

20199106 2019-2020-2《网络攻防实践》综合实践
20199106 2019-2020-2 《网络攻防实践》综合实践
TIFF:Using Input Type Inference To Improve Fuzzing (ACSAC'18)
一、Fuzzer简介
什么是Fuzzer
Fuzzer是一种通过产生一系列非法的、非预期的或者随机的输入向量给目标程序,从而完成自动化的触发和挖掘目标程序中的安全漏洞的软件测试技术。相比于形式化的软件漏洞测试技术(比如,符号执行技术 ),Fuzzer往往能够在实际的应用中挖掘更多的漏洞。
Fuzzer的种类
一个形象的Fuzzer例子就比如下面让一个猴子去测试应用程序。通过让它胡乱点击电脑的键盘或者移动鼠标,产生不在预期内的输入,从而发现目标程序的bug。(Android应用测试中的Monkey测试也是类似的,它通过胡乱点击Android手机上所有可见的控件,进行压力测试,当Android应用出现闪退或者不能响应的问题时,bug也就发现了)即完成一个Fuzzer的过程,包括:一只猴子(fuzzer 输入构造模块)、一个可以运行的程序以及崩溃的程序捕捉(fuzzer的错误反馈与捕捉)。
常用fuzzer技术有以下几种:
1、基于变种的Fuzzer(mutation-based fuzzer)。它的关键在于变种。基于变种的Fuzzer是在已知合法的输入的基础上,对该输入进行随机变种或者依据某种经验性的变种,从而产生不可预期的测试输入。
2、基于模板的Fuzzer(Generation-based)
由于基于变种的Fuzzer对于合法的输入集合有较强的依赖性,为了能够测试尽可能多的输入类型,必须要有足够丰富类型的合法输入,以及花样够多的变种方式。如果测试人员对目标程序或者协议已经有了较为充分的了解,那么也有可能制造出更为高效的Fuzzer工具。即,测试的目的性更强,输入的类型有意识的多样化,将有可能更快速的挖掘到漏洞。这类方法的名称叫做基于模板的Fuzzer。此类Fuzzer工具的输入数据,依赖于安全人员结合自己的知识,给出输入数据的模板,构造丰富的输入测试数据。
3、基于反馈演进的Fuzzer(Evolutionary-based),这也是现今应用最广泛的一种Fuzzer。上面的变种Fuzzer和模板Fuzzer,仍然会面临挖洞效率低的问题。对于变种测试,由于依赖基础的合法输入,那么到底选择多少合法输入才能穷尽的覆盖到尽可能多的测试点呢?这便引出了fuzz工具里面一个经典的问题,fuzz的覆盖率问题。简单来说,我们要找一种指标来衡量,fuzz工具是不是真正的覆盖到了我们想要覆盖的所有范围。这就引出了新的一类方式,基于反馈演进的Fuzzer。即,此类Fuzzer会实时的记录当前对于目标程序测试的覆盖程度,从而调整自己的fuzzing输入。其中,程序的覆盖率是一个此类方法的核心。目前,有以下几个代码覆盖率指标在演进模糊测试里面会经常碰到:路径覆盖率(可以有类似的利用BL算法的路径标记和压缩算法);分支覆盖率;代码行覆盖率。
二、已有Fuzzer的不足分析
图1显示了tiff文件的组织。它有一个8字节的头,其中最后4个字节决定了图像文件目录(IFD)偏移量的位置。在ifd偏移位置和头字节之间的字节可能被应用程序处理,也可能不被处理,这取决于其他标记和文件大小。因此,确定应用程序如何处理这些字节对于获得有意义的字节突变是至关重要的。
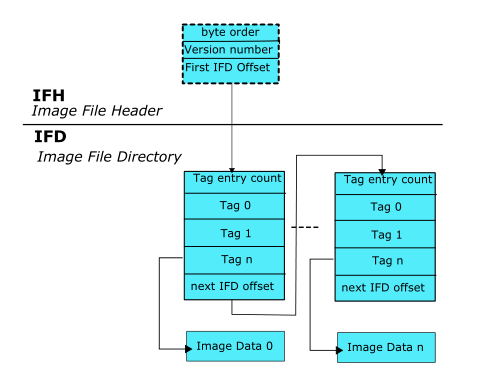
图1:tiff文件的高级结构:8字节头后面是一系列图像文件目录(IFD)结构
在I F D结构中,前2个字节决定12字节标记的数量,然后是这些字段的指定数量。清单1显示了一个易受攻击的C代码示例,它解析tiff文件格式。它基于libtiff库的TIFFRGBAImageBegin()函数,并人为地注入了一个错误。

清单1:演示现有fuzzers问题的激励示例
在清单1中,struct头的ifd_offset字段表示图像文件描述符(IFD)结构的文件中的开始。每个IF D结构包含一个值,表示数量的标签,标签的列表和下一个IFD的偏移量。第20行的函数使用标签的数量来确定分配给12字节结构的标签的内存量。不幸的是,如果对应的字节值大于5460,alloc_sz值很容易溢出。结果是,当程序试图在第24行复制缓冲区中的数据时,缓冲区会溢出(例如,导致分段错误)。
尽管这个bug通常依赖于输入文件的特定字节,但是对于通用的fuzzer,比如VUzzer或AFL,要在这些字节处改变输入并触发这个bug是非常困难的。具体地说,当我们用VUzzer运行这个(琐碎的)代码片段时,VUzzer需要多达5000个输入才能使应用程序崩溃。相比之下,TIFF仅在200个输入中就产生了崩溃。
这背后的原因:
(1)因为第17行的cmp用h.ifd_offset作为它的操作数。VUzzer等fuzzer将改变h.ifd_offset的值,这样做可以改变第一个ifd偏移的位置。相比之下,TIFF只更改了预期的偏移值来尝试触发bug,这使它能够在给定的示例中更快地产生崩溃。
(2)为了触发第20行整数溢出,fuzzer需要为i1.no_entries选择一个合适的值使alloc_sz足够小,使第24行发生堆溢出。现有的Fuzzer只是试图以一种随机的方式在输入中改变这些字节。相反,TIFF知道i1.no_entries的类型,并通过选择有趣的INT16值(可能导致整数溢出)快速触发错误。
三、TIFF原理解析
图2给出了TIFF的主要组成以及它们之间的相互作用。虚线框表示我们现在依次解释的任务划分。
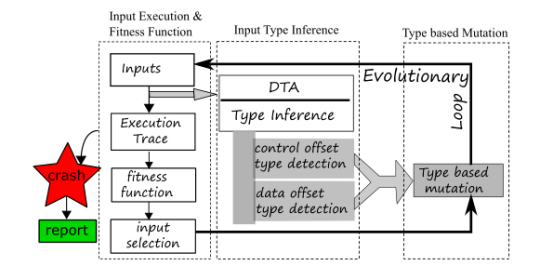
图2:TIFF的高级概览。每个实线块表示不同的组件,而每个虚线框表示fuzzer的不同高级功能。
输入执行和适应度函数
作为一种基于突变的Fuzzer ,TIFF需要一组种子输入来开始Fuzzing。应用程序执行这些输入并生成执行跟踪。在现有的实现中,TIFF监视基本块及其执行频率,并根据执行的基本块计算输入的适合度。任何输入,只要执行一个新的基本块,都会被考虑作进一步的变异。
DTA与输入类型推断
动态污染分析(DTA)在确定输入的几个有趣特性方面起着中心作用。为了最大化编解码和bug检测,TIFF派生了两类特性:控制偏移类型和数据偏移类型。
控制偏移量指输入中影响cmp指令中操作数的字节,并决定分支指令的结果。与VUzzer一样,TIFF也在执行输入时执行DTA,以查找操作数受输入偏移量影响的cmp指令。这种偏移量是突变用来改变应用程序执行路径的有趣目标。TIFF进一步分析此信息,以推断应用程序期望从输入中得到的不变量。这些不变量,例如magic-字节,标记的存在,在二进制输入格式中广泛流行。TIFF还通过对类型推断执行单独的分析来计算此类偏移量的类型,并相应地将类型标记(如INT8、INT16、UINT32和char*)与这些偏移量关联起来。
除了控制偏移量之外,TIFF还执行类型推断技术,以将类型标记与输入的其他偏移量相关联。我们将它们称为数据偏移类型。目前,TIFF将INT8、INT16、INT32和数组/结构类型关联到数据偏移量。
基于类型的突变
这是DIFF主要的一步,负责改变输入,以实现高代码覆盖率和bug检测。对于给定的输入,TIFF首先考虑控制偏移类型。如果没有与这些偏移量相关联的不变式,则使用为这些偏移量学习的不变量,或者根据与此偏移量相关联的类型标记,对相应的偏移量进行突变。这两个选项都提高了fuzzer的代码覆盖率。接下来,TIFF考虑输入的非控制偏移量的数据偏移类型。在这里,它选择性地执行基于类型的变异——在只覆盖新路径的选定输入上进行。直观的理解是,通过关注数据偏移量,我们可以发现在执行路径中可能存在的bug。TIFF的变异策略因输入字节的类型而异。具体来说,对于INTx类型的偏移量,TIFF会根据大小x查找不寻常的值(例如,给定整数类型的极值),并将这些值放在这些偏移量上。这种类型的突变主要针对整数溢出的bug和(在较小程度上)堆溢出的bug。对于类型数组的偏移量,TIFF插入任意长度的数据(基于数组元素类型)。这种类型的变异主要针对缓冲区溢出。
输入类型推断的具体技术
- 输入偏移量的内存数据结构识别:
TIFF主要关注使用二进制文件的应用程序,二进制文件经常被组织成数据类型的数组,例如长整数和短整数、字符和字符串。因此,我们的目标是自动学习这种类型的系统。我们希望了解应用程序如何处理输入的每个偏移量。我们确定了以下两类与输入偏移量相关的数据类型:
(1)单个的n字节值(例如1字节、2字节、4字节等);
(2)组合字节(例如,作为数组或结构处理的一组偏移量);
我们的内存DSI步骤由三个组件组成:基本数据类型识别、复合数据类型(例如数组)检测和对某些数据类型(例如char*、int等)的精确检测。对于一个给定的输入,这一步的结果是一个映射h:i[]->T,i[]是输入i的一组偏移量,T =[INT8,NT16, NT32,数组/结构]。T表示TIFF可识别的类型。为了支持这种类型检测,TIFF使用DTA引擎监视应用程序内受污染输入的流程。
在程序执行期间,DTA确定哪些内存位置和寄存器依赖于受污染的输入字节。根据粒度,DTA然后将污染值追溯到输入中的各个偏移量。本文的DTA框架基于LibDFT。
- 基本数据类型识别
基于应用程序几乎完全根据偏移量的类型信息莱来处理偏移量,我们使用Tupni的输入格式推断技术,识别与输入中的(一组)偏移量相关的类型。
Tupni算法是这样工作的:我们将输入划分为短的连续字节序列,并监视应用程序,以了解指令如何访问受污染的字节。例如,考虑add reg32、[addr]这样的添加指令,其中[addr+0、addr+1、addr+2、addr+3]分别被文件偏移量0、1、2和3所污染。在本例中,我们将第0个字节归类为大小为4的块。我们还为每个块分配一个权重,其中的权重表示该块被访问的次数。我们注意到,这些块并不总是不连续的。对于所有相交的块,我们保留具有较高权重的块。
- 阵列检测
对于数组和结构等复合数据类型,我们使用Howard的内存中数组检测。我们选择Howard的阵列检测技术,因为它更精确,并且克服了其他技术的大部分限制。Howard的具体实现可见下图:

算法1:基于控制和数据偏移量的突变所涉及的步骤
- 精确的数据类型识别
我们还使用有限版本的REWARD来标识更精确的数据类型,比如size_t(无符号int)、char*等。我们通过连接libc库调用来实现这一点,我们为参数提供了详细的类型信息。
类型推断辅助的突变
- 面向覆盖面的突变
TIFF通过利用与cmp指令的操作数相对应的偏移量类型来实现高代码覆盖率的目标,还通过将输入字节替换为我们通过连接stringcompare系列库函数所记录的字节来提高代码覆盖率。 - 面向bug的突变
这种类型的突变主要针对在选择使输入发生变化以生成下一个输入的偏移量时,我们考虑特定数据类型的偏移量,以及在任何控制流决策中使用的偏移量。在当前的实现中,我们特别增加了检测两类内存损坏bug的概率:整数溢出和缓冲区溢出。
四、TIFF的实现
我们在开源的fuzzer VUzzer上构建TIFF。我们选择VUzzer,因为它是一种最先进的进化模糊器,它实现了一种已经很有效的面向覆盖的模糊策略。作为实现的一部分,我们对libDFT进行了重新设计,使其与64位应用程序兼容,并将VUzzer提升到64位系统上。我们使用VUzzer的适应度函数。然而,我们完全重新设计了VUzzer的突变策略,以反映本文提出的基于类型推理的技术。
如前所述,我们的输入类型推断系统的一部分是基于Howard的。为了使Howard适合TIFF的目的,我们用了几种方法对它进行了修改,例如,将它提升到64位二进制文件上,为taintmap实现了不同的数据结构,可以在更大的输入上很好地扩展,等等。
因为Howard的数组检测在一些大型和复杂的应用程序中花费了很长时间。为了实现更快的输入生成,我们只对种子输入运行数组检测。
事故分类:为了便于比较,我们使用栈哈希技术来确定崩溃的唯一性。使用Pintool,TIFF监视短的执行历史,直到崩溃点,以计算堆栈哈希。它跟踪崩溃点之前循环缓冲区中最后10个执行的基本块和最后5个执行的函数调用,然后计算缓冲区的哈希值来确定崩溃的唯一性。
-
实验环境:一个装有64位2核英特尔CPU和16GB内存的Ubuntu 14.04 LTS系统
-
实验设计:将所有实验重复3次,并报告平均结果,在重复的模糊运行过程中观察到的边缘统计差异。
-
实验对象:考虑了该领域比较新的两个数据集。首先是最近由LAVA team生成的一组buggy 二进制文件,特别是LAVA-m数据集。其次,我们考虑处理二进制输入数据的各种实际应用程序,例如图像处理应用程序,我们将这个杂项应用程序数据集称为MA数据集。此外,我们分别在两个应用程序的最新版本上运行
TIFF—libmine-0.4.8和libexiv2 0.27并发现了新的错误。在libexiv2中,发现了一些无限循环的bug和一些断言失败错误;在libming中,我们发现在函数parseABC_NS_SET_INFO中存在访问冲突,从而导致分段错误。
五、TIFF性能的比较和评估
- LAVA-M集实验结果
我们使用LAVA数据集(由4个Linux实用程序base64、who3、uniq和md5sum组成来比较TIFF和VUzzer的性能。
表1给出了我们的结果。LAVA二进制文件中的每个注入故障都有一个故障ID,该ID用于在该故障导致的二进制崩溃之前打印在标准输出上。这允许我们精确地识别由TIFF在崩溃运行时触发的惟一bug。如表1所示,TIFF发现与VUzzer相比,输入更少,bug更多。此外,图3显示了运行期间LA V A-M二进制文件崩溃的分布。每个图的y轴表示崩溃的累积和,而x轴表示模糊器的总执行时间。如图所示,TIFF不仅比VUzzer发现了更多的bug,而且发现得更快。
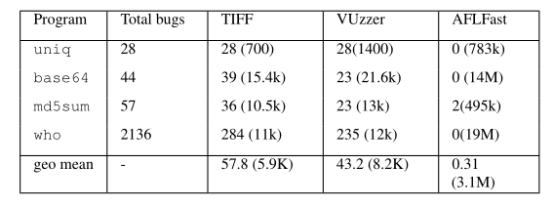
表一 :LA V A-M数据集:TIFF vs VUzzer;第3、4和5列将数据显示为unique bugs(总输入),括号中的数字表示生成惟一错误所需的输入数量。
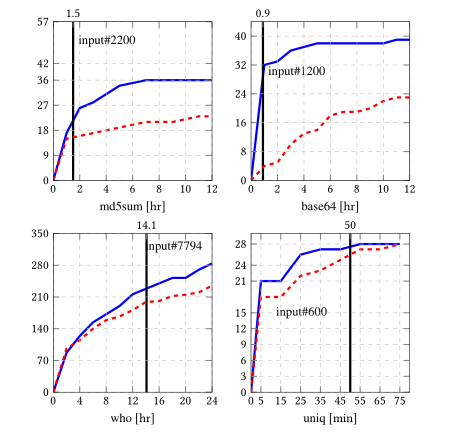
图3:应用程序在其运行期间的崩溃分布。x轴:时间轴;y轴:唯一缺陷的累积和。蓝线:TIFF。红色虚线:VUzzer
- MA集实验结果
如表2所示,TIFF再次比VUzzer触发更多的崩溃,且TIFF通常输入的更少。这证实了我们对VUzzer执行的与类型无关的突变的观察:由于VUzzer不知道偏移量的类型,它无法在这些偏移量上对输入字节进行有意义的突变。与AFLFast的delta更明显,因为TIFF可以用更少的输入产生更多的崩溃。
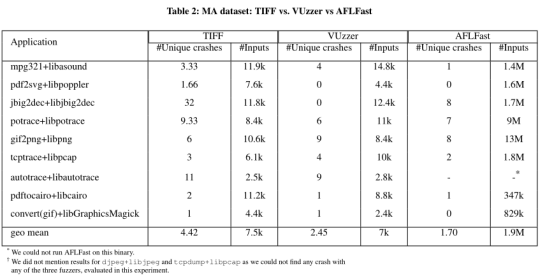
表2:MA数据集:TIFF vs. VUzzer vs. AFLFast
我们还从代码覆盖的角度评估了TIFF的有效性(另一个常见但不太精确的bug检测有效性代理度量)。表3给出了TIFF和VUzzer的结果。
由于我们模糊了应用程序二进制文件,所以简单地按照总代码的百分比来表示代码覆盖率并不是一件小事。出于这个原因,我们测量了由fuzzers覆盖的新基本块的数量与由fuzzers在种子输入情况下执行的基本块的数量之比。表3的第2列列出了初始(种子输入)基本块的数量,其他列列出了每个fuzzer在整个测试时间间隔(12小时)内发现的基本块的数量。这个数字只包括主要的应用程序基本块和目标库的基本块。第3列和第4列中括号内的数字表示每个fuzzer执行的输入的总数。在TIFF情况下,这个数字还包括使用基于数据偏移量的突变生成的输入(不监视执行的基本块)。
如表3所示,对于大多数应用程序,TIFF能够比VUzzer用更少的输入发现更多的基本块。这证实了我们的假设,即cmp偏移量(现在已知的)类型的类型一致的突变会导致更快地发现新的基本块。对于mpg321和gif2png,我们的结果只显示TIFF和VUzzer覆盖的基本块的数量之间的一个小(或没有)差异。更仔细的检查发现,在这些情况下,在数据偏移突变阶段生成的输入的数量不会产生任何崩溃,并且对于新的基本块不会监控这些输入,但是TIFF在这些输入上花费了大量的时间。这种行为促使我们进一步研究缺少代码覆盖的问题。我们运行了3个应用程序(gif2png、mpg321和autotrace),启用了对面向bug的循环的监视。我们发现我们遗漏了0% (resp)。23%, 26%) mpg321的基本模块(resp)。gif2png和自动跟踪)。很明显,我们需要一种方法来捕获这种新的基本块,并且执行惩罚更少。因此,从表3中可以看出,对于一定数量的应用,TIFF并不明显优于VUzzer。
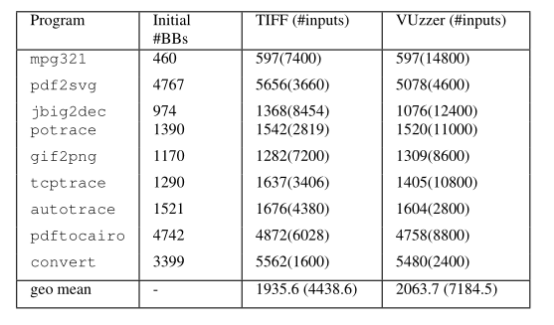
表3:TIFF和VUzzer在MA数据集上发现的基本块
- 碰撞分析
我们发现TIFF可以在MA数据集的多个应用程序中触发可利用的bug。在表4中,我们报告了导致崩溃的原因。

表4:TIFF发现的错误类型
五、本文的贡献
1我们通过寻找现代fuzzers执行突变的方法中的空白来激发更有效地执行突变的问题。
2通过应用现有的输入反向工程和DSI技术,我们提出了一种新的基于推理的变异策略,提高了代码覆盖率和触发内存损坏bug的概率。
3我们在一个名为TIFF的全功能fuzzer中实现了建议的技术,它将很快成为开源的(更新可以在https://www.vusec.net/projects/#testing上找到)。
4我们在几个真实应用中评估了TIFF,以经验证明其有效性。
学习感想和体会
这一学期的学习让我深刻认识到自己动手能力太弱,这同时又说明还有很大上升空间。感谢这门课让我对安全领域有了一个虽然不深入但比较全面的认识。(由于学得艰难的绝大部分原因是因为自己基础太差,所以对这门课一时想不出什么有价值的建议。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号