握手,告诉服务端进行WebSocket协议通讯,并告知WebSocket协议版本。 服务端确认协议版本,升级为WebSocket协议。之后如果有数据需要推送,会主动推送给客户端 ***-websocket:一种通信协议,区别于http协议,可在单个TCP连接上进行全双工通信。 允许服务端主动向客户端推送数据。浏览器和服务器只需要完成一次tcp连接, 两者之间就可以建立持久性的连接,并进行双向数据传输
*******************************************************************
-没有跨域问题 -应用场景: -只要涉及到服务端主动给客户端发送消息的场景,都可以用 -实时聊天 -服务端发生变化,主动向客户端推送一个通知 -监控服务端的内存使用情况 -djanog中使用channles模块实现 -flask中使用模块 -https://zhuanlan.zhihu.com/p/371500343
3 悲观锁和乐观锁,如何实现
#无论是悲观锁还是乐观锁,都是人们定义出来的概念,保证并发数据的安全 # 什么是并发控制: -1 并发控制:当程序中出现并发问题时,就需要保证在并发情况下数据的准确性, 以此确保当前用户和其他用户一起操作时,所得到的结果和他单独操作时的结果是一样的, 这种手段就叫做并发控制 -2 没有做好并发控制,就可能导致脏读、幻读和不可重复读等问题
之前多线程同时操作一个变量 加互斥锁----并发控制 # 悲观锁: 悲观锁:当要对一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是 直接对该数据进行加锁以防止并发,让并行变成串行 -------互斥锁,递归锁,,获得才可以操作 -这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制 【Pessimistic Concurrency Control,缩写PCC,又名悲观锁】 - 之所以叫做悲观锁,是因为这是一种对数据的修改持有悲观态度的并发控制方式。 总是假设最坏的情况,每次读取数据的时候都默认其他线程会更改数据, 因此需要进行加锁操作,当其他线程想要访问数据时,都需要阻塞挂起。 -悲观锁实现方式: 1 传统的关系型数据库(如mysql)使用这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁 2 编程语言中的线程锁,比如python的互斥锁 3 分布式锁:redis实现的分布式锁等 # 乐观锁: 通过程序实现(没有真正的一把锁),不会产生死锁 总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁, 只在更新的时候会判断一下在此期间别人有没有去更新这个数据,如果更新了,我们就不做修改 -乐观锁实现方案: 1 CAS(Compare And Swap) 即比较并交换。是解决多线程并行情况下使用锁造成性能损耗的 一种机制,CAS 操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B),执行CAS操作的 时候,将内存位置的值与预期原值比较,如果相匹配,那么处理器会自动将该位置值更新为新值, 否则,处理器不做任何操作CAS会出现ABA问题,比如,你看到桌子上有100块钱, 然后你去干其他事了,回来之后看到桌子上依然是100块钱,你就认为这100块没人动过, 其实在你走的那段时间,别人已经拿走了100块,后来又还回来了。这就是ABA问题 - 解决ABA问题:既然有人动了,那我们对数据加一个版本控制字段,只要有人动过这个数据, 就把版本进行增加,我们看到桌子上有100块钱版本是1,回来后发现桌子上100没变, 但是版本却是2,就立马明白100块有人动过 2 版本号控制:在数据表中增加一个版本号字段,每次更新数据时将版本号加1,同时将当前版本号 作为更新条件,如果当前版本号与更新时的版本号一致,则更新成功,否则更新失败 3 时间戳方式:在数据表中增加一个时间戳字段,每次更新数据时将时间戳更新为当前时间戳, 同时将当前时间戳作为更新条件,如果当前时间戳与更新时的时间戳一致,则更新成功,否则更新失败 # 悲观锁乐观锁使用场景 并发量:如果并发量不大,可以使用悲观锁解决并发问题;但如果系统的并发非常大的话, 悲观锁定会带来非常大的性能问题, 建议乐观锁 响应速度:如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败, 不需要等待其他并发去释放锁。乐观锁并未真正加锁,效率高 冲突频率:如果冲突频率非常高,建议采用悲观锁,保证成功率。冲突频率大, 选择乐观锁会需要多次重试才能成功,代价比较大 重试代价:如果重试代价大,建议采用悲观锁。悲观锁依赖数据库锁,效率低。更新失败的概率比较低 读多写少: 乐观锁适用于读多写少的应用场景,这样可以提高并发粒度 #django中使用:下单,秒杀场景 # django中如何开启事 -全局开启:每个http请求都在一个事务中 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'lqz', 'HOST': '127.0.0.1', 'PORT': '3306', 'USER': 'lqz', 'PASSWORD': 'lqz123', #全局开启事务,绑定的是http请求响应整个过程 'ATOMIC_REQUESTS': True, } } -每个视图函数开启 from django.db import transaction @transaction.atomic def seckill(request): -局部开启 from django.db import transaction def seckill(request): with transaction.atomic(): pass return HttpResponse('秒杀成功') -保存点,回滚保存点Savepoint -设置回滚点:sid = transaction.savepoint() -提交回滚点: transaction.savepoint_commit(sid) transaction.commit() -回滚到回滚点: transaction.savepoint_rollback(sid) transaction.rollback() - 事务提交后回调函数 transaction.on_commit(send_email) #django中使用悲观锁 #django中使用乐观
# 1 mysql char 的数字表示什么意思
在 MySQL 中,CHAR 是一种用于存储固定长度字符串的数据类型。当你声明一个列为 CHAR 类型时,你需要指定该列的长度。例如,CHAR(10) 表示该列可以存储最多 10 个字符的字符串,不论实际存储的字符串长度是多少,都会用空格填充到指定的长度。
CHAR 类型的数字表示其字符的最大长度。例如,CHAR(10) 表示该列可以存储最多 10 个字符的字符串。
# 2 mysql varchar的数字表示什么意思
在 MySQL 中,VARCHAR 是一种用于存储可变长度字符串的数据类型。与 CHAR 类型不同,VARCHAR 类型允许存储的字符串长度是可变的,但仍然受到指定的最大长度限制。
当你声明一个列为 VARCHAR 类型时,你需要指定该列可以存储的最大字符数。例如,VARCHAR(255) 表示该列可以存储最多 255 个字符的字符串。
这个数字表示的是该列能够容纳的最大字符数,并且这个数字会影响到数据库中存储数据所占用的空间。请注意,实际存储在 VARCHAR 列中的字符串长度可以少于指定的最大长度,但不能超过它
# 3 mysql中 int 的数字表示什么意思
在 MySQL 中,INT 是一种用于存储整数的数据类型。当你声明一个列为 INT 类型时,后面的数字表示该列能够存储的整数范围。
具体来说,数字代表了整数的存储范围。在 MySQL 中,INT 类型通常指的是带符号的整数,其范围取决于指定的数字大小。以下是一些常见的 INT 类型及其范围:
INT(1) 至 INT(4):分别表示 4 个字节的整数,能够存储的范围约为 -2^31 (-2147483648) 至 2^31-1 (2147483647)。
INT(5) 至 INT(9):同样是 4 个字节的整数,范围也是约为 -2^31 至 2^31-1。
INT(10) 至 INT(24):8 个字节的整数,能够存储的范围约为 -2^63 (-9223372036854775808) 至 2^63-1 (9223372036854775807)。
INT(25) 至 INT(53):8 个字节的整数,范围也是约为 -2^63 至 2^63-1。
请注意,这些范围是以有符号整数的形式给出的。如果你使用无符号整数 (UNSIGNED INT),则范围将从 0 开始,而不是从负数开始
# 4 mysql中utf8和utf8mb4有什么区别
在 MySQL 中,utf8 和 utf8mb4 是用于设置字符集和校对规则的关键字,它们之间有一些重要的区别。
# 存储能力:
utf8:在 MySQL 5.5.3 之前的版本中,utf8 只支持最多 3 字节的 UTF-8 编码,因此无法存储一些特殊字符(如 Emoji 表情等)
utf8mb4:从 MySQL 5.5.3 版本开始引入了 utf8mb4 字符集,支持最多 4 字节的 UTF-8 编码,可以存储更广泛的 Unicode 字符,包括 Emoji 表情等
# 存储空间:
由于 utf8 仅支持最多 3 字节的编码,因此某些字符如果使用 utf8 存储会被截断,而 utf8mb4 可以完整存储这些字符。
使用 utf8mb4 字符集存储文本可能会占用更多的存储空间,因为它支持更广泛的字符集。
# 兼容性:
utf8 是 MySQL 的默认字符集,但在处理一些特殊字符时可能会出现问题,尤其是 Emoji 表情等。
utf8mb4 能够更好地支持现代应用中的多语言字符和特殊字符,因此在实际应用中更为常见。
因此,如果你的应用需要存储包含 Emoji 表情等特殊字符的文本,建议使用 utf8mb4 字符集。在创建数据库或表时,可以通过设置字符集和校对规则来指定所需的字符集,例如:
CREATE DATABASE my_database CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
CREATE TABLE my_table (
my_column VARCHAR(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci
);
这样就可以确保你的数据库和表能够正确地存储和处理各种特殊字符。
#5 mysql中varchar最大能存多长字符串
在 MySQL 中,VARCHAR 类型可以存储可变长度的字符串,其最大长度取决于数据库的版本和配置。
在 MySQL 5.0.3 之前的版本中,VARCHAR 列的最大长度为 255 个字符。然而,从 MySQL 5.0.3 版本开始,这个限制被改为 65,535 个字符。不过,这个最大长度仍受到行大小限制的影响,因为一个行的最大大小是 65,535 字节。此外,索引和其他列也会占用部分行大小。
需要注意的是,如果你使用的是 utf8mb4 字符集,每个字符可能会占用多个字节,这会进一步降低实际存储的字符串长度。通常来说,VARCHAR 列的最大长度是 65,535 个字节,而不是字符。因此,如果你的字符集是 utf8mb4,那么实际能够存储的字符数将取决于存储的字符所占用的字节数。
如果你需要存储超过 65,535 个字符的字符串,可以考虑使用 TEXT 或 LONGTEXT 类型,这些类型可以存储更大的文本数据,但需要额外的存储空间和处理成本
使用第三方的话不安全怎么办?
基于官方api封装,一定意义上来说稳定,但是还是无法规避不安全的成分在,但是就算换做人工来说,相似无二。
更多 链接查看
https://blog.csdn.net/DominicJi/article/details/83861977?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E8%80%81%E7%94%B7%E5%AD%A9%E6%9C%88%E8%80%83&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-83861977.142
https://blog.csdn.net/CXY00000/article/details/121341136

 浙公网安备 33010602011771号
浙公网安备 33010602011771号