
第4周小组作业:WordCountPro
小组作业,代码编写和单元测试
小组分工情况:
- 王志峰:单词统计和main函数
- 沈光远:输入模块
- 谢飞:输出模块
- 李锋:排序模块
github地址:
https://github.com/wzfhuster/software_test_tasks
psp2.1表格:
| PSP2.1 | PSP 阶段 | 预估耗时 (分钟) | 实际耗时 (分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 50 | 40 |
| Development | 开发 | 300 | 400 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 80 |
| · Design Spec | · 生成设计文档 | 40 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 29 |
| · Design | · 具体设计 | 30 | 10 |
| · Coding | · 具体编码 | 40 | 50 |
| · Code Review | · 代码复审 | 20 | 19 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 59 |
| Reporting | 报告 | 40 | 50 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 12 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 50 | 30 |
| 合计 | 772 | 470 | |
对接口的实现:
- 我负责的是核心模块单词统计和main函数的编写,在java中是wcProMain.java
- 单词统计的接口: public void wordCount(BufferedReader in, Map<String,Integer> map)
它接受由输入模块返回的一个BufferedReader的对象,用来读取文件中的内容,然后对文本中的单词统计后存入一个map中 - main函数的编写: 首先由输入模块接受一个输入文件,并且判断输入是否符合要求,如果符合要求则返回一个BufferedReader对象然后交给单词统计的模块进行单词统计,统计结果的map又交给输出模块,在输出模块中进行排序后输出到指定文件
- 对于单词统计的具体实现方法: 使用BufferedReader对象的 readLine()函数来一行一行的读取文本的内容,每读取一行内容,就
使用字符串的一个String ss[] = s.trim().split(...)方法来处理字符串,trim方法是除去字符串开头和结尾的空格
split(...)方法是用来分隔字符串的,在里面填写规定的各种分隔的符号,当得到一个ss的字符串的数组后,还要进行
一个替换的操作,因为按照要求 night-,c09这种含有-和数字的要除去,所以要遍历ss中的每个单词,使用一个替换函数
tmp = ss[i].toLowerCase().replaceAll("-|\d+",""); 这里因为还要求单词以小写的形式输出,所以有个toLowerCase
函数,replaceAll是替换函数,将所有的-和数字都替换成"",就是消除了,可能有的字符串全是-或者数字,这样处理后就会
变成空的字符串,所以最后还要有个判断,就是处理后非空的字符串才是有效单词,添加到map中,添加到map中的时候,也有个
小问题要考虑,就是该map中原来是否存在这个单词,如果不存在,就map.put(tmp, 1);,如果存在就计数器加一
map.put(tmp, map.get(tmp).intValue()+1);,最后读取文件的过程中要try catch处理异常,最后别忘了关掉流对象,具体
的代码及注释如下
单词统计的接口:
public void wordCount(BufferedReader in, Map<String,Integer> map)
{
String s;
try {
//使用readline()函数一行一行的读取文本处理
while((s = in.readLine())!=null)
{
//使用split函数来分隔字符串
String ss[] = s.trim().split("~|`|!|#|%|\\^|&|\\*|_|\\(|\\)|\\\\"
+ "|\\[|\\]|\\+|=|:|;|\"|'|\\||<|>|,|\\.|\\/|\\?"
+ "| |\n|\t");
int len = ss.length;
String tmp;
for(int i=0;i<len;i++)
{
//将单词中的-和数字等都消除掉
tmp = ss[i].toLowerCase().replaceAll("-|\\d+","");
//对于非空的字符串就加入map中
if(!tmp.trim().equals(""))
if(null==map.get(tmp))
//map中没有该单词的时候,就加入该单词,并将计数器设为1
map.put(tmp, 1);
else
//map中存在该单词的时候,就对计数器进行加一更新
map.put(tmp, map.get(tmp).intValue()+1);
}
}
} catch (IOException e) {
e.printStackTrace();
System.out.println("文件读取过程中出错!!!");
}finally {
try {
//最后别忘了要关闭获取的流对象 ! ! !
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
main函数的编写:
public static void main(String[] args) {
wcProMain wcPro = new wcProMain();
Map<String,Integer> map = new HashMap<String,Integer>();
//模块1:对输入进行处理
BufferedReader in = wcProInput.getInput(args);
//模块2:对单词词频进行统计
wcPro.wordCount(in, map);
//模块3:将单词统计结果排序后,按照要求写入指定的 result.txt 文件中
wcProOutput.output(map,"result.txt");
}
测试用例的设计
因为我负责的是单词统计模块和main函数的编写,所以我的测试用例主要针对对单词统计的正确性进行测试,我使用的是
黑盒测试,而单词统计的主要任务是统计文本中不同单词出现的频率,所以对测试用例的设计主要是针对文本中单词与各种
符号组合的各种情况来设计用例,对于一个设计好了的文本用例,我们用wordCount函数来处理后得到一个map保存了单词
及其对应的频率,最后来对比预期的结果和实际的单词统计结果,对于文本内容的各种情况如下:
- 文本的内容为空
- 文本中只有空格或者tab
- 文本中只有符号没有单词
- 文本中只有一个单词没有符号
- 文本中有一个单词和-符号
- 文本中有一个单词和-符号和其它符号
- 文本中只有一个单词和数字的组合
- 文本中有一个单词和-和数字的组合
- 文本中有多个单词没有其它符号
- 文本中有多个单词和-符号
- 本文中有多个单词和数字
- 文本中有多个单词和-符号和数字
- 文本中有多个不同的单词
- 文本中全是相同的某个单词
- 文本内容有多个单词和其它符号
- 文本内容含有大量的重复单词
- 文本中含有大量不重复的单词
- 使用有大量内容的电子书做随机测试
- 具体的测试用例截图(可以把网页放大查看!!!):
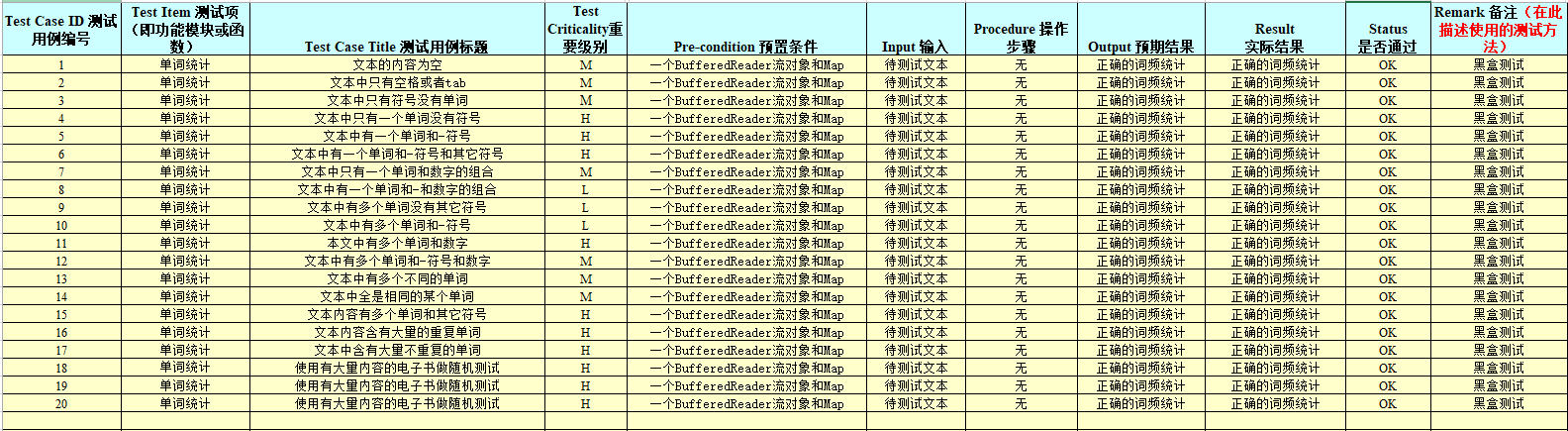
单元测试
- 单元测试的测试用例代码模式:
public class wcProMainTest {
wcProMain wcPro = new wcProMain();
Map<String,Integer> expectMap = new HashMap<String, Integer>();
Map<String,Integer> resultMap = new HashMap<String, Integer>();
//这里为了比较两个map中的内容是否相同,而重写了equals函数 !!!!!!!!!!
@Override
public boolean equals(Object obj) {
if(obj instanceof Map<?, ?>)
{
boolean flag = true;
for(String key: expectMap.keySet())
if(resultMap.get(key)==null ||
resultMap.get(key).intValue()!=expectMap.get(key).intValue())
{
flag = false;
break;
}
return flag;
}
else
return super.equals(obj);
}
//每个测试之前,要清空两个map中的内容!!!!!!!!!!!!!!!
@Before
public void setUp()
{
expectMap.clear();
resultMap.clear();
}
@Test
public void testWordCount() throws FileNotFoundException {
//testWordCount.txt中存放的是待测试的文本,具体内容如下:
/*"Are you ok"
,O-K
i am ok-34; hehe01
I AM fiNE(HaHa)!
*/
BufferedReader in = new BufferedReader(new FileReader("testWordCount.txt"));
//下面输入期待的统计结果,不用考虑添加顺序,而且文本的内容已经自动处理成了小写单词
//所以添加期待的结果都是小写字母的单词
expectMap.put("are", 1);
expectMap.put("you", 1);
expectMap.put("ok", 3);
expectMap.put("i", 2);
expectMap.put("am", 2);
expectMap.put("hehe", 1);
expectMap.put("fine", 1);
expectMap.put("haha", 1);
//测试wcProMain中的wordCout函数,将结果写入 resultMap中
wcPro.wordCount(in, resultMap);
//判断实际统计结果和预期的结果是否相同
assertEquals(expectMap, resultMap);
}
}
- 单元测试的运行截图:
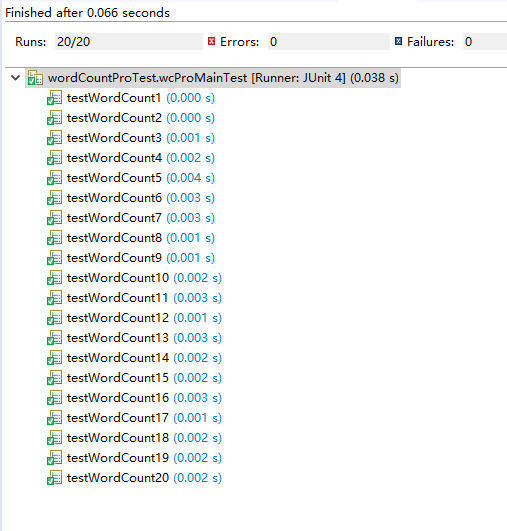
- 测试评价
由测试的结果来看目前给出的20个测试用例都已经通过了测试,测试质量还不错,被测试模块的质量基本符合要求但这不代表程序一
定正确,可能还有其它小小的问题没有被发现,之后可以增加测试情况的种类来测试程序,发现问题并修改,来增加程序的健壮性
小组贡献率
根据小组讨论,自己的贡献率约为0.40
参考文献链接
http://www.cnblogs.com/ningjing-zhiyuan/p/8654132.html
https://www.cnblogs.com/avivahe/p/5657070.html
https://blog.csdn.net/wiebin36/article/details/51912794
