
Python——针对记录的SQL语句,,配置文件的介绍,,存储引擎的使用(存储方式),,数据类型,,整形_浮点型_字符串_日期_枚举,,约束条件,,记录,,创建数据库操作
针对记录的SQL语句
配置文件的介绍
存储引擎的使用(存储的方式)
数据类型***
整型 浮点型 字符串 日期 枚举
约束条件
zerofill unsigned not nu default unique
primary key auto_increment
sql是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持sql。
<1> 在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写;
<2> SQL语句可单行或多行书写,以“;”结尾。关键词不能跨多行或简写。
<3> 用空格和缩进来提高语句的可读性。子句通常位于独立行,便于编辑,提高可读性。
<4> 注释:单行注释:--
多行注释:/*......*/
<5>sql语句可以折行操作
<6> DDL,DML和DCL
————————————————————————————————————————————————————————————————————————————————————
记录: 表中记录的一行行数据 称之为是一条记录1.查看所有的数据库名称(mysql的data下的文件夹)
先有表,再有库,最后操作记录
1.查看所有的数据库名称(mysql的data下的文件夹)
show databases; # 查看所有数据库,一个名字就是一个库
2.查看当前库所有的表名称
show tables;
3.查看所有的记录
select * from mysql.user;
select * from user; # 如果在mysql库下,就直接写
select * from mysql.user/G; # 格式化展示,竖向形式
4. 查看当前在哪个库下
select database();
sql语句必须以分号结尾
sql语句编写错误之后不用担心,
可以直接执行,直接报错
或者取消执行,在语句后面加\c
cmd中粘贴直接使用右键
MySQL默认忽略大小写
-- 1.创建数据库(在磁盘上创建一个对应的文件夹)
create database [if not exists] db_name [character set xxx]
-- 2.查看数据库
show databases;查看所有数据库
show create database db_name; 查看数据库的创建方式
-- 3.修改数据库
alter database db_name [character set xxx]
-- 4.删除数据库
drop database [if exists] db_name;
-- 5.使用数据库
切换数据库 use db_name; -- 注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
查看当前使用的数据库 select database();
查看记录
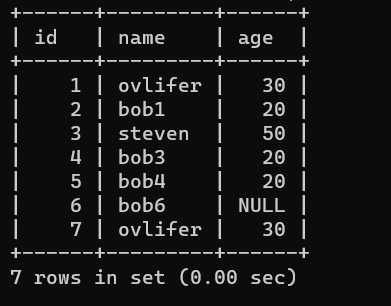
select * from t1;
*号 代替 所有的字段 例如 id ,name, age 等
from 后 代表查哪一张表的数据
增加数据(单条增加)
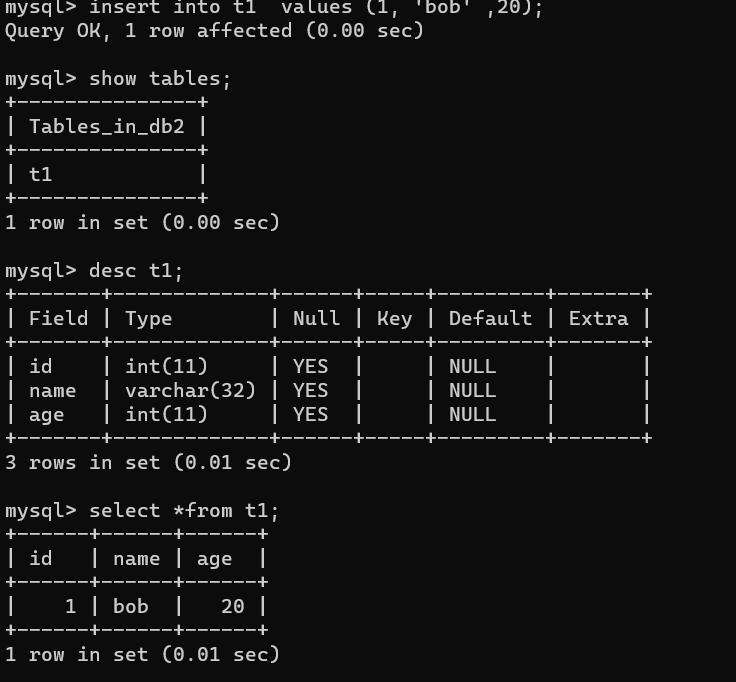
insert into t1 values (1, 'bob' ,20);
一次性加入多条(批量增加)
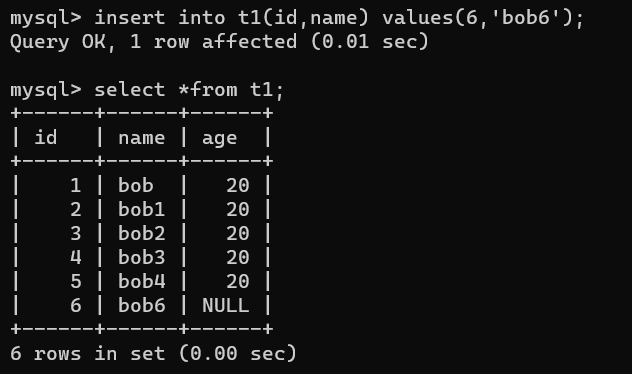
insert into t1 values (2, 'bob1' ,20),(3, 'bob2' ,20),(4,'bob3' ,20),(5, 'bob4' ,20);

指定字段 增加
insert into t1(id,name) values(6,'bob6'); 空的没有指定 NULL填充
3. 修改
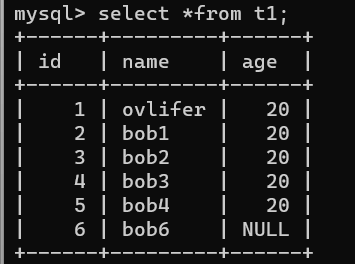
update t1 set name='ovlifer' where id =1
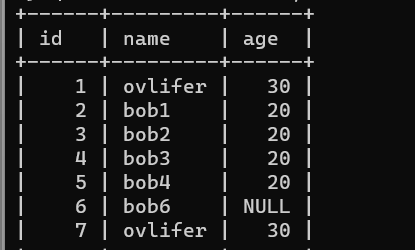
添加后 insert into t1 values(id,name) values(7,'ovlifer20');
update t1 set age =30 where name='ovlifer';
如果修改指定的 例如 id为3
update t1 set bob2 ='steven' ,age =50 where id =3;
如果名字一样 修改 ovlifer 30 的 名字为 大奔
update t1 set age =40 where id=7;
7 ovlifer 40 后
update t1 set name ='daben' where name='ovlifer' and age =30;

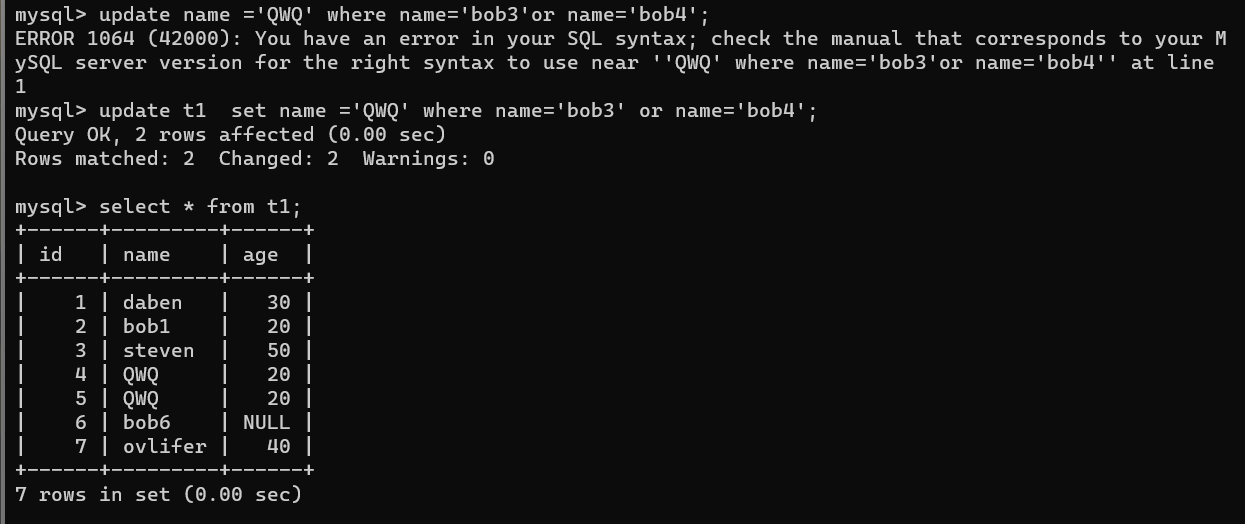
如果修改 bob3 或者bob4 年龄为 ***时 把 and 改为 or
update t1 set name='QWQ' where name='bob3' or 'bob4'
————————————————————————————————————————————————————————————————————————————————
mysql的配置文件是 my-default.ini(需复制重命名)
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
存储引擎的使用
存储引擎就是存储数据的方式!
MySQL支持多少种存储引擎方式
1. 如何查看存储引擎
show engines;
一共九种存储引擎,重点学习:MyISAM MEMORY InnoDB
MyISAM:
它是MySQL5.5版本及之前的版本默认的存储引擎、它的读取速度很快相比较与InnoDB,但是它的数据安全性较低,相对于InnoDB存储引擎
不支持事务、支持的是表锁
InnoDB:
它是MySQL5.6及之后的版本默认的存储引擎、它的读取速度相对慢一些,但是数据的安全性较高一些
它支持:事务、行锁、外
MEMORY:
它是基于内存存储的,意味着断电数据丢失、重启服务端数据就丢失
演示
create table t2 (id int, name varchar(64)) engine=MyISAM;
create table t3 (id int, name varchar(64)) engine=InnoDB;
create table t4 (id int, name varchar(64)) engine=MEMORY;
对于不同的存储引擎,硬盘中保存的文件个数也是不一样的
MyISAM:3个文件
.frm 存储表结构
.MYD 存储的是表数据
.MYI 存索引(当成是字典的目录,加快查询速度)
InnoDB:2个文件
.frm 存储表结构
.ibd 存储数据和索引
MEMORY:1个文件
.frm 存储表结构
————————————————————————————————————————————————————————————————————————————————————————————————
数据类型:
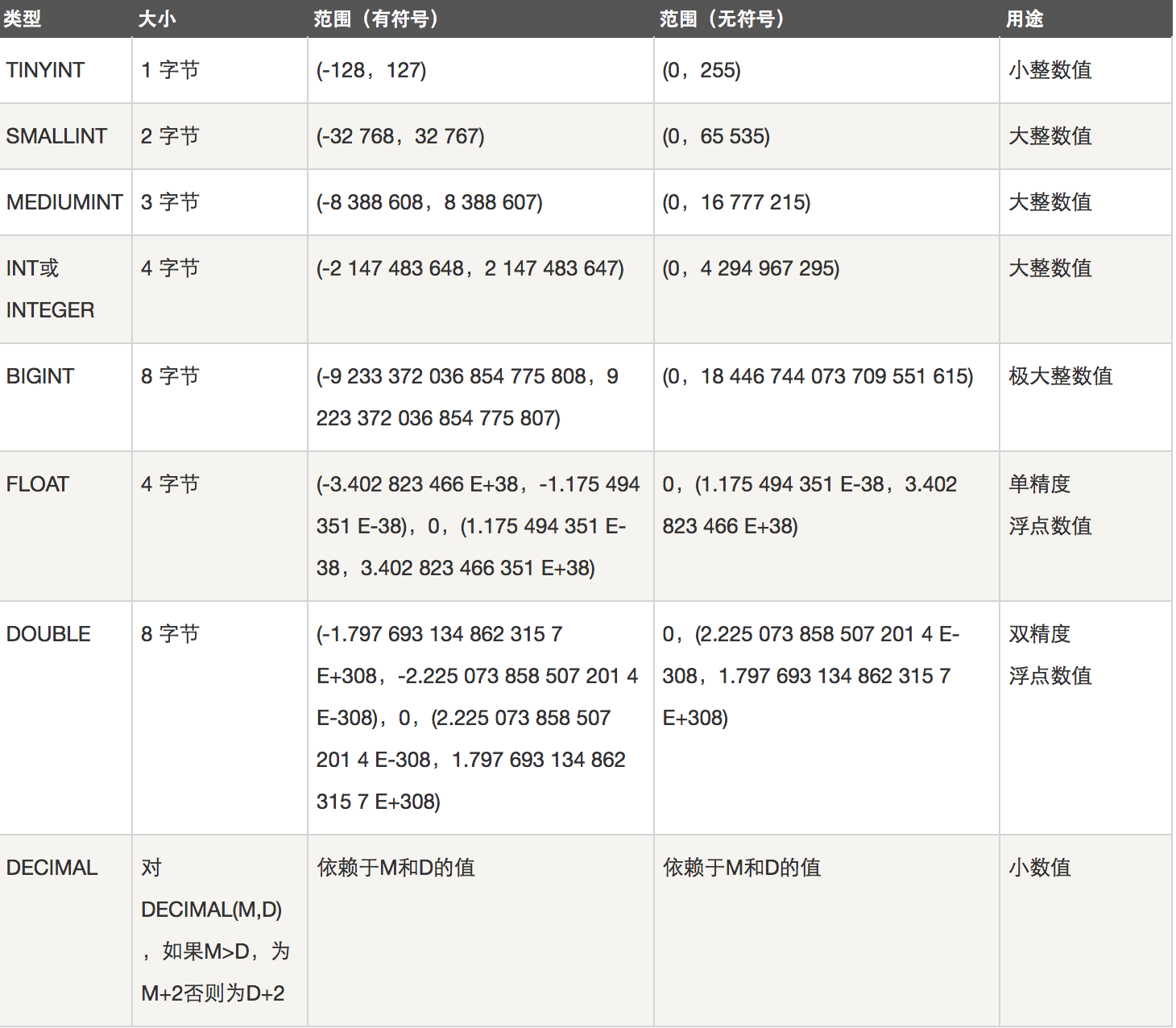
1. 整型: 存储整数的
tinyint smallint int bigint
# 不同的数据类型区别就是所存储的范围不一样
tinyint: 它是使用一个字节来保存数据,一个字节代表8位 11111111--->256种情况(0-255) (-128-127)
smallint:2个字节, 代表16位, 65536(0-65535) (-32768-32767)
mediumint: 3个字节
int: 4个字节,2**32=42....(-21...- 21...)
bigint:8个字节(最大的) 可以存手机号(11)
怎么选数据类型:看你这一列存什么数据
比如:age int
## 整型默认情况下带不带符号?
create table t5 (id tinyint);
insert into t5 values(256);
结论是:带符号的,所有的整型默认都是带符号的 减半
# 怎么样去掉符号
create table t6 (id tinyint unsigned);
2. 浮点型
float double decimal
float(255, 30) # 总位数是255位、小数点后60位
double(255, 30) # 总位数是255位、小数点后60位
decimal(65, 30) # 总位数是255位、小数点后60位
他们三个区别是什么呢?
create table t7 (id float(255, 30));
create table t8 (id double(255, 30));
create table t9 (id decimal(65, 30));
insert into t7 values (1.11111111111111111111111111);
insert into t8 values (1.11111111111111111111111111);
insert into t9 values (1.11111111111111111111111111);
结论:三者的精确度不一样:decimal >>> double >>> float(精确到7位了)
price decimal(8,2) # 999.99 # price:1000
3. 字符串(重要)
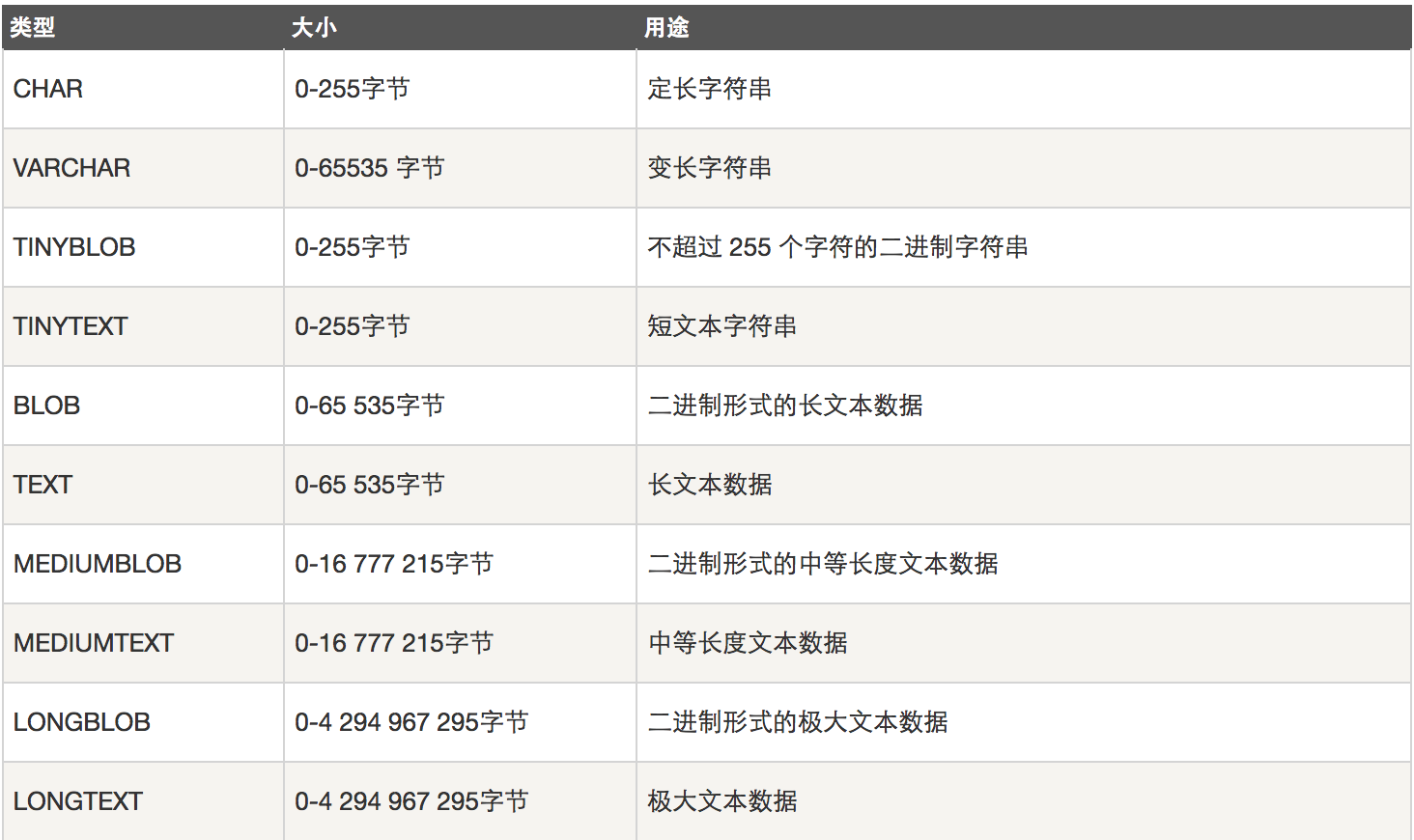
char(4): 定长类型,超出4位,就报错,不够4位,使用空格填充 abc helloworld
varchar(4): 可变长类型,超出4位,报错,不够4位的,有几位存几位 abc a
create table t10 (id int, name char(4));
create table t11 (id int, name varchar(4));
insert into t10 values(1, 'jerry');
insert into t11 values(1, 'jerry');
如果你想超出范围之后,直接报错,需要设置严格模式!!!"
sql_mode
show variables like "%mode%";
设置严格模式
1. 命令行模式:临时修改
set global sql_mode='STRICT_TRANS_TABLES'; # 不区分大小写
2. 配置文件修改:永久修改
研究定长和不定长
create table t12 (id int, name char(4));
create table t13 (id int, name varchar(4));
insert into t12 values(1, 'ke');
insert into t13 values(1, 'ke');
验证是否补充了空格
select char_length(name) from t12;
select char_length(name) from t13;
默认情况下,没有对char类型填充空格,如果想看填充了空格,需要设置严格模式"""
# 设置严格模式
1. 命令行模式:临时修改
set global sql_mode='STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH'; # 不区分大小写
2. 配置文件修改:永久修改
4. 日期
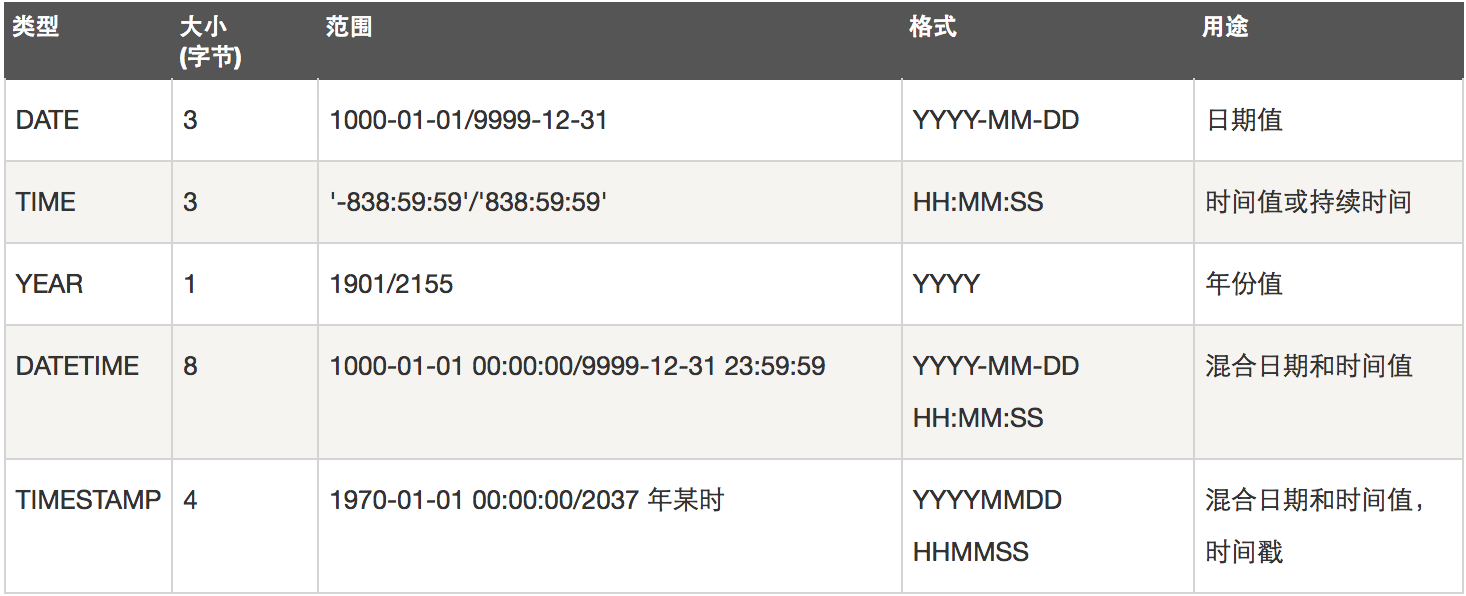
date datetime time year
年月日 年月日 十分秒 十分秒 年
create table t14 (
id int,
reg_time date,
reg1_time datetime,
reg2_time time,
reg3_time year
);
insert into t14 values(1, '2023-10-1', '2023-11-11 11:11:11', '11:11:11', 2023);
5. 枚举
# 多选一
enum
create table t15 (id int, hobby enum('read', 'music', 'tangtou', 'xijio'));
insert into t15 values(1, 'read');
# 多选多:包含多选一
set
create table t16 (id int, hobby set('read', 'music', 'tangtou', 'xijio'));
insert into t16 values(2, 'read,music1');

 浙公网安备 33010602011771号
浙公网安备 33010602011771号