
hashmap单向链表、红黑树、扩容
为了方便了解hashmap结构以及结构的转变过程抄了一段代码。
class MapKey{ private static final String REG = "[0-9]+"; private String key; public MapKey(String key) { this.key = key; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; MapKey mapKey = (MapKey) o; return !(key != null ? !key.equals(mapKey.key) : mapKey.key != null); } /* * 确保每次key的hashCode都相同 */ @Override public int hashCode() { if (key == null) return 0; Pattern pattern = Pattern.compile(REG); if (pattern.matcher(key).matches()) return 1; else return 2; } @Override public String toString() { return key; } }
这个类重写了hashcode方法保证规则:数字的hash值是1,else为2,null的hash为0。实现hash碰撞。
观察hashmap的结构转变。
public static void main(String[] args){ Map<MapKey,String> map = new HashMap<MapKey, String>(); //第一阶段 for (int i = 0; i < 6; i++) { map.put(new MapKey(String.valueOf(i)), "A"); } //第二阶段 for (int i = 0; i < 10; i++) { map.put(new MapKey(String.valueOf(i)), "A"); } //第三阶段 for (int i = 0; i < 50; i++) { map.put(new MapKey(String.valueOf(i)), "A"); } //第四阶段 map.put(new MapKey("Z"), "B"); map.put(new MapKey("J"), "B"); map.put(new MapKey("F"), "B"); System.out.println(map); }
每个阶段的hashmap结构在下面详细分析。
HashMap在jdk1.8数据结构为 数组+单向链表/红黑树。学习一下。
数组是 Node<K,V>[] 实际上是Entry数组table。
看源码、看结构。
/** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table;
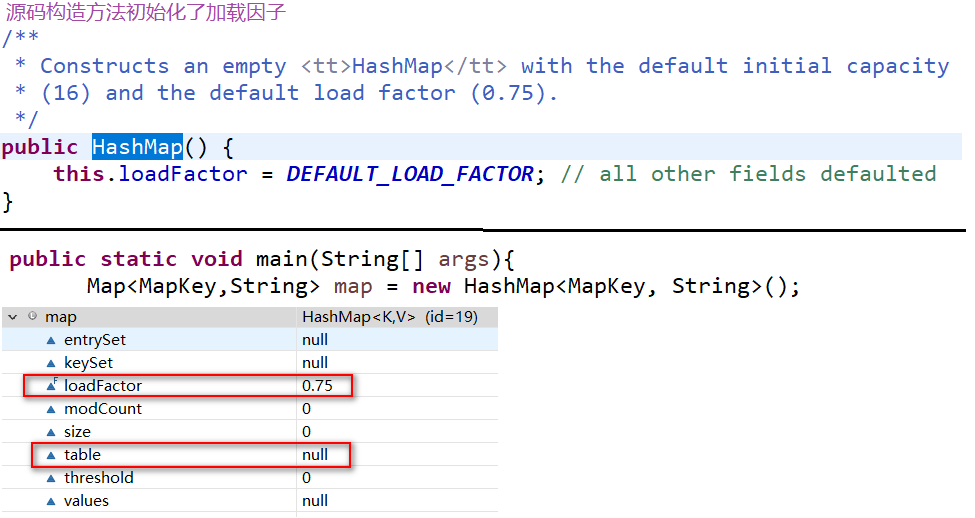
上面代码初始化完成之后,构造方法初始化了加载因子。table数组还是空的。之后put值进去。。
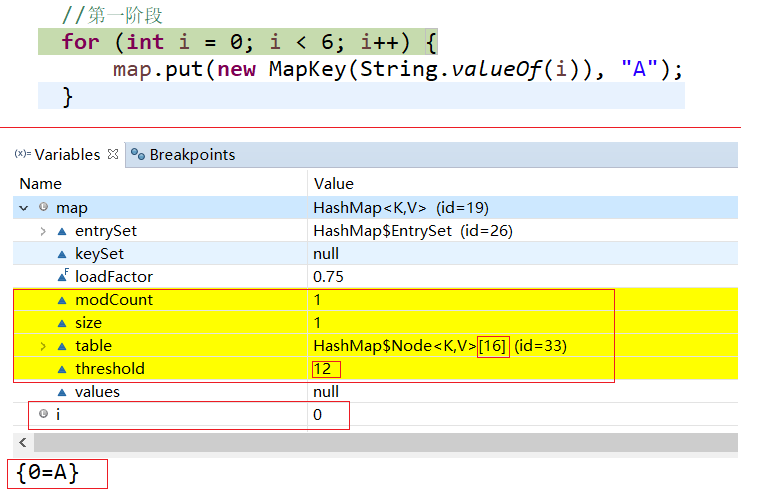
上面是for循环运行第一次之后的变化,modeCount表示hashMap更改了一次,对应 i=0,时的数据key=0,value=A。size也变为了1,给定了默认的容量16。阈值threshold为12,具体 threshold = loadFactor*容量。而且线性表table也有值,默认容量为16。

put第一个值进去时,看一下HashMap put 方法源码(jdk1.8)。

put方法针对key进行了hash运算(hashmap中hash方法对其进行了高位运算,暂时先不看)调用了putVal方法,继续往下走,看putVal方法在第一次调用put进值。
putVal方法分了三种情况:
①判断table是否为空,为则扩容;
②根据length对key的hash取模,计算当前key的桶中是否有为空,为空则创建;
③table不为空,当前key的桶不为空,为链表;
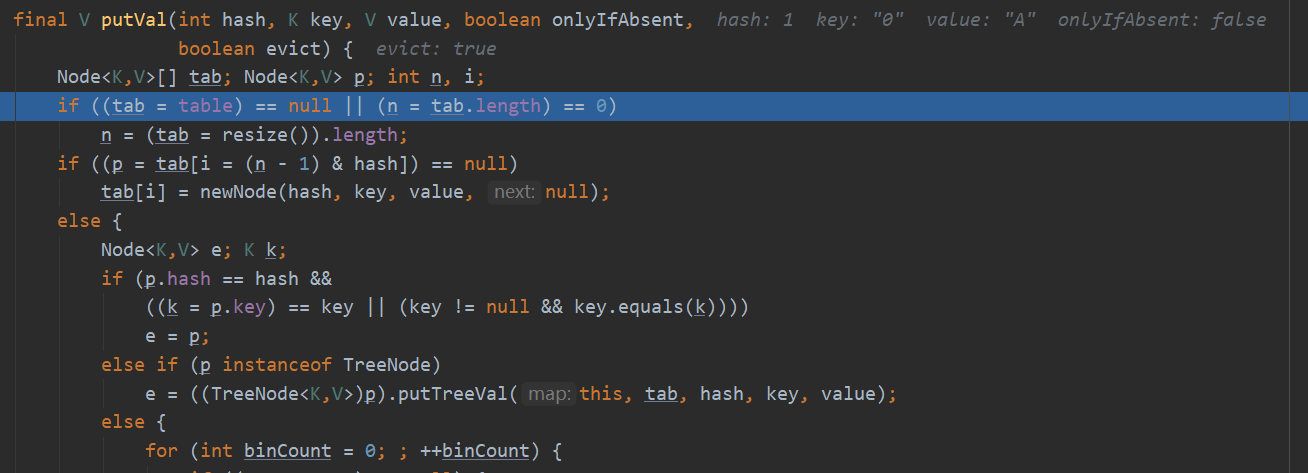
目前是put第一个值进入HashMap中,table为空,符合第一个,创建存储v的node。继续走进入resize方法。
resize() 方法有总的分为两部分:
①扩容;
②数据迁移;
扩容和数据迁移都需要进行相应条件的判断,遇到细看。目前(put进去第一个值)table是空的,除了加载因子其他所有属性都是空的。

当第一次初始化调用resize()方法时:(判断容量和阈值)
扩容:在resize方法中会给容量、阈值赋以默认值16、16*0.75=12。
数据迁移:容量为0不需要数据迁移。
回到putval方法中,根据容量判断当前key的hash桶(index)中是否为空,为空则创建。
![]()
上面是将key,value放到了table数组的第i个元素中。这里是通过(n-1)&hash运算确定下标的位置的,类似取模运算,n的值是2的次幂。完成put值。
继续往下执行
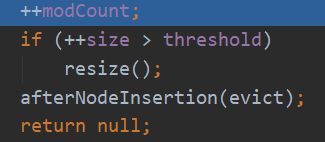
modCount自增1,modCount字段主要用来记录HashMap内部结构发生变化的次数,put新键值对,但是某个key对应的value值被覆盖不属于结构变化。在putval源码中就可以看到:在对key对应的value进行覆盖时,直接return不会到++modCount这一步。
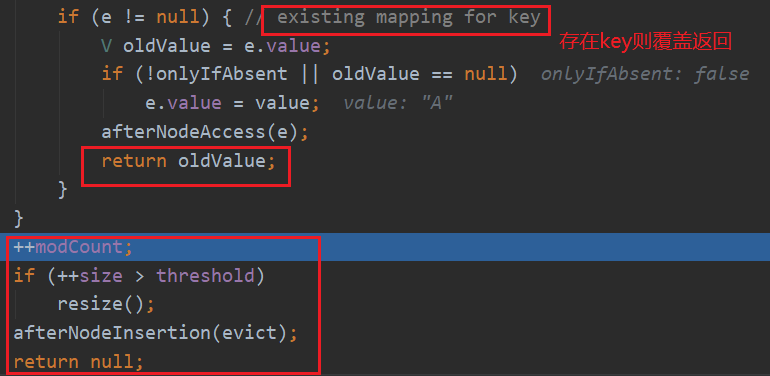
我们知道java.util.HashMap不是线程安全的,因此在使用迭代器Iterator的过程中,如果有其他线程修改了map,将抛出ConcurrentModificationException,这就是所谓fail-fast策略。这一策略在源码中的实现就是通过modCount,它记录修改次数,在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount,在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map。所以遍历那些非线程安全的数据结构时,尽量使用迭代器Iterator。
根据size大小判断是否需要扩容,resize()方法。第一次put时不需要扩容直接返回。第一次put值进HashMap结束。
put第二个值进去时,看一下HashMap put 方法源码
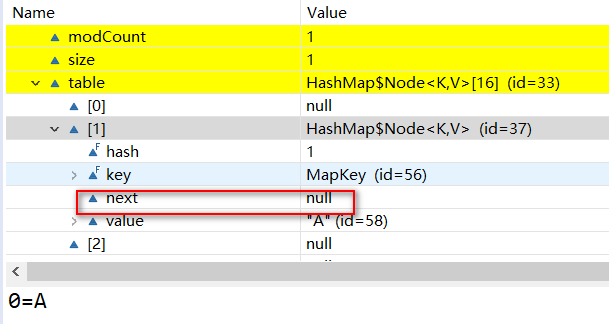
此时在table[1]的位置有了Node<k,v>类型的值,容量是16阈值时12。进入hashmap源码看put方法:
①判断table为空,此时不为空跳过;
②判断当前key对应table[index]有值,不用创建新的Node跳过;
③进入else,判断当前key在HashMap中是否有重复的,有则覆盖。这里判断key值用的是hash 和 equals方法进行判断。此时没有重复的key跳过;
④判断是不是红黑树,此时不是跳过;
⑥确定是链表结构,for循环遍历:末尾插入,大于阈值则红黑树化,key重复则覆盖。
此时末尾插入,通过循环找到next指向为空的节点,将值插入到为空的next节点中,同时判断长度是否超过阈值,超过则树化。
table数组容量为16,以key的hash值为下标的。第一次for循环put进去的key是数字,上面重写hashcode的方法对数字返回的hash值为1。
table中存储的是Node,而Node中还又存了个Node类型的next。通过next指向下一个Node。所以table数组中存了类似于套娃的Node的单向链表。
看源码和结构样子。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; }
现在只有一个Node,指向下一个Node的next为空。
再执行一次for循环put值进去,下图
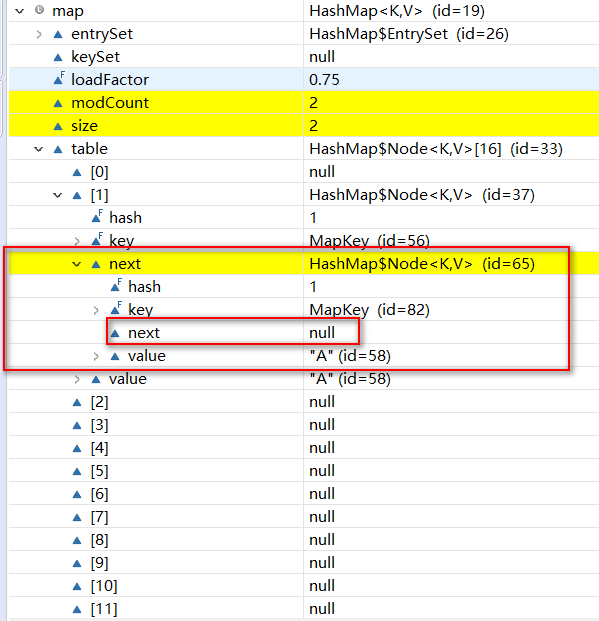
第一个node的next现在已经有值,指向第二个Node对象,而第二个Node的next没有指向任何Node。开始了套娃。
这样构成链表结构,结构下图:参考博客
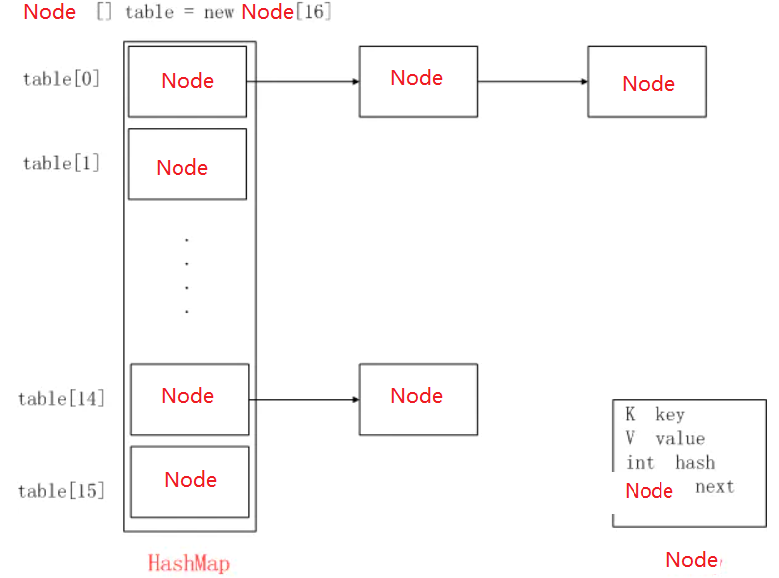
套娃的单向链表就是这样。
HashMap中对于单向链表的套娃行为加以了限制,TREEIFY_THRESHOLD & MIN_TREEIFY_CAPACITY稍后细看。
随着put值的进行,学习一下HashMap的自动扩容,树化。扩容过程是通过resize方法进行的,但是现在还没看懂先看看过程。
阶段一for循环put进去了6个值,此时HashMap的结构还是数组加单向链表的套娃结构。如下图
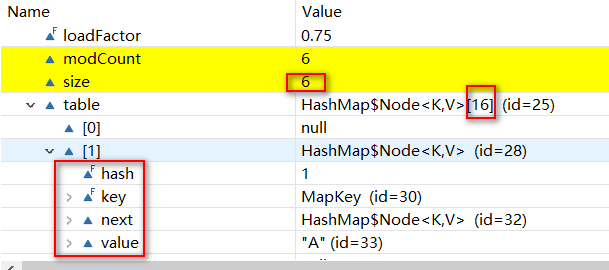
等单向链表长度达到TREEIFY_THRESHOLD=8时,put值进去时并没有进行红黑树化,还是链表套娃结构。这是因为HashMap的容量没达到最小容量 MIN_TREEIFY_CAPACITY= 64。如下图
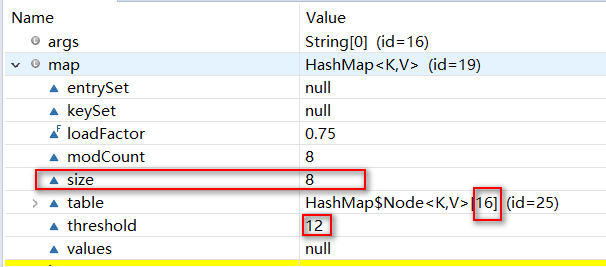
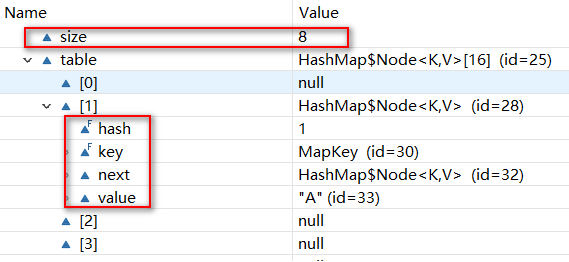
此时HashMap开始扩容(虽然容量没有达到阈值threshold,但是还是进行了扩容。可能是为了整治套娃行为(单向链表),努力达到条件 -->TREEIFY_THRESHOLD & MIN_TREEIFY_CAPACITY),直到容量达到64之前,一直都是单向链表的套娃结构。如图
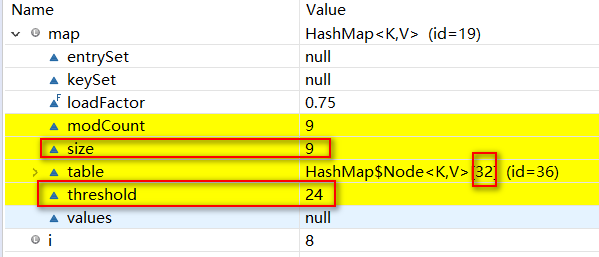

等到容量达到64时再put进值时就会转为红黑树(此时链表长度早已超过8)。如图
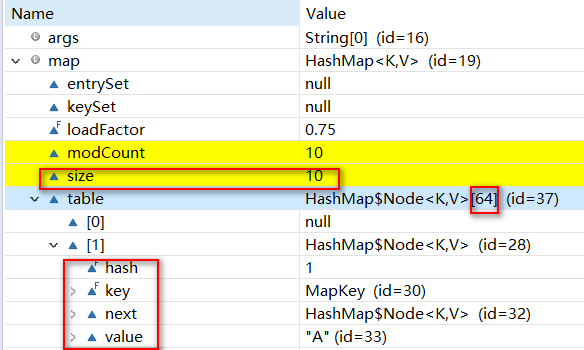
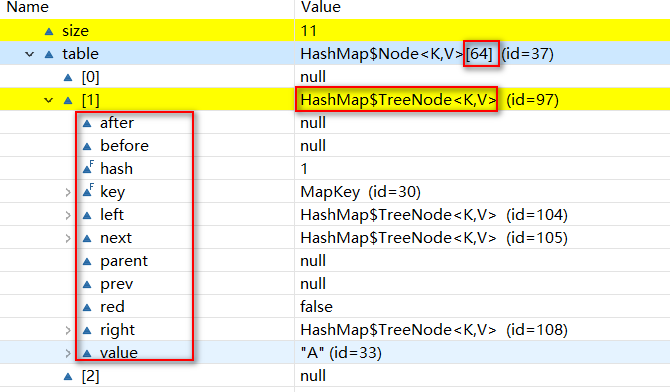
此时扩容将会等达到阈值时才会扩容。如图
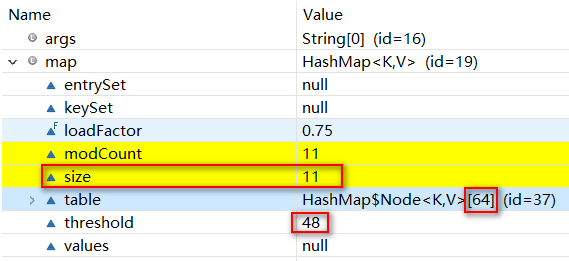
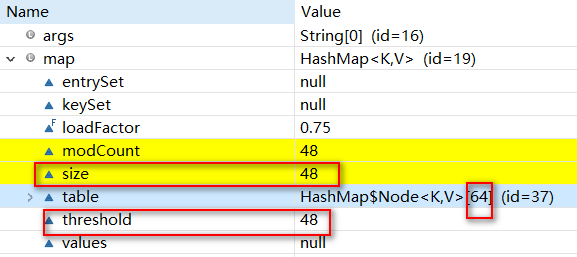

TODO红黑树还没懂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号