快速掌握mongoDB(二)——聚合管道和MapReduce
上一节简单介绍了一下mongoDB的增删改查操作,这一节将介绍其聚合操作。我们在使用mysql、sqlserver时经常会用到一些聚合函数,如sum/avg/max/min/count等,mongoDB也提供了丰富的聚合功能,让我们可以方便地进行数据的分析和计算。这里主要介绍两种聚合方式:聚合管道和MapReduce.
1 聚合管道
官网文档:https://docs.mongodb.com/manual/core/aggregation-pipeline/
聚合管道(aggregation pipeline),顾名思义是基于管道模式的聚合框架,简单的说就是在聚合管道中前一个阶段处理的结果会作为后一阶段处理的输入,documents通过管道中的各个阶段处理后得到最终的聚合结果。聚合管道的语法: db.aggregate( [ { stage1 },{ stage2} ... ] ) 。
我们看一个官网提供的栗子就理解了:
//准备测试数据 db.orders.insertMany([ {cust_id:"A123",amount:500,status:"A"}, {cust_id:"A123",amount:250,status:"A"}, {cust_id:"B212",amount:200,status:"A"}, {cust_id:"A123",amount:300,status:"D"} ]) //聚合操作 db.orders.aggregate([ {$match:{status:"A"}}, {$group:{_id:"$cust_id",total:{$sum:"$amount"}}} ])
执行上边的命令,结果如下:
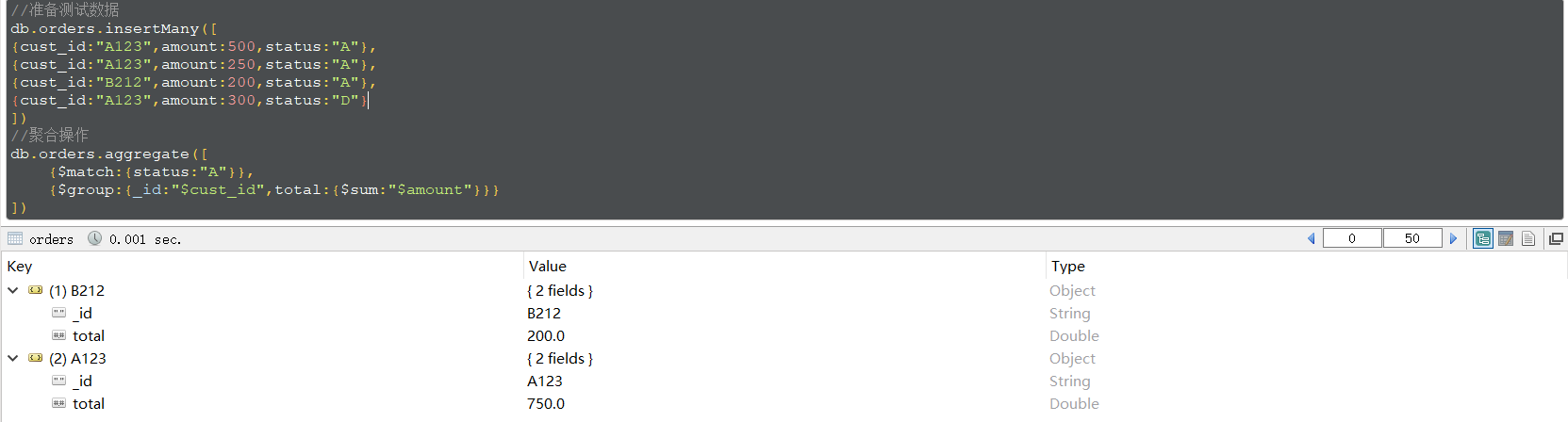
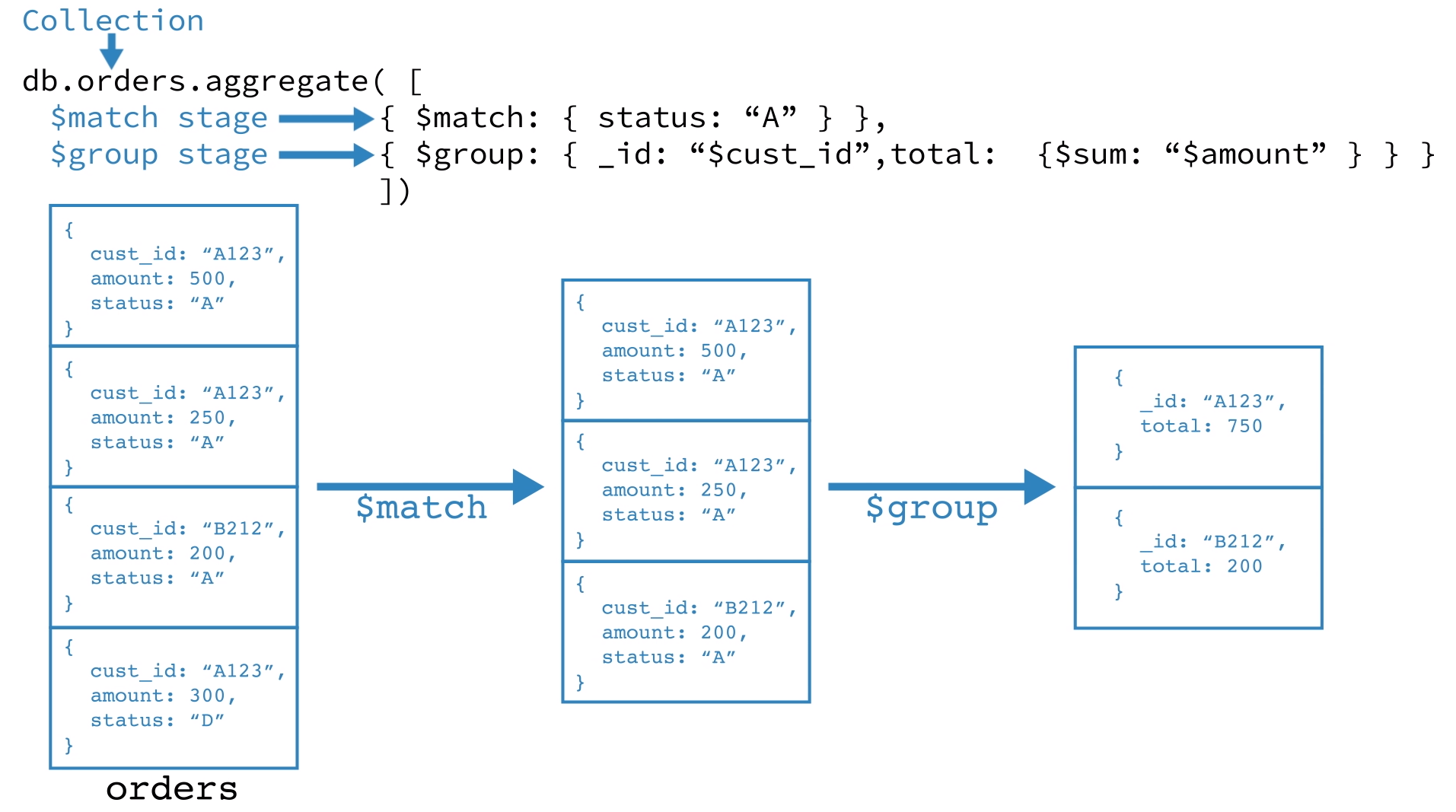
上边的聚合过程一共有两个阶段,如下图所示:
第一阶段:$match会筛选出status="A"的documents,并把筛选出的document传给下一个阶段;
第二阶段:$group将上一阶段传过来的documents通过cust_id进行分组,并合计各组的amount。
通过官网的栗子我们大概知道了集合管道的基本执行流程,下边我们通过几个栗子来理解几个常用的聚合运算符。
栗子1:$lookup,$match,$project,$group,$sort,$skip,$limit,$out
首先看一个订单库存的栗子,我们将分步查看各个阶段的聚合结果:
////准备测试数据 //订单 db.orders.insertMany([ { "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2 }, { "_id" : 2, "item" : "bread", "price" : 8, "quantity" : 3 }, { "_id" : 3, "item" : "pecans", "price" : 20, "quantity" : 1 }, { "_id" : 4, "item" : "pecans", "price" : 20, "quantity" : 3 }, { "_id" : 5, "item" : "cashews", "price" : 25, "quantity" :2}, { "_id" : 6 } ]) //库存 db.inventory.insertMany([ { "_id" : 1, "sku" : "almonds", description: "product 1", "instock" : 120 }, { "_id" : 2, "sku" : "bread", description: "product 2", "instock" : 80 }, { "_id" : 3, "sku" : "cashews", description: "product 3", "instock" : 60 }, { "_id" : 4, "sku" : "pecans", description: "product 4", "instock" : 70 }, { "_id" : 5, "sku": null, description: "Incomplete" }, { "_id" : 6 } ]) db.orders.aggregate([ //$lookup实现collection连接,作用类似于sql中的join { $lookup: { from: "inventory",//要join的集合 localField: "item",//连接时的本地字段 foreignField: "sku",//连接时的外部字段 as: "inventory_docs"//连接后添加数组字段的名字 } }, //$match过滤document,结果集合只包含符合条件的集合 {$match: {price:{$gt:0}} }, //$project用于获取结果字段,可以新增字段;也可以对已存在的字段重新赋值 { $project:{ _id:0, item:1, price:1, quantity:1, totalprice:{$multiply:["$price","$quantity"]} } }, //$group实现分组,_id是必须的,用于指定分组的字段;这里查询各个分组的totalprice的最大值 { $group:{_id:"$item",maxtotalprice:{$max:"$totalprice"}} }, //$sort用于排序,1表示正序,-1表示倒序 {$sort:{maxtotalprice:-1}}, //$skip用于跳过指定条数的document,和linq中的skip作用一样 {$skip:1}, //limit用于指定传递给下一阶段的document条数,和mysql的limit作用一样 {$limit:2}, //$out用于将结果存在指定的collection中,如果collection不存在则新建一个,如果存在则用结果集合覆盖以前的值 {$out:"resultCollection"} ])
$ lookup阶段 用于collection连接,作用类似于sql中的join,经过该阶段结果如下:


[ { "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2, "inventory_docs" : [ { "_id" : 1, "sku" : "almonds", "description" : "product 1", "instock" : 120 } ] }, { "_id" : 2, "item" : "bread", "price" : 8, "quantity" : 3, "inventory_docs" : [ { "_id" : 2, "sku" : "bread", "description" : "product 2", "instock" : 80 } ] }, { "_id" : 3, "item" : "pecans", "price" : 20, "quantity" : 1, "inventory_docs" : [ { "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 } ] }, { "_id" : 4, "item" : "pecans", "price" : 20, "quantity" : 3, "inventory_docs" : [ { "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 } ] }, { "_id" : 5, "item" : "cashews", "price" : 25, "quantity" : 2, "inventory_docs" : [ { "_id" : 3, "sku" : "cashews", "description" : "product 3", "instock" : 60 } ] }, { "_id" : 6, "inventory_docs" : [ { "_id" : 5, "sku" : null, "description" : "Incomplete" }, { "_id" : 6 } ] } ]
$match阶段 用于筛选出符合过滤条件的documents,相当于sql中的where
[ { "_id" : 1, "item" : "almonds", "price" : 12, "quantity" : 2, "inventory_docs" : [ { "_id" : 1, "sku" : "almonds", "description" : "product 1", "instock" : 120 } ] }, { "_id" : 2, "item" : "bread", "price" : 8, "quantity" : 3, "inventory_docs" : [ { "_id" : 2, "sku" : "bread", "description" : "product 2", "instock" : 80 } ] }, { "_id" : 3, "item" : "pecans", "price" : 20, "quantity" : 1, "inventory_docs" : [ { "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 } ] }, { "_id" : 4, "item" : "pecans", "price" : 20, "quantity" : 3, "inventory_docs" : [ { "_id" : 4, "sku" : "pecans", "description" : "product 4", "instock" : 70 } ] }, { "_id" : 5, "item" : "cashews", "price" : 25, "quantity" : 2, "inventory_docs" : [ { "_id" : 3, "sku" : "cashews", "description" : "product 3", "instock" : 60 } ] } ]
$project阶段 用于设置查询的字段,想到于sql中的select field1,field2...
[ { "item" : "almonds", "price" : 12, "quantity" : 2, "totalprice" : 24 }, { "item" : "bread", "price" : 8, "quantity" : 3, "totalprice" : 24 }, { "item" : "pecans", "price" : 20, "quantity" : 1, "totalprice" : 20 }, { "item" : "pecans", "price" : 20, "quantity" : 3, "totalprice" : 60 }, { "item" : "cashews", "price" : 25, "quantity" : 2, "totalprice" : 50 } ]
$group 用于分组,相当于sql中的group by,经过该阶段结果如下:
[ { "_id" : "cashews","maxtotalprice" : 50}, { "_id" : "pecans","maxtotalprice" : 60}, { "_id" : "bread", "maxtotalprice" : 24}, { "_id" : "almonds","maxtotalprice" : 24} ]
$sort阶段 用于排序,相当于sql中的 sort by,其中值为1表示正序,-1表示反序,经过该阶段结果如下:
[ { "_id" : "pecans","maxtotalprice" : 60}, { "_id" : "cashews","maxtotalprice" : 50}, { "_id" : "bread", "maxtotalprice" : 24}, { "_id" : "almonds","maxtotalprice" : 24} ]
$skip阶段 用于跳过指定条数的document,和linq中的skip作用一样,经过该阶段结果如下:
[ { "_id" : "cashews", "maxtotalprice" : 50}, { "_id" : "bread","maxtotalprice" : 24}, { "_id" : "almonds", "maxtotalprice" : 24} ]
$limit阶段 用于指定传递给下一阶段的document条数,相当于mysql中的limit,和linq中的take作用一样,经过该阶段结果如下:
[ {"_id" : "cashews","maxtotalprice" : 50}, {"_id" : "bread","maxtotalprice" : 24} ]
$out阶段,用于将结果存在指定的collection中,如果collection不存在则新建一个,如果存在则用结果集合覆盖以前的值,这里我们将 db.resultCollection.find() 查看resultCollection,结果如下:
[ { "_id" : "cashews", "maxtotalprice" : 50}, { "_id" : "bread", "maxtotalprice" : 24} ]
栗子2:$addFields,$unwind,$count
看一个用户分析的栗子,添加测试数据:
//测试数据 db.userinfos.insertMany([ { _id:1, name: "王五", age: 25, roles:["vip","gen" ]}, { _id:2, name: "赵六", age: 26, roles:["vip"]}, { _id:3, name: "田七", age: 27} ])
$addFields 用于给所有的document添加新字段,如果字段名已经存在的话,用新值替代旧值
db.userinfos.aggregate([
{$addFields:{address:'上海',age:30}}
])
执行上边的命令后,结果如下:
[{"_id":1,"name":"王五","age":30,"roles":["vip","gen"],"address":"上海"},
{"_id":2,"name":"赵六","age":30,"roles":["vip"],"address":"上海"},
{"_id":3,"name":"田七","age":30,"address":"上海"}]
$unwind $unwind用于对数组字段解构,数组中的每个元素都分解成一个单独的document
db.userinfos.aggregate([ {$unwind:"$roles"} ])
执行命令后,结果如下:
[{"_id" : 1,"name" : "王五","age" : 25,"roles" : "vip"},
{"_id" : 1,"name" : "王五","age" : 25,"roles" : "gen"},
{"_id" : 2,"name" : "赵六","age" : 26,"roles" : "vip"}]
$count 用于获取document的条数,输入的值为字段名字,用法十分简单
db.userinfos.aggregate([ {$count:"mycount"} ])
执行命令后,结果如下:
[ { "mycount" : 3 } ]
栗子3 $bucket,$bucketAuto,$sample
看一个网上书店的栗子,首先添加测试数据:
db.books.insertMany([ { "_id" : 1, "title" : "《白鲸》", "artist" : "赫尔曼・梅尔维尔(美)", "year" : 1845,"price" : NumberDecimal("199.99") }, { "_id" : 2, "title" : "《忏悔录》", "artist" : "让・雅克・卢梭(法)", "year" : 1782,"price" : NumberDecimal("280.00") }, { "_id" : 3, "title" : "《罪与罚》", "artist" : "陀斯妥耶夫斯基(俄)", "year" : 1866,"price" : NumberDecimal("76.04") }, { "_id" : 4, "title" : "《复活》", "artist" : "列夫・托尔斯泰(俄)","year" : 1899,"price" : NumberDecimal("167.30") }, { "_id" : 5, "title" : "《九三年》", "artist" : "维克多・雨果(法)", "year" : 1895,"price" : NumberDecimal("483.00") }, { "_id" : 6, "title" : "《尤利西斯》", "artist" : "詹姆斯・乔伊斯(爱尔兰)", "year" : 1922,"price" : NumberDecimal("385.00") }, { "_id" : 7, "title" : "《魔山》", "artist" : "托马斯・曼(德)", "year" : 1924/* No price*/ }, { "_id" : 8, "title" : "《永别了,武器》", "artist" : "欧内斯特・海明威(美)", "year" : 1929,"price" : NumberDecimal("118.42") } ])
$bucket 按范围分组,手动指定各个分组的边界,用法如下:
db.books.aggregate( [ { $bucket: { groupBy: "$price", //用于分组的表达式,这里使用价格进行分组 boundaries: [ 0, 200, 400 ], //分组边界,这里分组边界为[0,200),[200,400)和其他 default: "Other", //不在[0,200)和[200,400)范围内的数据放在_id为Other的bucket中 output: { "count": { $sum: 1 }, //bucket中document的个数 "titles" : { $push: {title:"$title",price:"$price"} } //bucket中的titles } } } ] )
执行上边的聚合操作,结果如下:
[ { "_id" : 0, "count" : 4, "titles" : [ {"title" : "《白鲸》","price" : NumberDecimal("199.99")}, {"title" : "《罪与罚》","price" : NumberDecimal("76.04")}, {"title" : "《复活》","price" : NumberDecimal("167.30")}, {"title" : "《永别了,武器》","price" : NumberDecimal("118.42")} ] }, { "_id" : 200, "count" : 2, "titles" : [ {"title" : "《忏悔录》","price" : NumberDecimal("280.00")}, {"title" : "《尤利西斯》","price" : NumberDecimal("385.00")} ] }, { "_id" : "Other", "count" : 2, "titles" : [ {"title" : "《九三年》","price" : NumberDecimal("483.00")}, {"title" : "《魔山》"} ] } ]
$bucketAuto 和$bucket作用类似,区别在于$bucketAuto不指定分组的边界,而是指定分组的个数,分组边界是自动生成的
db.books.aggregate([ { $bucketAuto: { groupBy: "$year", buckets: 3, output:{ count:{$sum:1}, title:{$push:{title:"$title",year:"$year"}} } } } ])
执行上边的聚合操作,结果如下:
[ { "_id" : { "min" : 1782, "max" : 1895 }, "count" : 3, "title" : [ {"title" : "《忏悔录》","year" : 1782}, {"title" : "《白鲸》","year" : 1845}, {"title" : "《罪与罚》","year" : 1866} ] }, { "_id" : { "min" : 1895, "max" : 1924 }, "count" : 3, "title" : [ {"title" : "《九三年》","year" : 1895}, {"title" : "《复活》","year" : 1899}, {"title" : "《尤利西斯》","year" : 1922} ] }, { "_id" : { "min" : 1924, "max" : 1929 }, "count" : 2, "title" : [ {"title" : "《魔山》","year" : 1924}, {"title" : "《永别了,武器》","year" : 1929} ] } ]
$sample 用于随机抽取指定数量的document
db.books.aggregate([ { $sample:{size:2} } ])
执行后随即抽取了2条document,结果如下,注意因为是随即抽取的,所以每次执行的结果不同。
[{"_id":6,"title":"《尤利西斯》","artist":"詹姆斯・乔伊斯(爱尔兰)","year":1922,"price":NumberDecimal("385.00")},
{"_id":8,"title":"《永别了,武器》","artist":"欧内斯特・海明威(美)","year":1929,"price":NumberDecimal("118.42")}]
通过上边三个栗子,我们应该已经对聚合管道有了一定的理解,其实各种聚合运算符的用法都比较简单,怎么灵活的组合各种聚合操作以达到聚合的目的才是我们考虑的重点。
2 mapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算,MapReduce采用"分而治之"的思想,简单的说就是:将待处理的大数据集分为若干个小数据集,对各个小数据集进行计算获取中间结果,最后整合中间结果获取最终的结果。mongoDB也实现了MapReduce,用法还是比较简单的,语法如下:
db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, //输出 query: document, //查询条件,在Map函数执行前过滤出符合条件的documents sort: document, //再Map前对documents进行排序 limit: number //发送给map函数的document条数 } )
其中:map: 映射函数,遍历符合query查询条件的所有document,获取一系列的键值对key-values,如果一个key对应多个value,多个value以数组形式保存。
reduce: 统计函数,reduce函数的参数是map函数发送的key/value集合
out: 指定将统计结果存放在哪个collection中 (不指定则使用临时集合,在客户端断开后自动删除)。
query:筛选条件,只有满足条件的文档才会发送给map函数;
sort:和limit结合使用,在将documents发往map函数前先排序;
limit:和sort结合使用,设置发往map函数的document条数。
我们通过官网的栗子来理解mapReduce的用法,命令如下:
//添加测试数据 db.orders.insertMany([ {cust_id:"A123",amount:500,status:"A"}, {cust_id:"A123",amount:250,status:"A"}, {cust_id:"B212",amount:200,status:"A"}, {cust_id:"A123",amount:300,status:"D"} ]) //mapReduce db.orders.mapReduce( function() {emit(this.cust_id,this.amount)}, //map函数,遍历documents key为cust_id值,values为amount值,或者数组[amount1,amount2...] function(key,values){return Array.sum(values)}, //reduce函数,返回合计结果(只会统计values是数组) { query:{status:"A"}, //过滤条件,只向map函数发送status="A"的documents out:"myresultColl" //结果存放在myresultColl集合中,如果没有名字为myresultCOll的集合则新建一个,如果集合存在的话覆盖旧值 } ) printjson(db.myresultColl.find() .toArray())
mongoDB的MapReduce可以简单分为两个阶段:
Map阶段:
栗子中的map函数为 function() {emit(this.cust_id,this.amount)} ,执行map函数前先进行query过滤,找到 status=A 的documents,然后将过滤后的documents发送给map函数,map函数遍历documents,将cust_id作为key,amount作为value,如果一个cust_id有多个amount值时,value为数组[amount1,amount2..],栗子的map函数获取的key/value集合中有两个key/value对: {“A123”:[500,250]}和{“B212”:200}
Reduce阶段:
reduce函数封装了我们的聚合逻辑,reduce函数会逐个计算map函数传过去的key/value对,在上边栗子中的reduce函数的目的是计算amount的总和。
上边栗子最终结果存放在集合myresultColl中(out的作用),通过命令 db.myresultColl.find() 查看结果如下:
{"_id" : "A123","value" : 750},
{"_id" : "B212","value" : 200}
]
MapReduce属于轻量级的集合框架,没有聚合管道那么多运算符,聚合的思路也比较简单:先写一个map函数用于确定需要整合的key/value对(就是我们感兴趣的字段),然后写一个reduce函数,其内部封装着我们的聚合逻辑,reduce函数会逐一处理map函数获取的key/value对,以此获取聚合结果。
小结
本节通过几个栗子简单介绍了mongoDB的聚合框架:集合管道和MapReduce,聚合管道提供了十分丰富的运算符,让我们可以方便地进行各种聚合操作,因为聚合管道使用的是mongoDB内置函数所以计算效率一般不会太差。需要注意:①管道处理结果会放在一个document中,所以处理结果不能超过16M(Bson格式的最大尺寸),②聚合过程中内存不能超过100M(可以通过设置{“allowDiskUse”: True}来解决);MapReduce的map函数和reduce函数都是我们自定义的js函数,这种聚合方式比聚合管道更加灵活,我们可以通过编写js代码来处理复杂的聚合任务,MapReduce的缺点是聚合的逻辑需要我们自己编码实现。综上,对于一些简单的固定的聚集操作推荐使用聚合管道,对于一些复杂的、大量数据集的聚合任务推荐使用MapReduce。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号