Django 日作 12/3 ---日志模块封装(loguru)
#1 python loguru 如何用,如何把日志写到文件中,日志级别有哪些
https://loguru.readthedocs.io/en/stable/resources/recipes.html#compatibility-with-multiprocessing-using-enqueue-argument 官方 loguru
不需要配置, 输出到文件的话——先导入 loguru包, from loguru import logger (不同等级的有不同的区分)
最低的等级是 debug 输出的一些信息都会显示出来
info 正常的print一些信息提示
warning 警告
error 错误
critical 非常严重的错误

如何做格式化的输出(与python 的 format语句基本一样)
在其内添加一个大括号 可以在后面继续传一个参数 代表其内容 (不限于字符串 任何可以转换字符串的东西)

如何输出到日志文件里去呢?
先导入 loguru包, from loguru import logger
直接 logger add (一个文件路径 )
from loguru imoport logger
from config.demo import case_log #文件是通过 config下 demo下的 case_log
通过源代码我们可以知道 case_log也是动态区获得的文件路径 其root_dir 会在 根目录生成一个case_log的目录; 下面会有一个 case_log.log的文件
def get_log(file): #(file)传入参数文件 将传入的日志信息 放到的 哪个文件里
logger.add(sink=file,encoding='utf-8')
return logger
get_log =get_log(case_log) #定义变量 将case_log传进去后 就可以用get_log.xxxx
if__name__=='__main__'
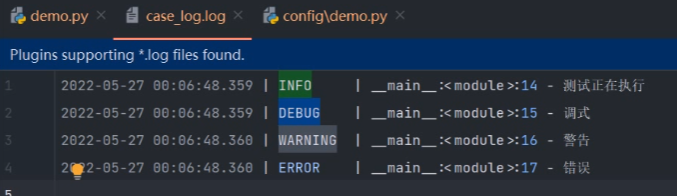
get_log.info('测试正在执行')
get_log.debug('调试')
get_log.warnning('警告')
get_log.error('错误')
执行完之后 会在项目的根目录 生成一个 case_log文件 在文件下会有一个case_log文档
如果想对此文件做一个滚动;比方说 限制每一个日志文件的大小 ----
 (通常不会以 10KB [太小])
(通常不会以 10KB [太小])
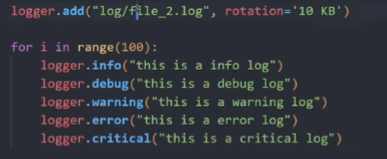
达到10KB后会把它改个名字,继续在文件里 清空再打
# loguru的使用比较简单 一个add()方法就能做完所有事情
# settings.py
from loguru import logger
import os
LOG_DIR = os.path.join(BASE_DIR, "logs") # 定义日志文件目录,确保该目录存在
# 可以做判断 不存在则创建 os.mkdir
LOGGING_CONFIG = None # 禁用默认的 Django logging 配置
logger.remove(handler_id=None) # 指定不在控制台输出(默认输出在控制台中)
logger.add(os.path.join(LOG_DIR, "debug.log"), level="DEBUG", rotation="1 day", retention="7 days")
logger.add(os.path.join(LOG_DIR, "info.log"), level="INFO", rotation="1 day", retention="7 days")
logger.add(os.path.join(LOG_DIR, "error.log"), level="ERROR", rotation="1 day", retention="7 days")
logger.add(os.path.join(LOG_DIR, "critical.log"), level="CRITICAL", rotation="1 day", retention="7 days")
# 参数分别为: 文件保存的路径,日志级别,每隔一天创建一个log,最长保留时间
# rotation="500MB", compression="zip" 的意思是当日志文件达到500MB的时候会自动压缩为zip格式并新建一个log文件
# views.py 注册功能示例
from loguru import logger
def regi(request):
try:
username=request.POST.get('username')
password=request.POST.get('password')
if username and password:
user = User.objects.create_user(username=username, password=password)
logger.info('%s注册了账号' % username) # 用户注册成功后会在info.log输出-xx注册了账号-
return redirect('/login/')
logger.info('一个注册请求') # 当用户访问注册页面时会在info.log输出一个-注册请求-
return render(request, 'regi.html')
except Exception as e:
logger.critical('异常为:%s' %e) # 报错时记录错误信息,并写入critical.log文件中
# 以上的这种写法会把高级别的日志信息写入对应的以及更低级别的日志文件中,会占用更多的资源。
# 只需要增加参数filter即可实现写入对应级别的文件中:
filter=lambda x:'CRITICAL' in str(x['level']).upper() # 加上一个过滤的参数
lambda x:: 这创建了一个匿名函数,接受一个参数 x。
'CRITICAL' in str(x['level']).upper(): 这是一个条件表达式,检查日志记录中的级别是否包含字符串 'CRITICAL'。具体操作如下:
x['level']: 获取日志记录中的级别。
str(...): 将级别转换为字符串。
.upper(): 将字符串转换为大写。这是为了确保不区分大小写。
'CRITICAL' in ...: 检查是否字符串 'CRITICAL' 包含在转换后的字符串中。
单进程
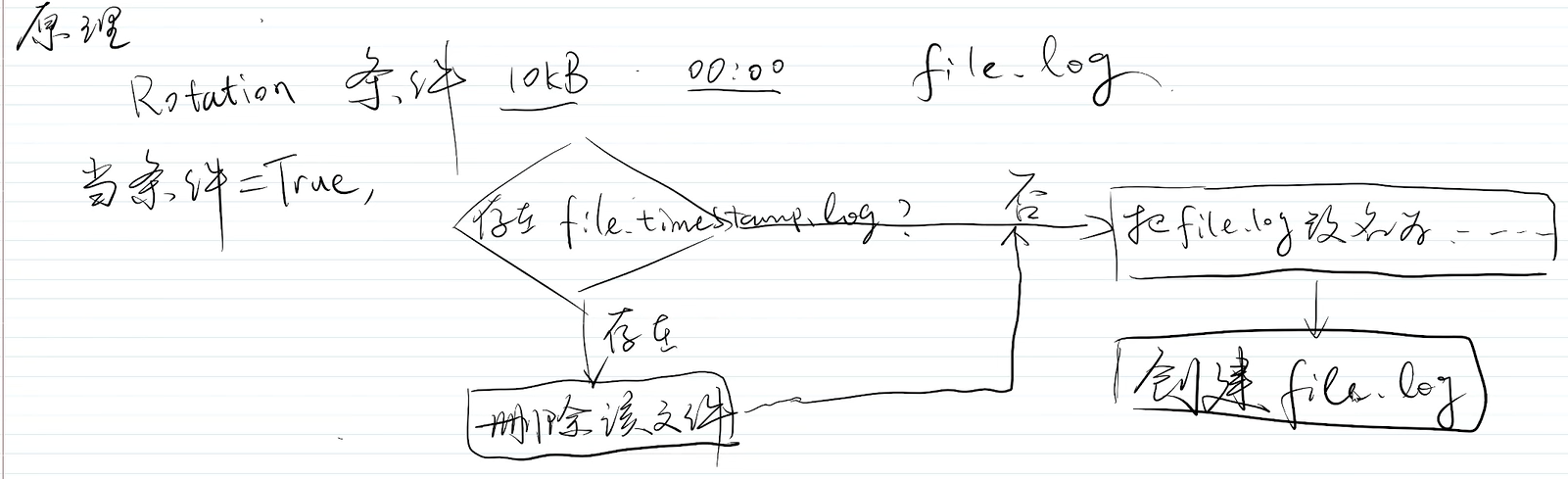
该库似乎在多线程的多场景下是有问题的,那么如何在多线程下使

假如两个进程同时在写日志,当他们同时触发了这个条件,
假设A稍微快一些,那么A过来走流程时,会发现系统中不存在这个文件,所以他会把 file.log 该名成这个文件---创建了一个新文件。
而B呢 由于它晚了一些,他去检查时 已经存在这个文件了,那么b就要把这个文件删掉 于是 再去重命名再去创建; b的删除操作 就把已经有的日志给删掉了。
loguru怎么处理呢(多进程):

假设我们现在有多个进程,之前他们是自己去写日志,各自去访问日志的文件;
问题在于 :可能同时在写日志文件,而“我”再写是 不知道是否有其他人也在写。。
所以现在 不是直接与[日志文件] 进行一个交互
而用到了 一个中间人------相当于一个服务的提供者,需要取得它的服务就要 排队。
A---( ) B---( ) C--( ) 那他们就分别去 这排队
然后由 这个人 (中间人) 再依次的把 这些要写的日志 写到这个日志文件里,包括日志的rotation 也是由 这个人来完成的 [此时和日志交互的只有这一个人] ------而由于这个排队的数据结构叫做队列, 所以参数叫 encoque
而 enque ---当一个进程相要写日志的时候,他需要把他的日志丢到这个队列里,所以有了这个参数
----github --(issure)
---documentation
# 2 扩写auth的user表,给这个表加一个手机号字段
使用bootstrap画出好看页面
实现注册登录,使用cookie和session、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号