
参考:https://mp.weixin.qq.com/s/p10_OVVmlcc1dGHNsYMQwA
在线学习只是一个机器学习的范式(paradigm),并不局限于特定的问题,模型或者算法。
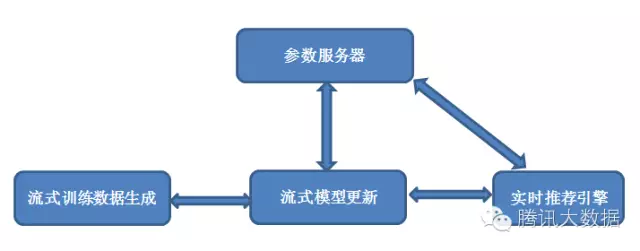
架构
如图1所示,流式训练数据生成的环节还会继续保留,原有的流式训练数据生成拓扑后面会直接接一个流式模型更新的拓扑,训练数据不是先落地HDFS然后再从HDFS加载,而是直接用于模型更新。架构中会有一个逻辑上的参数服务器用来存放模型,不同的在线学习模型和算法需要在参数服务器和流式训练拓扑中编写代码来实现特定于该模型和算法的更新方法。随着训练数据生成拓扑和模型更新拓扑的运行,参数服务器中存放的模型会得到持续不断的更新。与此同时,这样的更新也会同步给实时推荐引擎,从而立即用于线上的推荐。
可以看到,从事件(点击/曝光/转化等等)发生,到形成一条日志,再到形成一条训练数据,再到模型更新,再到用于线上推荐,整个过程都是流式的,从头到尾的平均延迟可以做到秒级。与此同时,无论是训练数据生成和模型更新两个拓扑,还是参数服务器,都具有良好的伸缩性,可以支持大规模的模型和大数据流。
模型和算法考量
正如前面提到的,可以划到在线学习这个范式里面的模型和算法有很多,而且还在不断增加。比较著名的有FTRL-Proximal[5]和AdPredictor[6],这两个都是工业界有过大规模应用的,自然是被竞相效仿的对象。关于它们的原理和实现的细节可以阅读原始文献,本系列的后续文章也会有介绍。
依个人浅见(仅供参考),这两个模型和算法代表了两大类实现在线学习的思路,这里我们粗糙地借用一下wikipedia的分类法[8]。一类是所谓的对抗学习模型(adversarial model),FTRL-Proximal可归入此类,这类模型和算法的目标是在在线的场景下最小化“后悔(regret)”。这个思路也常被称作是在线(随机)优化(online stochastic optimization)。另一类是所谓的统计学习模型(statistical learning model),按照wikipedia的说法,这类模型和算法的目标是最小化期望“风险(risk)”。然而,个人认为这个思路放到贝叶斯推理(bayesian inference)的框架下才能释放其最大价值。实际上,适用于各类概率图模型(probabilistic graph model)的贝叶斯推理算法有很多,其中不乏适用于在线学习场景的,AdPredictor就是一个例子。无论是在线(随机)优化,还是贝叶斯推理,背后都有比较完善的理论支持,且有大量的文献。作为初窥门径的实用主义者,笔者在这里斗胆提到它们,只是为了分享寻找,设计和选择在线学习模型和算法时的一点思路。
3.3 系统考量
比较著名的有FTRL-Proximal和AdPredictor,这两个都是工业界有过大规模应用的,自然是被竞相效仿的对象。这两个模型和算法代表了两大类实现在线学习的思路。一类是所谓的对抗学习模型(adversarial model),FTRL-Proximal可归入此类,这类模型和算法的目标是在在线的场景下最小化“后悔(regret)”。这个思路也常被称作是在线(随机)优化(online stochastic optimization)。另一类是所谓的统计学习模型(statistical learning model),这类模型和算法的目标是最小化期望“风险(risk)”,放到贝叶斯推理(bayesian inference)的框架下。实际上,适用于各类概率图模型(probabilistic graph model)的贝叶斯推理算法有很多,其中不乏适用于在线学习场景的,AdPredictor就是一个例子。无论是在线(随机)优化,还是贝叶斯推理,背后都有比较完善的理论支持,且有大量的文献。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号