


Python网络爬虫-FIFA球员数据爬取
FIFA球员数据爬取
一.选题背景
世界杯的开展,给全世界广大球迷带来了狂欢和盛宴,球员们的精彩表现给世界各地的观众带来了一场场精彩绝伦的比赛。在比赛中,球员是决定比赛胜负的关键,为了探究世界球员的特点和能力,本文爬取了FIFA中的球员数据,通过对数据进行可视化探索和建模分析,能够更好的发掘影响球员能力的重要因素,从而有利于球员的成长和发现。
二.爬虫设计方案
1.爬虫名称
FIFA球员信息多线程爬虫。
2.爬取的内容和数据特征分析
本文的爬取信息为:球员名字,基本信息(出生年月,身高,体重),Overall_Rating, Potential, Value, Wage以及ATTACKING,SKILL,MOVEMENT,POWER,MENTALITY,DEFENDING,GOALKEEPING模块下的具体信息。
数据特征分析主要在于分析球员能力的分布,并探究球员潜力(Potential)与不同能力之间的关系。
3.爬虫设计方案概述
实现思路
在球员大致信息页面中爬取球员具体信息页面网址,在通过爬取到的球员具体信息网址进入网址中爬取具体信息。
其中在主页面,也就是球员具体信息入门页面处,每个主页面含有60个球员信息入口界面,本文通过gevent库创建多线程爬虫(开启60个任务各自爬取对面副页面的球员具体信息)对球员具体信息进行爬取。除此之外,还需调用time,request,lxml和random库 随后调用numpy,pandas,seanborn,sklearn和matplotlib库对数据进行分析
技术难点
多行程并行爬虫,球员信息的定位,对于反爬进制的破解,回归方程的设立。
三.主题页面的结构特征分析
1.主题页面的结构和特征分析
球员的大致内容如下所示:
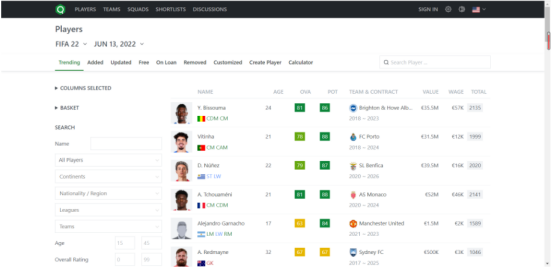
球员具体信息如下所示:
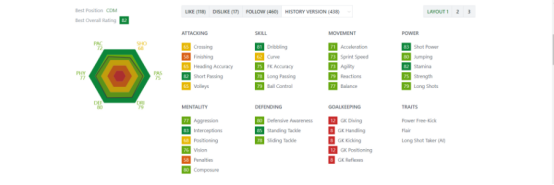
2.Htmls页面解析
每个球员的大致内容页面含有60个球员具体信息页面入口,在球员大致内容信息页面依次爬取60个具体信息 界面,并通过开启60个线程,同时爬取60个球员的具体信息。并通过xpath定位到具体的信息的地址,通过逐个查找找到需要数据的所在位置,发现所需要的数据都在<tbody>下的<tr>。
3.节点(标签)查找方法与遍历方法
查找方法:lxml库的xpath函数
遍历方法,人工确定数据位置
四.网络爬虫程序设计
1. 数据的爬取与采集
# 导入模块
import gevent from gevent import monkey monkey.patch_all() import time import requests import random from lxml import etree import pandas as pd class FIFA21(): def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"} self.baseURL ='https://sofifa.com/' self.path='data.csv' self.row_num=0 self.title=['player_name','basic_info','Overall_rating','Potential','Value','Wage', 'preferred_foot','weak_foot','skill_moves','international_reputation'] self.small_file=['LS','ST','RS','LW','LF','CF','RF','RW','LAM','CAM','RAM','LM','LCM','CM','RCM','RM','LWB', 'LDM','CDM','RDM','RWB','LB','LCB','CB','RCB', 'RB','GK'] self.details=['Crossing','Finishing','Heading Accuracy','Short Passing','Volleys','Dribbling,Curve', 'FK Accuracy','Long Passing','Ball Control','Acceleration','Sprint Speed','Agility','Reactions', 'Balance','Shot Power','Jumping','Stamina','Strength','Long Shots','Aggression','Interceptions','Positioning', 'Vision','Penalties','Composure','Defensive' 'Awareness','Standing Tackle','Sliding Tackle','GK Diving', 'GK Handling','GK Kicking','GK Positioning','GK Reflexes'] for name in self.title: exec ('self.'+name+'=[]') for name in self.small_file: exec('self.' + name + '=[]') for i in range(len(self.details)): exec('self.details_' +str(i) + '=[]') def loadPage(self,url): time.sleep(random.random()) return requests.get(url, headers=self.headers).content def get_player_links(self,url): content = self.loadPage(url) html = etree.HTML(content) player_links=html.xpath("//div[@class='card']/table[@class='table table-hover persist-area']/tbody[@class='list']" "/tr/td[@class='col-name']/a[@role='tooltip']/@href") result=[] for link in player_links: result.append(self.baseURL[:-1]+link) return result #return [self.baseURL[:-1]+link for link in player_links] def next_page(self, url): content = self.loadPage(url) html = etree.HTML(content) new_page= html.xpath("//div[@class='pagination']/a/@href") if url == self.baseURL: return self.baseURL[:-1]+new_page[0] else: if len(new_page)==1: return 'stop' else: return self.baseURL[:-1]+new_page[1] def Get_player_small_field(self,html): content = html.xpath( "//div[@class='center']/div[@class='grid']/div[@class='col col-4']/div[@class='card calculated']/div[@class='field-small']" "/div[@class='lineup']/div[@class='grid half-spacing']/div[@class='col col-2']/div/text()") content=content[1::2] length=len(content) for i in range(length): exec ('self.'+self.small_file[i]+'.append('+'\''+content[i]+'\''+')') #return dict(zip(keys,values)) def Get_player_basic_info(self,html): player_name=html.xpath("//div[@class='center']/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/div[@class='info']/h1/text()") player_basic=html.xpath("//div[@class='center']/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/div[@class='info']/div[@class='meta ellipsis']/text()") exec ("self.player_name.append("+"\""+player_name[0]+"\""+")") exec ('self.basic_info.append(' +'\''+player_basic[-1]+'\''+')') def Get_rating_value_wage(self,html): overall_potential_rating = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/span[1]/text()") if len(overall_potential_rating)==0: overall_potential_rating=html.xpath("//div[1]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/span[1]/text()") value_wage = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/text()") if len(value_wage)==0: value_wage = html.xpath("//div[1]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/text()") exec('self.Overall_rating.append('+'\''+overall_potential_rating[0]+'\''+')') exec('self.Potential.append('+'\''+overall_potential_rating[1]+'\''+')') exec('self.Value.append(' + '\'' + value_wage[2] + '\'' + ')') exec('self.Wage.append(' + '\'' + value_wage[3] + '\'' + ')') # / html / body / div[1] / div / div[2] / div[1] / section / div[1] / div / span def Get_profile(self,html): profile=html.xpath( "//div[@class='center']/div[@class='grid']/div[@class='col col-12']/div[@class='block-quarter'][1]" "/div[@class='card']/ul[@class='pl']/li[@class='ellipsis']/text()[1]") exec('self.preferred_foot.append(' +'\''+ profile[0]+'\''+')') exec('self.weak_foot.append(' +'\''+ profile[1]+'\''+')') exec('self.skill_moves.append(' + '\'' + profile[2] + '\'' + ')') exec('self.international_reputation.append(' + '\'' + profile[3] + '\'' + ')') def Get_detail(self,html): #// *[ @ id = "body"] / div[3] / div / div[2] / div[9] / div / ul / li[1] / span[1] keys=html.xpath("//div[3]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[2]/text()") if(len(keys)==0): keys = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[2]/text()") values=html.xpath("//div[3]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[1]/text()") if (len(values)==0): values = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[1]/text()") values=values[:len(keys)] values=dict(zip(keys,values)) for i in range(len(self.details)): if self.details[i] in keys: exec ('self.details_'+str(i)+'.append('+'\''+values[self.details[i]]+'\''+')') else: exec ('self.details_'+str(i)+'.append('+'\'Nan\''+')') #return def start_player(self,url): content = self.loadPage(url) html = etree.HTML(content) #info= {} self.Get_player_basic_info(html) self.Get_profile(html) self.Get_rating_value_wage(html) self.Get_player_small_field(html) self.Get_detail(html) self.row_num+=1 def startWork(self): current_url=self.baseURL while(current_url!='stop'): print(current_url) player_links = self.get_player_links(current_url) # spawn创建协程任务,并加入到任务队列里 #print(player_links) jobs=[] for link in player_links: jobs.append(gevent.spawn(self.start_player, link)) #jobs = [gevent.spawn(self.start_player, link) for link in player_links] # 父线程阻塞,等待所有任务结束后继续执行 gevent.joinall(jobs) current_url=self.next_page(current_url) self.save() # 循环get队列的数据,直到队列为空则退出 def save(self): exec ('df=pd.DataFrame()') for name in self.title: exec ("df["+"\'"+name+"\'"+"]=self."+name) for name in self.small_file: exec ('df['+'\"'+name+'\"'+']=self.'+name) for i in range(len(self.details)): exec ('df['+'\"'+self.details[i]+'\"'+']=self.details_'+str(i)) exec ('df.to_csv(self.path,index=False)') if __name__ == "__main__": start = time.time() spider=FIFA21() spider.startWork() stop = time.time() print("\n[LOG]: %f seconds..." % (stop - start))
2. 对数据进行清洗和处理
通过查阅信息知道部分爬取下来的信息不是本文分析所需要的,故将不需要的信息删除掉。
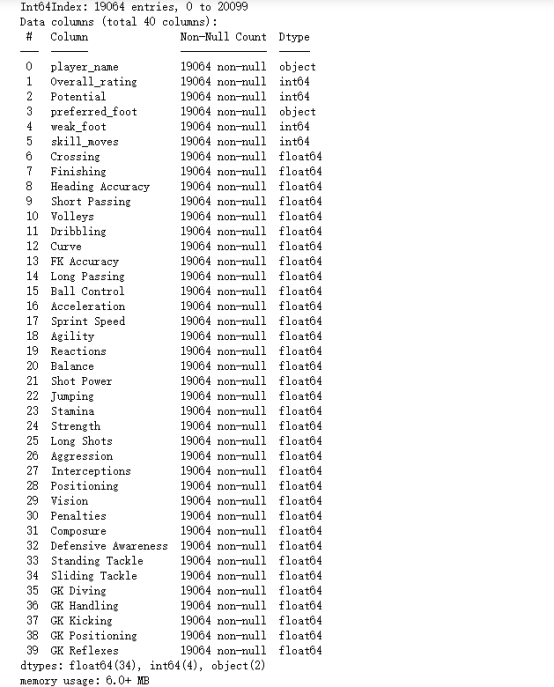
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns data=pd.read_csv('data.csv') #读入数据 data.info() #查看数据的信息 #选取自己需要的数据 left_data=data.iloc[:,:9] right_data=data.iloc[:,37:] data=pd.concat([left_data,right_data],axis=1) data.drop(['basic_info','Value','Wage'],axis=1,inplace=True) data.dropna(inplace=True) #删除缺失值 for index in data.columns[6:]: data[index]=data[index].astype('float64') data.info()
3. 数据分析与可视化
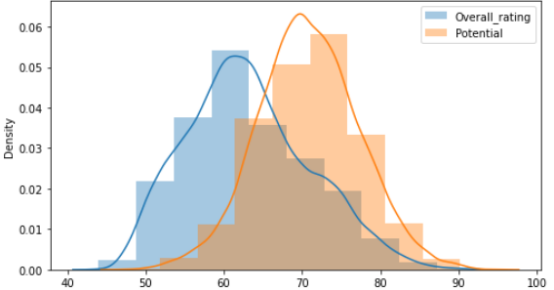
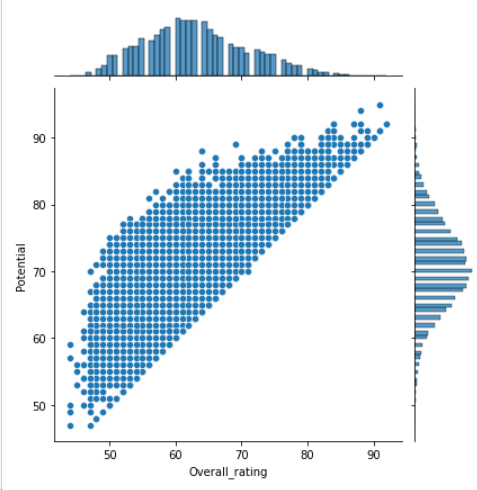
fig, ax= plt.subplots(nrows = 1, ncols = 2) fig.set_size_inches(14,4) sns.boxplot(data = data.loc[:,["Overall_rating",'Potential']], ax = ax[0]) ax[0].set_xlabel('') ax[0].set_ylabel('') sns.distplot(a = data.loc[:,["Overall_rating"]], bins= 10, kde = True, ax = ax[1], \ label = 'Overall_rating') sns.distplot(a = data.loc[:,["Potential"]], bins= 10, kde = True, ax = ax[1], \ label = 'Potential') ax[1].legend() sns.jointplot(x='Overall_rating',y = 'Potential',data =data,kind = 'scatter') fig.tight_layout()
查看potential和overall_rating各自的分布和关系
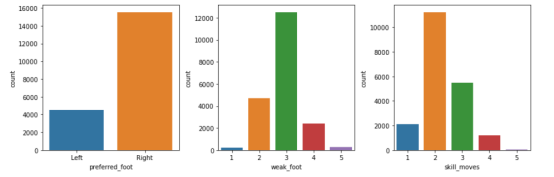
查看分类变量的分布
fig, ax = plt.subplots(nrows = 1, ncols = 3) fig.set_size_inches(12,4) sns.countplot(x = data['preferred_foot'],ax = ax[0]) sns.countplot(x = data['weak_foot'],ax = ax[1]) sns.countplot(x = data['skill_moves'],ax = ax[2]) fig.tight_layout()
两个变量之间散点图分析
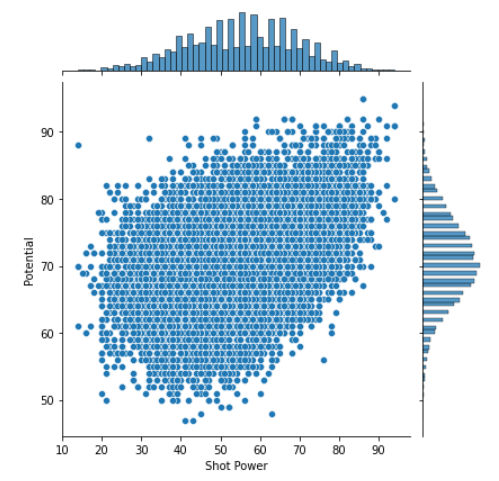
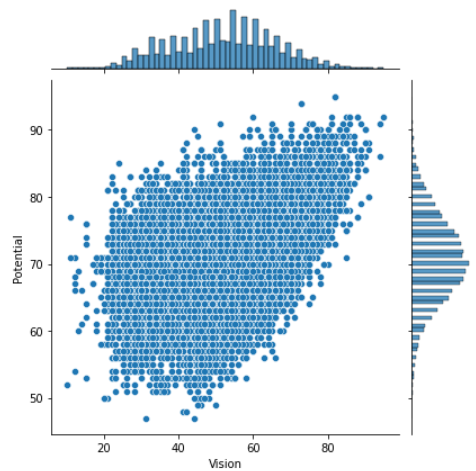
通过分析相关系数图,本文发现和Potential变量相关的变量有Overall_rating, Reactions和shot power等,做出散点图如下。
sns.jointplot(x='Reactions',y = 'Potential',data =data,kind = 'scatter')
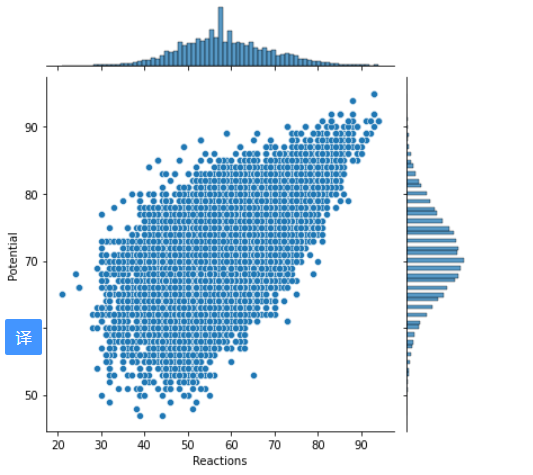
sns.jointplot(x='Shot Power',y = 'Potential',data =data,kind = 'scatter')
sns.jointplot(x='Vision',y = 'Potential',data =data,kind = 'scatter')
4. 建立回归模型
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split x=df.drop('Potential',axis=1) y=df['Potential'] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3) model=LinearRegression() model.fit(x_train,y_train) from sklearn.metrics import r2_score r2_score(y_test,model.predict(x_test))
模型最终的R方为0.50,效果较好。
5. 数据持久化
df.to_csv('df.csv')
保存为csv文件
6. 源码
爬虫
# 导入模块 import gevent from gevent import monkey monkey.patch_all() import time import requests import random from lxml import etree import pandas as pd class FIFA21(): def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"} self.baseURL ='https://sofifa.com/' self.path='data.csv' self.row_num=0 self.title=['player_name','basic_info','Overall_rating','Potential','Value','Wage', 'preferred_foot','weak_foot','skill_moves','international_reputation'] self.small_file=['LS','ST','RS','LW','LF','CF','RF','RW','LAM','CAM','RAM','LM','LCM','CM','RCM','RM','LWB', 'LDM','CDM','RDM','RWB','LB','LCB','CB','RCB', 'RB','GK'] self.details=['Crossing','Finishing','Heading Accuracy','Short Passing','Volleys','Dribbling,Curve', 'FK Accuracy','Long Passing','Ball Control','Acceleration','Sprint Speed','Agility','Reactions', 'Balance','Shot Power','Jumping','Stamina','Strength','Long Shots','Aggression','Interceptions','Positioning', 'Vision','Penalties','Composure','Defensive' 'Awareness','Standing Tackle','Sliding Tackle','GK Diving', 'GK Handling','GK Kicking','GK Positioning','GK Reflexes'] for name in self.title: exec ('self.'+name+'=[]') for name in self.small_file: exec('self.' + name + '=[]') for i in range(len(self.details)): exec('self.details_' +str(i) + '=[]') def loadPage(self,url): time.sleep(random.random()) return requests.get(url, headers=self.headers).content def get_player_links(self,url): content = self.loadPage(url) html = etree.HTML(content) player_links=html.xpath("//div[@class='card']/table[@class='table table-hover persist-area']/tbody[@class='list']" "/tr/td[@class='col-name']/a[@role='tooltip']/@href") result=[] for link in player_links: result.append(self.baseURL[:-1]+link) return result #return [self.baseURL[:-1]+link for link in player_links] def next_page(self, url): content = self.loadPage(url) html = etree.HTML(content) new_page= html.xpath("//div[@class='pagination']/a/@href") if url == self.baseURL: return self.baseURL[:-1]+new_page[0] else: if len(new_page)==1: return 'stop' else: return self.baseURL[:-1]+new_page[1] def Get_player_small_field(self,html): content = html.xpath( "//div[@class='center']/div[@class='grid']/div[@class='col col-4']/div[@class='card calculated']/div[@class='field-small']" "/div[@class='lineup']/div[@class='grid half-spacing']/div[@class='col col-2']/div/text()") content=content[1::2] length=len(content) for i in range(length): exec ('self.'+self.small_file[i]+'.append('+'\''+content[i]+'\''+')') #return dict(zip(keys,values)) def Get_player_basic_info(self,html): player_name=html.xpath("//div[@class='center']/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/div[@class='info']/h1/text()") player_basic=html.xpath("//div[@class='center']/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/div[@class='info']/div[@class='meta ellipsis']/text()") exec ("self.player_name.append("+"\""+player_name[0]+"\""+")") exec ('self.basic_info.append(' +'\''+player_basic[-1]+'\''+')') def Get_rating_value_wage(self,html): overall_potential_rating = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/span[1]/text()") if len(overall_potential_rating)==0: overall_potential_rating=html.xpath("//div[1]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/span[1]/text()") value_wage = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/text()") if len(value_wage)==0: value_wage = html.xpath("//div[1]/div[@class='grid']/div[@class='col col-12']" "/div[@class='bp3-card player']/section[@class='card spacing']/div[@class='block-quarter']/div/text()") exec('self.Overall_rating.append('+'\''+overall_potential_rating[0]+'\''+')') exec('self.Potential.append('+'\''+overall_potential_rating[1]+'\''+')') exec('self.Value.append(' + '\'' + value_wage[2] + '\'' + ')') exec('self.Wage.append(' + '\'' + value_wage[3] + '\'' + ')') # / html / body / div[1] / div / div[2] / div[1] / section / div[1] / div / span def Get_profile(self,html): profile=html.xpath( "//div[@class='center']/div[@class='grid']/div[@class='col col-12']/div[@class='block-quarter'][1]" "/div[@class='card']/ul[@class='pl']/li[@class='ellipsis']/text()[1]") exec('self.preferred_foot.append(' +'\''+ profile[0]+'\''+')') exec('self.weak_foot.append(' +'\''+ profile[1]+'\''+')') exec('self.skill_moves.append(' + '\'' + profile[2] + '\'' + ')') exec('self.international_reputation.append(' + '\'' + profile[3] + '\'' + ')') def Get_detail(self,html): #// *[ @ id = "body"] / div[3] / div / div[2] / div[9] / div / ul / li[1] / span[1] keys=html.xpath("//div[3]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[2]/text()") if(len(keys)==0): keys = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[2]/text()") values=html.xpath("//div[3]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[1]/text()") if (len(values)==0): values = html.xpath("//div[2]/div[@class='grid']/div[@class='col col-12']" "/div[@class='block-quarter']/div[@class='card']/ul[@class='pl']/li/span[1]/text()") values=values[:len(keys)] values=dict(zip(keys,values)) for i in range(len(self.details)): if self.details[i] in keys: exec ('self.details_'+str(i)+'.append('+'\''+values[self.details[i]]+'\''+')') else: exec ('self.details_'+str(i)+'.append('+'\'Nan\''+')') #return def start_player(self,url): content = self.loadPage(url) html = etree.HTML(content) #info= {} self.Get_player_basic_info(html) self.Get_profile(html) self.Get_rating_value_wage(html) self.Get_player_small_field(html) self.Get_detail(html) self.row_num+=1 def startWork(self): current_url=self.baseURL while(current_url!='stop'): print(current_url) player_links = self.get_player_links(current_url) # spawn创建协程任务,并加入到任务队列里 #print(player_links) jobs=[] for link in player_links: jobs.append(gevent.spawn(self.start_player, link)) #jobs = [gevent.spawn(self.start_player, link) for link in player_links] # 父线程阻塞,等待所有任务结束后继续执行 gevent.joinall(jobs) current_url=self.next_page(current_url) self.save() # 循环get队列的数据,直到队列为空则退出 def save(self): exec ('df=pd.DataFrame()') for name in self.title: exec ("df["+"\'"+name+"\'"+"]=self."+name) for name in self.small_file: exec ('df['+'\"'+name+'\"'+']=self.'+name) for i in range(len(self.details)): exec ('df['+'\"'+self.details[i]+'\"'+']=self.details_'+str(i)) exec ('df.to_csv(self.path,index=False)') if __name__ == "__main__": start = time.time() spider=FIFA21() spider.startWork() stop = time.time() print("\n[LOG]: %f seconds..." % (stop - start)) 数据分析和建模 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns data=pd.read_csv('data.csv') left_data=data.iloc[:,:9] right_data=data.iloc[:,37:] data=pd.concat([left_data,right_data],axis=1) data.drop(['basic_info','Value','Wage'],axis=1,inplace=True) data.dropna(inplace=True) for index in data.columns[6:]: data[index]=data[index].astype('float64') data.info() fig, ax= plt.subplots(nrows = 1, ncols = 2) fig.set_size_inches(14,4) sns.boxplot(data = data.loc[:,["Overall_rating",'Potential']], ax = ax[0]) ax[0].set_xlabel('') ax[0].set_ylabel('') sns.distplot(a = data.loc[:,["Overall_rating"]], bins= 10, kde = True, ax = ax[1], \ label = 'Overall_rating') sns.distplot(a = data.loc[:,["Potential"]], bins= 10, kde = True, ax = ax[1], \ label = 'Potential') ax[1].legend() sns.jointplot(x='Overall_rating',y = 'Potential',data =data,kind = 'scatter') fig.tight_layout() fig, ax = plt.subplots(nrows = 1, ncols = 3) fig.set_size_inches(12,4) sns.countplot(x = data['preferred_foot'],ax = ax[0]) sns.countplot(x = data['weak_foot'],ax = ax[1]) sns.countplot(x = data['skill_moves'],ax = ax[2]) fig.tight_layout() corr2 = data.select_dtypes(include =['float64','int64']).\ loc[:,data.select_dtypes(include =['float64','int64']).columns[:]].corr() fig,ax = plt.subplots(nrows = 1,ncols = 1) fig.set_size_inches(w=24,h=24) sns.heatmap(corr2,annot = True,linewidths=0.5,ax = ax) plt.savefig('1.png') sns.jointplot(x='Reactions',y = 'Potential',data =data,kind = 'scatter') sns.jointplot(x='Shot Power',y = 'Potential',data =data,kind = 'scatter') sns.jointplot(x='Vision',y = 'Potential',data =data,kind = 'scatter') sns.jointplot(x='Composure',y = 'Potential',data =data,kind = 'scatter') df=data[['Potential','Overall_rating','Short Passing','Long Passing','Ball Control','Reactions','Shot Power','Vision','Composure']] from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split x=df.drop('Potential',axis=1) y=df['Potential'] x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3) model=LinearRegression() model.fit(x_train,y_train) from sklearn.metrics import r2_score r2_score(y_test,model.predict(x_test)) df.to_csv('df.csv')
五.总结
在完成爬虫课程设计的过程中,会遇到很多问题,如在爬取过程中的防爬机制,打代码时不断的出错,本文需要主动的上网去找解决问题的办法,同时由于数据量大,时间长,本文更改了爬取的方式,使用多线程来对数据进行爬取。爬取数据时由于网页数据安排并不是特别简洁,故本文需要对网页数据的爬取进行一个一个的手动定位,比较麻烦。在数据分析时爬取的数据并非你全部都是本文后续分析的需要,故需要对数据进行筛选,同时数据存在一定量的缺失值,故本文对数据删除了缺失值。
达到了预期的目标与收获:
本次课程设计,让作者学会了爬虫的基本原理,数据清洗和处理的方式。其中,爬虫常用requests模拟请求网页,获取数据。同时深化了作者对于Sklearn库使用的能力,直接调用SKlearn库来对数据进行建模分析会使得效率更高。
需要改进的建议:
在进行线性回归时,加入更多数据使数据更具有预测性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号