


这次作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2753
一. 列表,元组,字典,集合分别如何增删改查及遍历。
1.列表
list = [1, 2, 3, 4, 5, 6, 7 ]; #创建列表list print("列表为", list) #输出list列表 print() #增 list.append(8) print("增加后:", list) print() #删 del list[1] print ("删除第二个元素 : ", list) print() #改 print ("第三个元素为 : ", list[2]) list[2] = 33 print ("修改后的第三个元素为 : ", list[2]) print("修改后",list) print() #查 print('查找list[1]:', list[1]) print() #遍历 print("遍历list:") for w in list: print(w)

2.元组
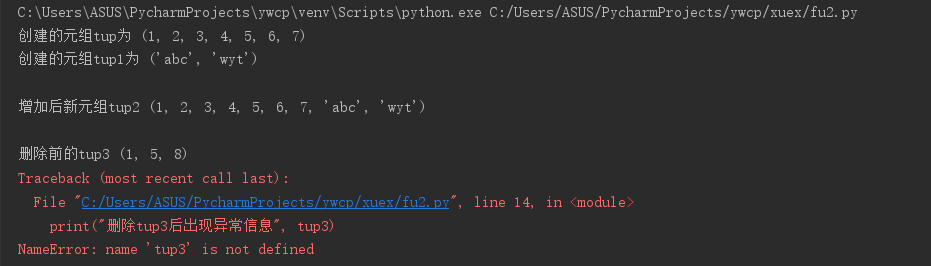
tup = (1, 2, 3, 4, 5, 6, 7 ) #创建元组tup tup1 = ('abc', 'wyt') #创建元组tup1 print( "创建的元组tup为", tup) print( "创建的元组tup1为", tup1) print() #增 tup2 = tup + tup1 print("增加后新元组tup2", tup2) print() #删(删除整个元组) tup3 = (1,5,8) print("删除前的tup3", tup3) del tup3 print() #改 tup = tup[0:3] print("提取tup前三个数", tup) tup = tup[1] print("取tup[1]:", tup) print() #查 print("查找tup1的第二个元素:", tup1[1]) print() #遍历 print("遍历tup1:") for w in tup1: print(w)

3.字典
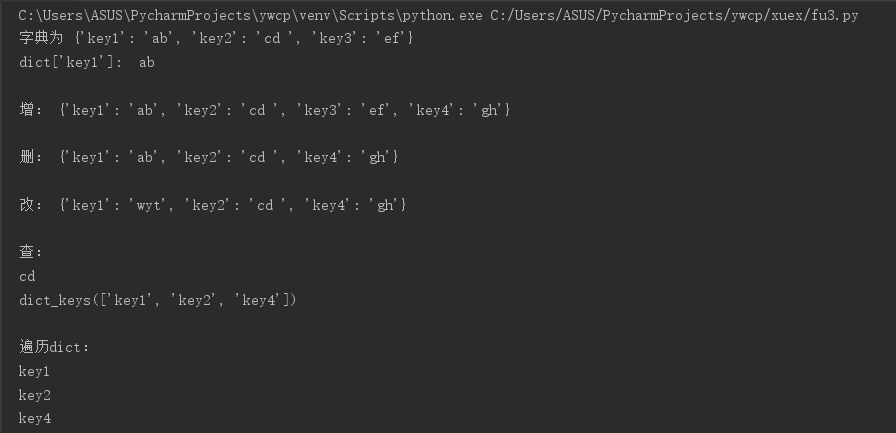
dict = {'key1': 'ab', 'key2': 'cd ','key3': 'ef'}; #字典的创建
print('字典为', dict)
print ("dict['key1']: ", dict['key1']) #访问key1
print()
#增
dict.update({'key4': 'gh'})
print('增:', dict)
print()
#删
del dict['key3']
print('删:', dict)
print()
#改
dict['key1']='wyt'
print('改:', dict)
print()
#查
print('查:')
print(dict['key2'])
print(dict.keys())
print()
#遍历
print("遍历dict:")
for key in dict:
print(key)
4.集合
set = {'a', 'b', 'c', 'd', 'e', 'f'} # 创建集合
print('集合为', set)
print()
# 增
set.add('h')
print('增', set)
print()
# 删
set.remove('a')
print('删', set)
print()
# 查
print('查看集合元素是否在set中:')
print('b在不在set中: ', 'b' in set)
print('1在不在set中; ', '1' in set)
print()
# 遍历
print("遍历set:")
for s in set:
print(s)

二. 总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
- 括号
- 有序无序
- 可变不可变
- 重复不可重复
- 存储与查找方式
区别如下图:
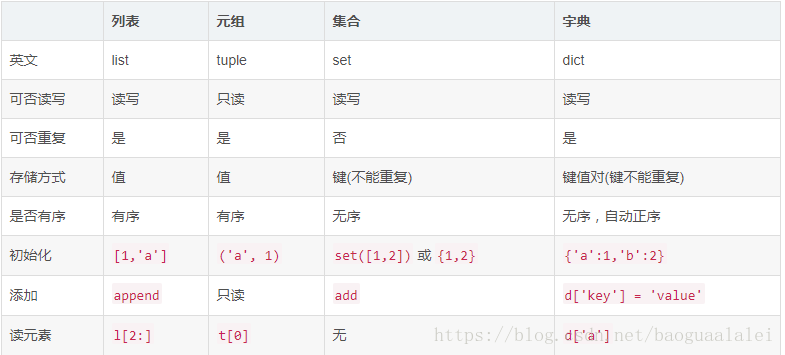
图2-1 列表,元组,字典,集合的联系与区别
三. 词频统计
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
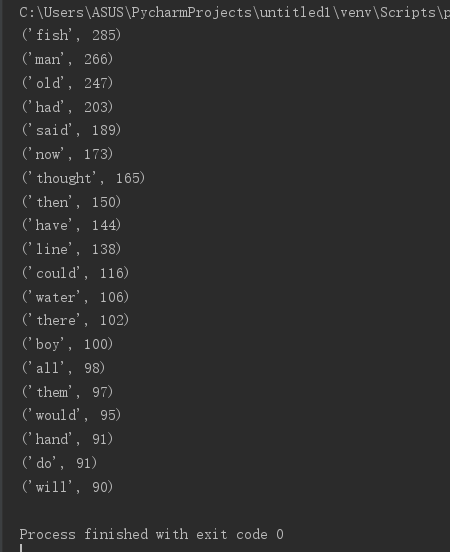
8.输出TOP(20)
- 9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
代码如下:
import string import pandas as pd # 读取文本文件并对文本进行预处理 def get_text(): f = open("老人与海.txt").read().lower() # 删除没必要的符号 for c in string.punctuation: f = f.replace(c, " ") return f # 将大写字母转换成小写字母 f = f.lower() # 分解提取单词 text=get_text().split( ) # 排除连词、冠词、代词、系动词无语义词 exclude = {'a','as','an', 'it', 'if', 'the', 'at', 'for', 'on', 'and', 'in', 'to', 'of', 'was', 'be', 'were', 'in', 'about', 'from', 'with', 'without', 'one', 'another' , 'others', 'that', 'they', 'himself', 'itself', 'themselves', 'if', 'when', 'before', 'though', 'although', 'while', 'as long as','i', 'he', 'him', 'she','out', 'is', 's', 'no', 'not', 'you', 'me', 'his', 'but','we','us','their','our','her'} textset=set(text)-exclude # 单词统计 textdict = {} for w in textset: textdict[w] = text.count(w) # 词频排序 wordlist = list(textdict.items()) wordlist.sort(key=lambda x:x[1],reverse=True) # 输出TOP(20) for i in range(20): print(wordlist[i]) # 对单词数量进行保存成csv类型文件 pd.DataFrame(data=wordlist).to_csv('F:\\wyt\\order.csv',encoding='utf-8')
可视化词云:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号