Slimmable Neural Network【阅读笔记】
项目地址:https://github.com/JiahuiYu/slimmable_networks
不同的移动设备具有不同的存储资源和计算能力,同一个算法在不同设备中所需的时间是不同的。即使是同一个设备,也会由于运行的程序、电量等原因,造成分配给模型的资源有所不同。在移动设备上,我们通常对于算法的时间有比较高的要求(如在规定时间内完成运算)。这篇文章就是针对这个问题,希望同一个模型可以充分有效利用计算资源,对于资源多的设备增加模型宽度提升表现。目前已经有一些方法可以针对不同设备部署不同宽度的模型,但是仍然缺乏灵活性。Slimmable Neural Network可以在运行时快速调整宽度。
Slimmable Neural Network可以认为是不同网络宽度(channel数)子网络的集合,这些子网络共享参数。
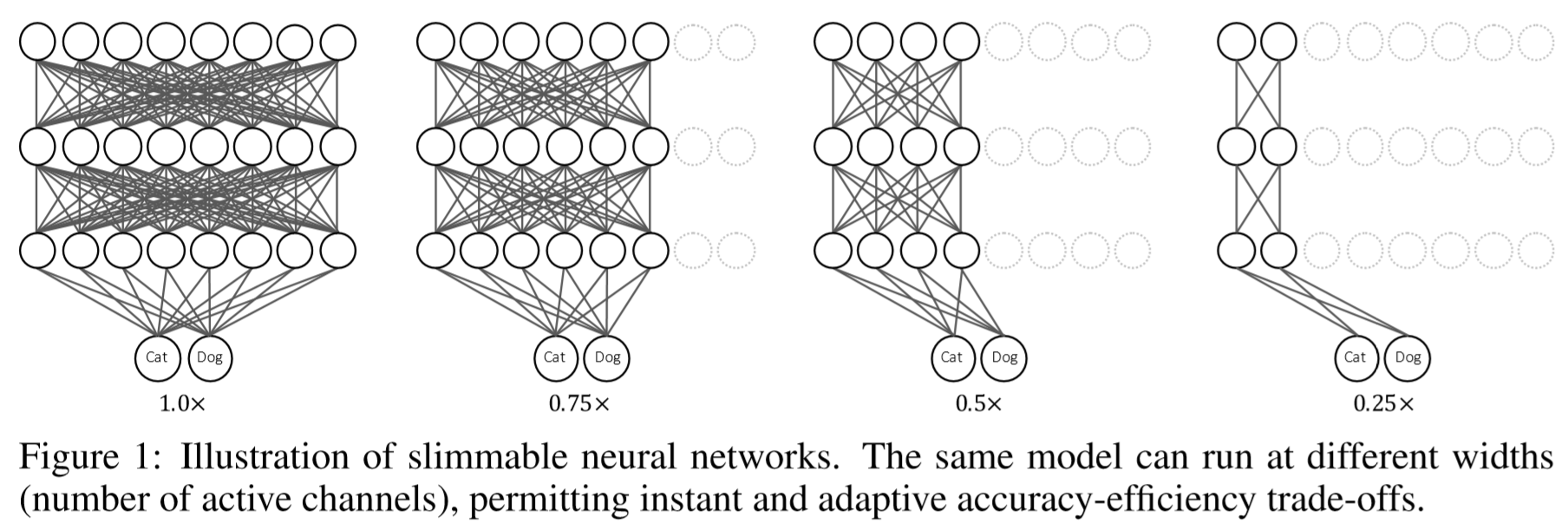
作者在联合训练这些子网络时发现,虽然训练时的表现很好,但模型在测试时的表现很差。他推测时BN层在训练和测试时统计量的差异造成的。
在训练时Batch Normalization使用的是当前的mini-batch的均值和方差进行归一化。但测试时使用的均值和方差是整个训练集均值和方差的估计。他是由每一个mini-batch的均值和方差以滑动平均的方式叠加得到的。在Slimmable Neural Network中,由于每个子网络宽度不同,每一层输出的均值和方差就不同,但他们都以叠加到整体的估计中。因此实际上测试时使用的均值和方差是所有子网络均值和方差的加权之和。
针对这种不一致问题,作者提出了Switchable Batch Normalization 的方法,不同的子网络使用独立的BN层,BN层的参数也是针对子网络独立进行计算的。
训练过程:
Loss采用所有子网络训练loss的un-weighted sum,优化所有子网络的平均准确度。

实验发现:
- 子网络个数对于表现的影响
发现子网络变多对表现的影响不大。
- width增加时,某个channel作用的改变
相同channel的功能非常接近(如某个channel,从关注白色信息改变为关注黄色信息)。发现浅层channel的均值、方差、scale、bias都非常接近,高层的存在一点差别。
理论来说联合训练会对每个网络增加了其他的限制导致联合训练的子网络表现不如单独训练的网络。但是文中实验表示,在某些情况下联合训练提升了结果。作者认为这个是由于隐式的模型蒸馏,大模型通过共享权重和联合训练将知识迁移到了小模型中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号