
微服务的注册与发现——以Nacos为例
一、引言
在微服务架构中,随着服务数量的增加,服务间的有效通信变得至关重要。服务注册与发现机制允许服务动态地注册自身并发现其他可用服务,从而支持系统的灵活性和扩展性。这种机制是确保服务能够可靠通信的基础,对于构建高效、弹性的分布式应用不可或缺。
二、服务注册与发现的基本原理
1. 服务注册
- 形式:以Map的形式将服务信息注册到注册中心。
- 键:服务名。
- 值:服务实例的详细信息(包括IP地址和端口号)。
- 目的:确保每个服务能够被唯一标识并方便管理。
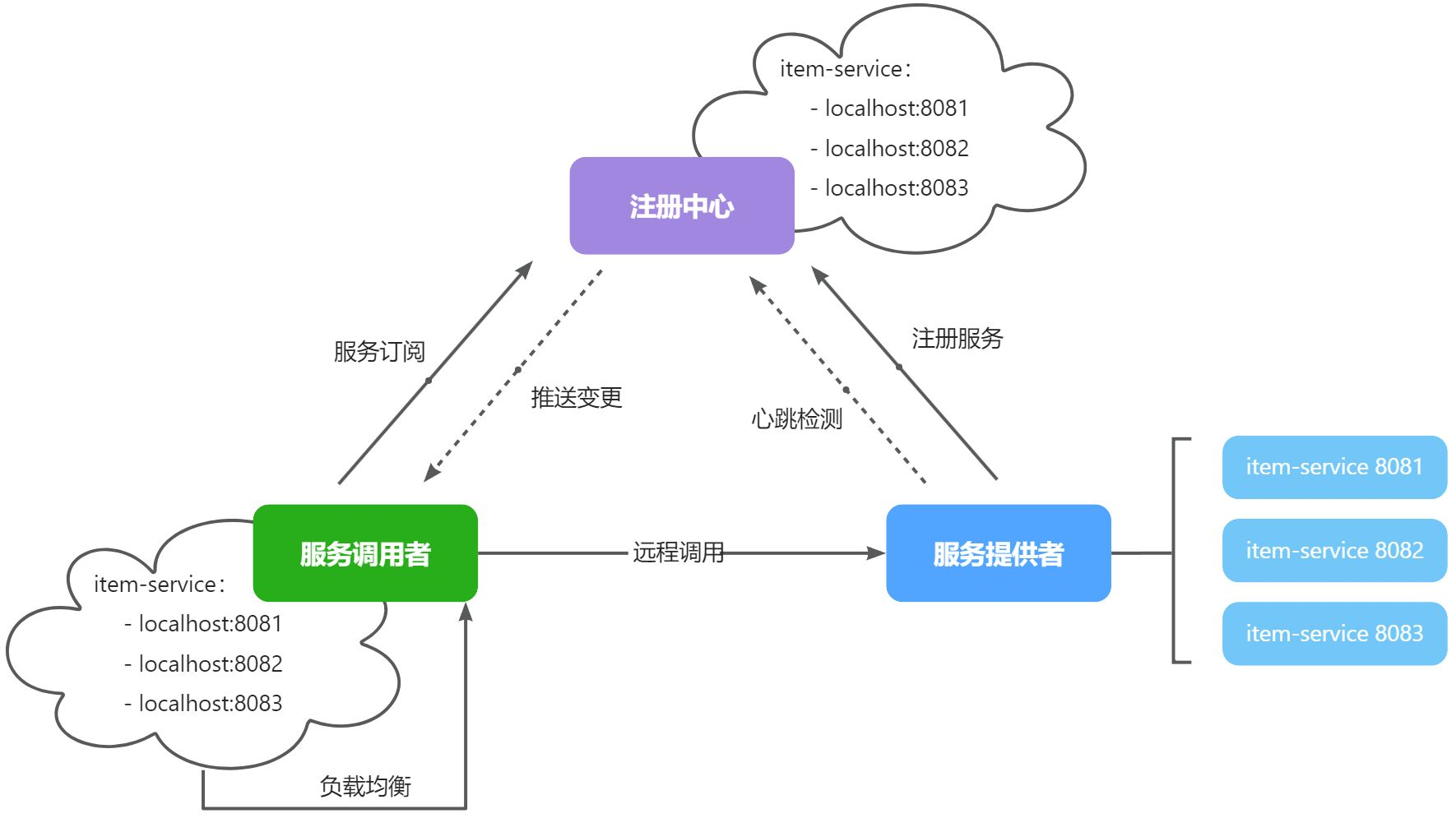
2. 服务发现
- 订阅方式:通过服务名从注册中心订阅服务列表,并将其缓存到本地。
- 调用机制:使用负载均衡策略从本地缓存的服务列表中选择一个可用的服务实例进行远程调用。
- 效果:提升系统的灵活性,保证服务调用的高效性和可靠性。
三、常见的注册中心中间件
1. Zookeeper
- 开发者:由Apache基金会开发。
- 数据模型:采用抽象的树形K-V结构存储数据,理论上可以存储任何类型的数据。
- 适用场景:主要用于分布式协调和服务发现,但由于其数据模型较为抽象,缺乏针对服务发现的特定设计,因此在实际应用中需要额外的工作来适配服务发现的需求。
- 性能:在大规模和多环境部署时可能面临性能瓶颈,尤其是在处理高并发的服务发现请求时。
2. Eureka
- 开发者:由Netflix公司开发,现集成于Spring Cloud项目中。
- 数据模型:专注于实例级别的数据扩展,支持动态注册与发现服务实例。
- 适用场景:广泛应用于Java生态系统,特别是Spring Cloud项目中。虽然功能强大,但在大规模和多环境部署时可能面临性能瓶颈。
- 性能:适用于中小型系统,在大规模和高负载环境下可能会出现性能问题。
3. Consul
- 开发者:由HashiCorp公司开发。
- 数据模型:提供了实例级别的数据扩展,并支持健康检查、键值存储等多种特性。
- 适用场景:适用于跨语言微服务架构,能够满足大多数服务发现需求。尤其适合那些需要强安全性和多数据中心支持的应用。
- 性能:Consul以其出色的性能著称,尤其在处理大规模和高并发的服务发现请求时表现出色,能够提供稳定且高效的运行体验。
4. Nacos
- 开发者:由阿里巴巴公司开发。
- 数据模型:基于阿里巴巴多年的生产经验提炼出的服务-集群-实例三层模型。这种结构不仅支持实例级别的数据扩展,还能灵活应对大规模和多环境下的服务管理需求。
- 适用场景:特别适合需要高灵活性和扩展性的微服务架构,能够轻松应对开发、测试、生产等不同环境的服务管理。
- 性能:Nacos在大规模和复杂环境中表现出色,能够高效处理大量的服务注册和发现请求。
四、Nacos如何实现服务注册与发现
1. 服务提供者
- 启动时注册:容器启动时,服务提供者将服务信息(包括服务名、IP地址、端口号等)注册到Nacos。
- 心跳续约:提供者会定期向Nacos发送心跳以进行服务续约,确保服务的可用性。
- 服务剔除机制:若服务未能及时续约,Nacos会根据该服务是否为临时实例来决定是剔除还是保留该服务。
2. 服务消费者
- 订阅服务:根据需求,服务消费者从Nacos订阅所需的服务,并拉取服务列表到本地缓存。
- 负载均衡调用:基于本地缓存的服务列表,消费者使用负载均衡策略选择一个可用的服务实例进行远程调用。
- 缓存更新:
- 异步推送:当Nacos中注册的服务信息发生变化时,会通过异步方式主动推送给消费者,确保服务信息的实时性和准确性。
- 定时更新:消费者也可以定时向Nacos发送请求以更新本地缓存的服务信息。
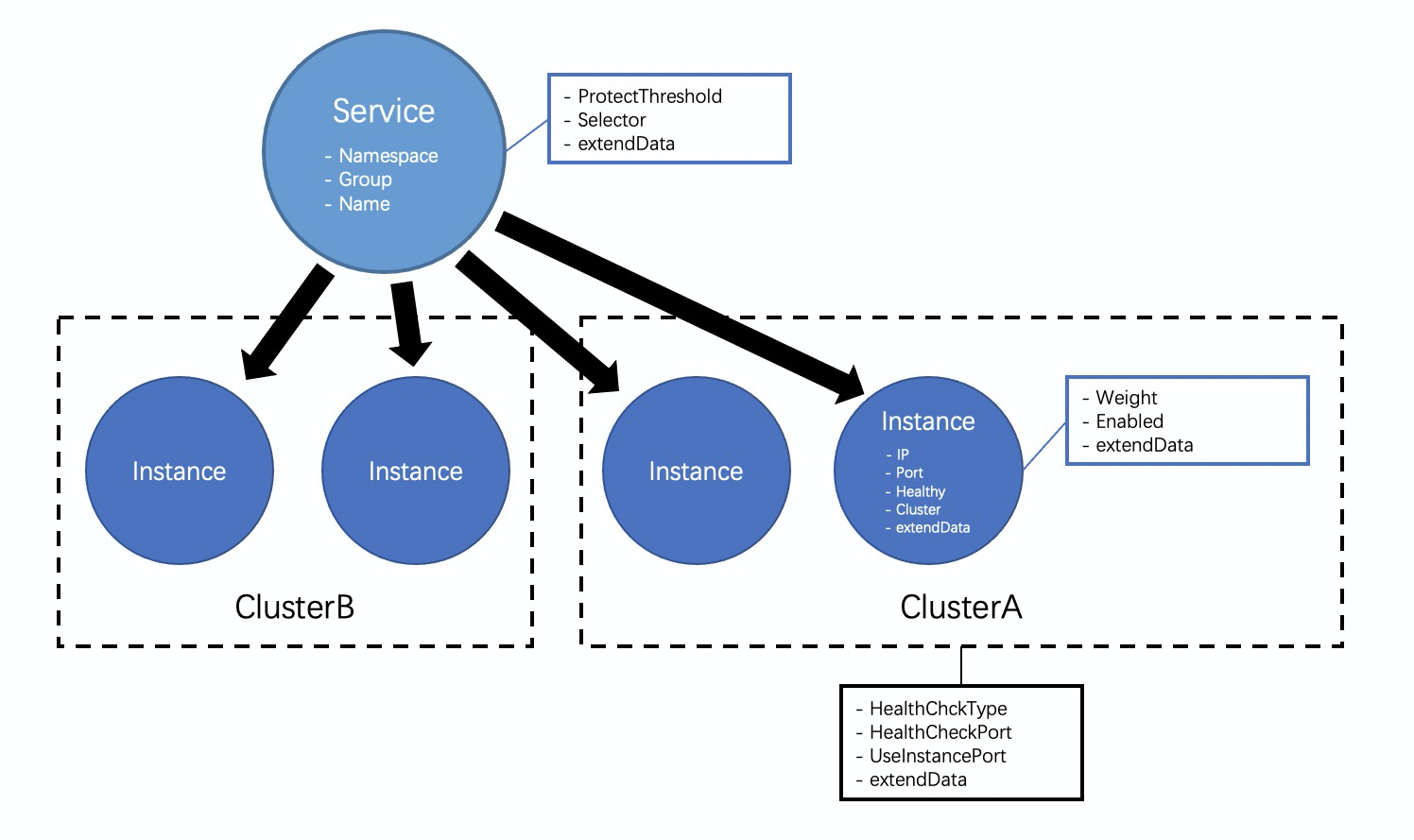
五、Nacos注册中心服务数据模型
Nacos的注册中心通过分层的数据模型实现服务的高效管理和灵活发现,其核心设计涵盖了从命名空间到实例元数据的多个维度。以下是Nacos服务数据模型的主要内容:
1. 服务
- 命名空间(Namespace):
数据模型中最顶层的概念,用于强制隔离不同环境或租户的服务。例如,可以将开发、测试和生产环境分别放置在不同的命名空间中。 - 分组(Group):
次于命名空间的逻辑隔离概念,主要用于区分同一服务的不同使用场景或防止同名服务冲突。例如,可以按应用名分组或将测试与生产环境分开。 - 服务名(Name):
描述服务功能或能力的实际名称,通常结合运行环境、应用名和服务功能来确保唯一性。
2. 服务元数据
- 健康保护阈值(ProtectThreshold):
定义一个0到1之间的浮点数,用于防止因过多实例故障导致剩余健康实例被压垮,从而引发雪崩效应。当健康实例比例低于此阈值时,所有实例都会返回给客户端。 - 实例选择器(Selector):
提供基于CMDB存储的元数据标签进行实例筛选的能力,帮助用户实现更灵活的流量路由。 - 拓展数据(extendData):
用户自定义的K-V元数据,用于扩展服务的描述信息,支持实现自定义逻辑。
3. 实例
实例是具体提供服务的节点,其定义主要包括以下内容:
- 网络IP地址与端口:实例的网络地址和端口信息,支持域名配置。
- 健康状态(Healthy):通过健康检查机制维护实例的健康状态。
- 集群(Cluster):标识实例所属的逻辑集群,支持对实例进行分组管理。
- 拓展数据(extendData):用户自定义的K-V元数据,用于标记实例或实现自定义逻辑。
4. 实例元数据
- 权重(Weight):范围为0-10000的浮点数,权重越大分配的流量越多。
- 上线状态(Enabled):标记实例是否接受流量,优先级高于权重和健康状态,便于运维人员快速移除实例。
- 拓展数据(extendData):允许运维人员动态修改实例的扩展数据,无需改动实例本身。
5. 持久化属性
Nacos支持两种类型的服务:
- 持久化服务:适用于类DNS的基础服务组件场景。
- 非持久化服务:适用于上层业务服务场景,心跳失效后自动下线。
6. 集群
集群主要保存健康检查的相关信息:
- 健康检查类型(HealthCheckType):支持TCP、HTTP、MySQL等方式,也可关闭健康检查。
- 健康检查端口(HealthCheckPort):指定用于健康检查的端口。
- 是否使用实例端口进行健康检查(UseInstancePort):若启用,则直接使用实例的网络端口进行健康检查。
- 拓展数据(extendData):用户自定义的K-V元数据,用于扩展集群的描述信息。
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号