


2017-2018-1 20179205《Linux内核原理与设计》第六周作业
《Linux内核原理与设计》
视频学习及操作
给MenuOS增加time和time-asm命令的方法:
1、更新menu代码到最新版
rm menu -rf //强制删除menu, rm -rf 表示强制删除的意思。
git clone 网址 //克隆一个新的menu,这样就使得menu的代码更新到最新版
2、在main()函数中增加MenuConfig
3、增加对应的Time函数和TimeAsm函数(这里的函数要换成我们自己编写的使用系统调用的函数,比如mkdir和mkdirAsm)
4、make rootfs (帮我们自动编译、生成根文件系统,同时自动帮我们启动起来Menuos,这时我们发现menu支持的命令比原来多)
使用gdb跟踪系统调用内核函数sys_time
.编辑 menu 中的 text.c 文件,把上周作业写的fork和fork_asm写在menuos里面:
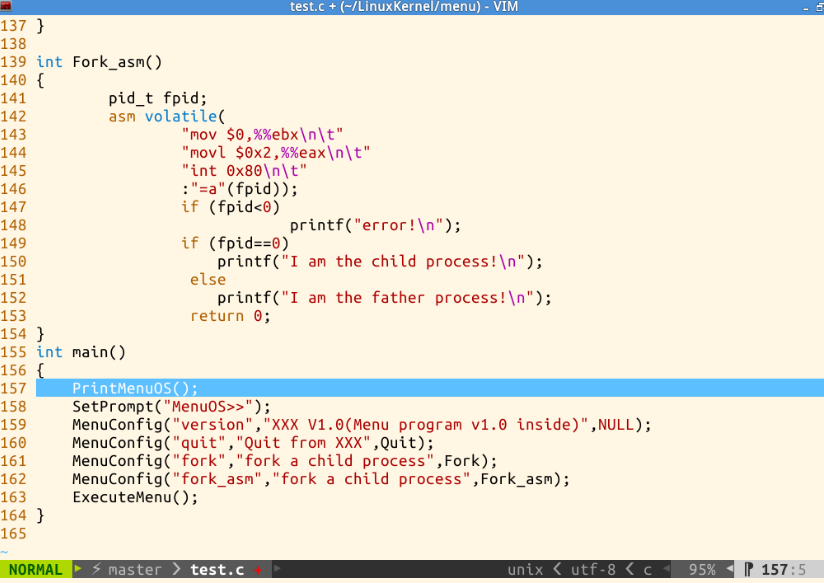
make rootf 打开 menu 镜像,输入help可以看到MenuOS菜单中新增了两条命令:
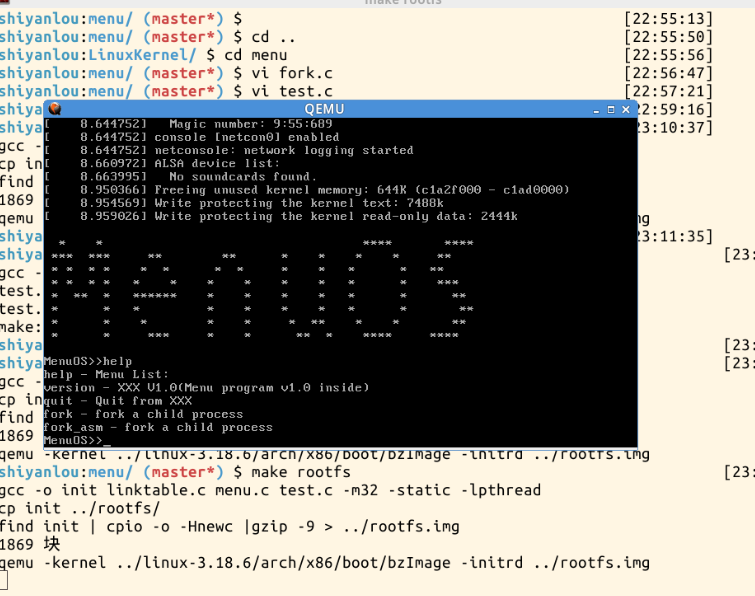
接下来开始用gdb调试:
cd LinuxKernel
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
水平分割
gdb
file linux-3.18.6/vmlinux //加载内核
target remote:1234 //链接到menu os里
b start_kernel //在start_kernel处设置断点
c //继续执行
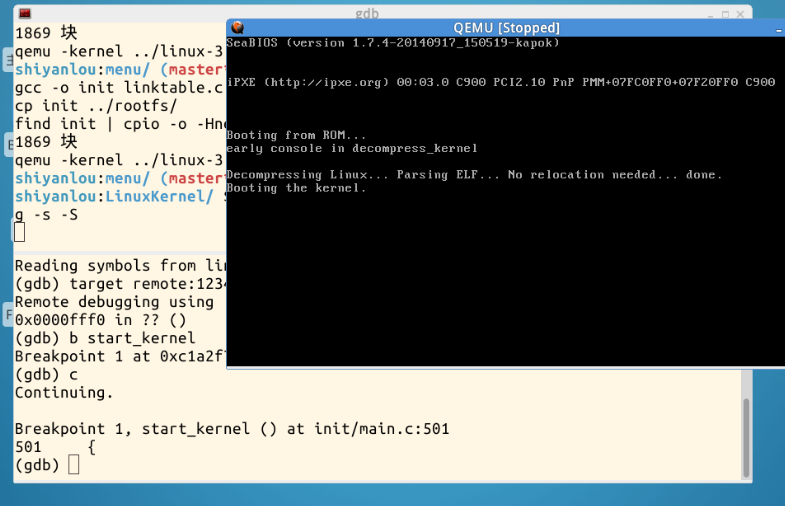
接下来设置断点,启动MenuOs,输入mkdir,看gdb调试结果:
list //查看startkernel这段代码
b sys_mkdir //在要分析的这个系统调用处设置断点
c //继续执行
c
c
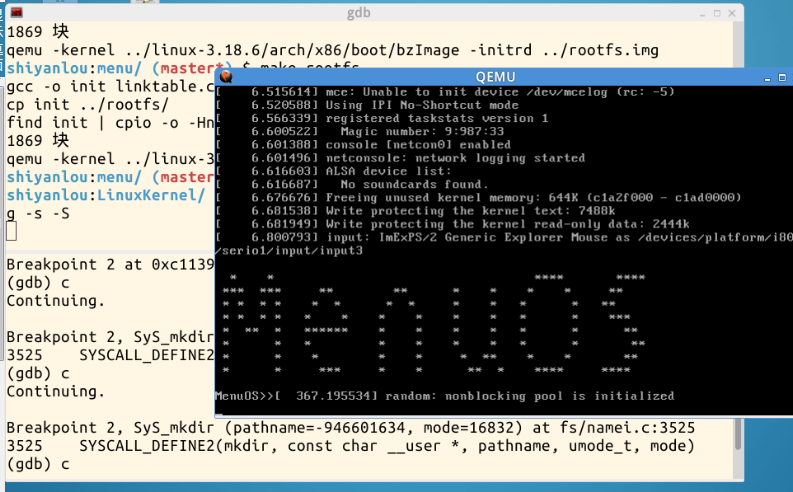
b sys_time 一个 断点,按 c 继续执行 time 命令,发现进入系统调用后会停在sys_time这个函数
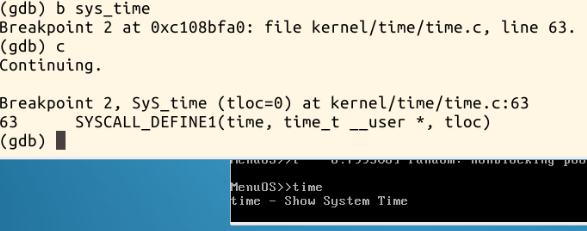
关于从system_call到iret之间的过程
从保存现场到恢复现场,画了一个流程图大致如下:
教材第九、十章学习
1、链表中每个结点代表一个请求。线程持有锁,而锁保护了数据。各种锁机制之间的区别主要在于,当锁已经被其他线程持有而不可用时,一些锁会执行等待,另一些会使当前任务睡眠知道锁可用。互斥锁mutex中,0意味着开锁,1意味着上锁。
2、伪并发执行是指单线程的多个进程共享文件,或者在一个程序内部处理信号,也可能产生竞争条件,但两者其实并不是同时发生的,它们相互交叉进行;真并发是指在一台支持对称多处理器的的机器上,两个进程真正的在临界区中同时执行。内核中产生并发执行的原因来自于中断、软中断和tasklet、内核抢占、睡眠及与用户空间的同步、对称多处理。
3、为什么要上锁呢?是怕其他执行线程可以访问这些数据,避免什么其他什么东西都能看到他,就要上锁,如果是局部数据,仅仅被它本身访问,它们独立存在于执行线程的栈中,纳闷就不需要给这些局部变量加锁。
4、如果有一个或多个执行线程和一个或多个资源,每个线程都在等待其中的一个资源,但所有资源都已被占用,所有线程都在相互等待,且它们永远不会释放已占有的资源,这就是死锁。死锁的例子有很多,自死锁,ABBA死锁等,要避免死锁,就要按顺序加锁(嵌套的使用多个锁)、防止发生饥饿、不要重复请求同一个锁、设计应力求简单。恰当的加锁既要满足不死锁,可扩展,还要清晰简洁,加锁的精髓在于力求简单。
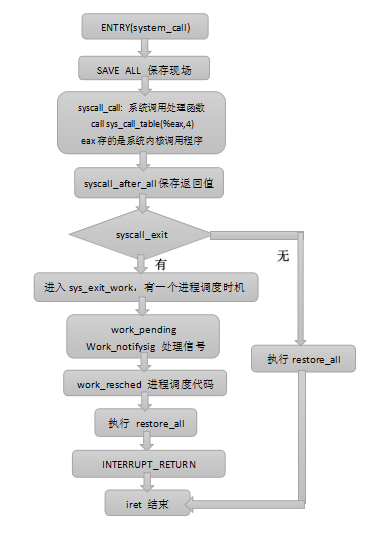
5、在内核同步方法中,主要介绍了11种内核同步方法,同步的目的就是为了保障数据的安全,其实就是保障各个线程之间共享资源的安全。其中大内核锁(BLK)是内核的原始混沌时期,应用不多,因此我们主要学习另外十种内核同步方法。
10.1 原子操作
原子操作是由编译器来保证的,用于临界区只有一个变量的情况,只有一个整数,保证一个线程对数据的执行过程不会被其他线程打断。原子操作有2类:
1、原子整数操作,有32位和64位,头文件分别为<asm/atomic.h>和<asm/atomic64.h>
2、原子位操作,头文件 <asm/bitops.h>
10.2 自旋锁
自旋锁是Linux中最常见的锁,它最多只能被一个可执行线程持有,如果一个执行线程试图获得一个已被持有的自旋锁,则该线程会一直进行忙循环-旋转-等待锁重新可用。由于处于等待状态的线程在等待锁重新可用时自旋,特别浪费CPU时间,因此自旋锁不应该被某一线程长时间持有。它的头文件为<asm/spinlock.h>
警告:
1、自旋锁是不可递归的,否则递归的请求同一个自旋锁会自己锁死自己。
2、线程获取自旋锁之前,要禁止本地中断,否则中断处理程序就会打断正持有锁的内核代码,且有可能和获取锁的线程竞争自旋锁。
自旋锁和下半部:
1、下半部处理和进程上下文共享数据时,由于下半部的处理可以抢占进程上下文的代码,所以进程上下文在对共享数据加锁前要禁止下半部的执行,解锁时再允许下半部的执行。
2、中断处理程序(上半部)和下半部处理共享数据时,由于中断处理(上半部)可以抢占下半部的执行,所以下半部在对共享数据加锁前要禁止中断处理(上半部),解锁时再允许中断的执行。
3、同一种tasklet不能同时运行,所以同类tasklet中的共享数据不需要保护。
4、对于软中断,无论同种类型,如果数据被软中断共享,那它必须得得到锁的保护,但是同一处理器上一个软中断不会抢占另一个软中断,因此不需要禁止下半部。
10.3 读-写自旋锁
读写自旋锁方面,本周四课上已经讲过,读和读是不互斥的,其余的读和写,写和写之间都是互斥的。
10.4 信号量
信号量也是一种睡眠锁,和自旋锁不同的是,线程获取不到信号量的时候,不会像自旋锁一样循环的去试图获取锁,而是进入睡眠,直至有信号量释放出来时,才会唤醒睡眠的线程,进入临界区执行,所以信号量适用于等待时间较长的临界区。信号量有二值信号量和计数信号量2种,其中二值信号量比较常用。
二值信号量表示信号量只有2个值:信号量为1时,表示临界区可用;信号量为0时,表示临界区不可访问。
10.5 读-写信号量
读写信号量都是二值信号量(互斥信号量),即计数值最大为1,增加读者时,计数器不变,增加写者,计数器才减一,也就是说读写信号量保护的临界区,最多只有一个写者,但可以有多个读者。
10.6 互斥体
内核中唯一允许睡眠的锁是信号量。mutex在内核中对应的数据结构mutex,其行为和使用计数为1的信号量相似,但操作接口更简单,实现也更高效,且使用限制更强,因此首选mutex,除非不能满足其约束条件。
10.7 完成变量
完成变量是使两个任务得以同步的简单方法,完成变量的机制类似于信号量,如果一个线程要执行工作时,另一个线程会在完成变量上等待;当线程完成了工作之后,使用完成变量来唤醒等待的任务。
完成变量的头文件:<linux/completion.h>
10.9 顺序锁
通常简称seq锁,与自旋锁和读写信号量不同,顺序锁用于读写共享数据。
10.10 禁止抢占
自旋锁虽然可以防止内核抢占,但是有时候仅仅需要禁止内核抢占,不需要像自旋锁那样连中断都屏蔽掉,这时可以使用禁止内核抢占的方法。禁止抢占的头文件为<linux/preempt.h>
10.11 顺序和屏障
对于一段代码,编译器或者处理器在编译和执行时可能会对执行顺序进行一些优化,从而使得代码的执行顺序和我们写的代码有些区别。在并发条件下,可能会出现取得的值与预期不一致的情况,因此为了保证代码的执行顺序,引入了一系列屏障方法来阻止编译器和处理器的优化。
参考网址:内核同步处理方法
问题与思考
教材第九章提到要给数据加锁而不是给代码加锁,而第九章P140的总结却说要加锁的是代码?我的理解是通过编代码的方式,给数据进行加锁,P140的说法是不是不太准确

 浙公网安备 33010602011771号
浙公网安备 33010602011771号