
对上一篇随笔做一个补充哈,Oracle对那个分组查询有一个不近人情的操作,就是对于分组查询 查询的字段必须只能是被分组的字段和分组函数。另外虽然可以单独使用分组函数,但是分组函数却不能在未分组情况下与其他字段同时查询。另外,分组函数不得作为where后的筛选条件。
select course,count(sno) from student group by course;//这是可以的
select course,score from student group by course;//查询与分组无关的其他字段是不允许的
select count(sno) from student;//单独使用分组函数可行
select *,count(sno) from student;//在不分组情况下,分组函数和其他字段共同查询时不允许的
而这些操作再mysql中是被允许的,这也说明了Oracle的语法比mysql更加严格。
接下来来谈谈自联表,分区表和视图这三种类表结构。
首先来看看自联表,这其实是一类特殊的数据表。数据库有一个表关联的设计,就是主外键设置,将数据分离存放。
自联表对一些分级明确的数据有天然的契合,尤其是分级不多但是各级不同数据太多的情况。例如国家行政数据表,公司职位与员工统一表等。
而自联表恰恰是反其道而行,将数据分级存储,并且对于数据的查询自联表有一个自带的查询秘技。
select ... from table start with [rootid] connect by prior [rootid = level];
//自联表的原理就像树查询一样。从根节点一路向叶子节点查询,最后将每条分支遍历查出。
//start with 后就是根节点id,connect by prior 后就是父节点与子节点关联
注:connect by prior 后的关联顺序决定查询顺序。如果是 父一级关联子一级,则是从当前节点一路向下查询所有叶子结点的分支;如果是子一级关联父一级,则就是从当前节点向根结点反查。
connect by prior 类似join on后面,不仅可以添加固有的属性相等关联条件,也可以通过and 连接其他筛选条件尽量避免外加where降低性能
下面就用一个例子说明:先来建一张表(通过subaddr关联子父节点)
create table address(
id int primary key not null,
addrname varchar(20),
addrlevel int, 地址所在层级
subaddr int 当前地址隶属上一级编号
);
insert into address values(1,'中国',1,0);
insert into address values(2,'江苏',2,1);
insert into address values(3,'南京',3,2);
insert into address values(4,'无锡',3,2);
insert into address values(5,'浙江',2,1);
insert into address values(6,'杭州',3,5);
insert into address values(7,'温州',3,5);
insert into address values(8,'美国',1,0);
insert into address values(9,'俄亥俄州',2,8);
insert into address values(10,'哥伦布',3,9);
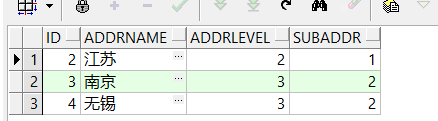
现在要查表中江苏省下辖的城市?
select * from address start with id = 2 connect by prior id =subaddr;
//首先这是正向差,以江苏省为当前结点,父节点关联子节点 ——结果遍历江苏省下所有分支(如果有乡镇作为叶子会查到乡镇停止)
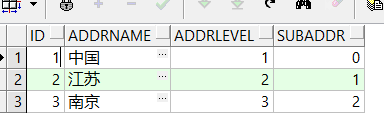
那要查询南京市的上级行政单位
select * from address start with id = 3 connect by prior subaddr = id order by addrlevel;
//首先这是反向查,以南京市为当前节点,子节点关联父节点 ——结果向最大现在单位“国家”反查,最后根据行政等级排序
如果要查询国家下的所有省一级单位?
select * from address start with addrlevel = 1 connect by prior id = subaddr and addrlevel < 3;
//以国家为根结点开始正向查,父节点关联子节点,额外加上一个行政等级筛选,这个可以在where但是放在connect by prior上性能可以得到优化
其实自联表查询就是利用树递归遍历的算法查询数据,所以其速度是相当快的,但是递归查询也是极其消耗资源的。综上,其性能也不是很好。
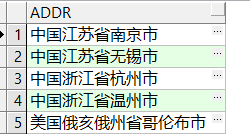
最后来看一个附加问题:将表行转列,查询结果形式为xxx国xxx省xxx市?
select a1.addrname||a2.addrname||'省'||a3.addrname||'市' addr from address a1 left join
address a2 on a1.id = a2.subaddr left join
address a3 on a2.id = a3.subaddr where a1.addrlevel = 1;
分区表是Oracle的一种特有表。Oracle是一款大型数据库,可以承载大量数据,但是一旦数据量太大,则对于查询而言是一种痛苦。分区表则可以缓解这种痛苦。
分区表借鉴了分布式的思想,分区表可以将一张大表的所有数据按某种标准划分成不同区,这些区是实实在在的物理分区,这些区有独立的文件存储,但意义上它们仍属于一张表。这样对于不同物理分区,可以实现并发查询,大大提高查询效率。另外分区表也减少数据损毁的损失,维护起来也比较方便。
分区表有几种常见的类型:
-
范围分区表,以某个字段的值范围作为分区标准,应用最广。例如以日期等
create table Name(...) partition by range(col){ partition by parName less than(value) tablespace tspaceName; ... partition by parName less than(maxvalue) tablespace tspaceName;//最后有一个最大值兜底 } -
哈希分区表,就是以字段值的哈希值分区。而且哈希分区可以帮助每个分区的数据量相对平衡,但是数据的去向就不容易明确。哈希分区支持多个字段值同时作为标准。
create table tName(...) partition by hash(col){ partition parName tablespace tspaceName; ... partition parName tablespace tspaceName; }哈希分区实现分区时依赖哈希算法,而哈希算法则是基于哈希函数。所以对于哈希分区只需要确定具体要分区几个区就行。建议分区数取2的n次幂,这样会使数据发布更加均匀。
另外,哈希分区的特殊性可以简写分区表空间所属。
create table xxx(...) partition by hash(col) partitions 分区数 store in (tspace1,tspace2,...); //当然这里面也可以只写一个表空间,如果只有当前表空间一个,则store in可以省略 //分区名默认由系统分配,下面有专门查看的语句 -
列表分区。列表分区是基于某个字段的值是固定的几种。例如性别,班级等。这实际上就是一个按枚举数据进行分区。如果列表分区建立好,再插入一条值不在列表分区中的记录,是会失败的。除非,再专门添加一项分区。
create table xxx(...) partition by list(col)( partition pname1 values(val1,val2,...) tablespace tspace; ... partition pnamen values(valn) tablespace tsapce; partkition pnamem values(default) tablespace tsapce; );列表分区不允许以多个字段作为分区条件,但是分区值可以多个一组。在分区时应尽量将所有可能的值都加上,避免后期插入不包括的记录导致报错。通常可以建立一个default分区避免上述错误。
-
组合分区。有以上三个分区其中两个联合进行分区。如果一张表使用三种单一分区都嫌分区很大或者对分区有其他一些要求,则可以将某两个单一组合进行分区。说白了就是二级分区,主分区内再建子分区。在10的版本里,常见的两种组合分区:range-hash,range-list。即主分区是范围分区,在range分区捏在实现哈数分区或列表分区。
create table xxx(...) partition by range(col1) subpartition by list(col2)( partition pname1 less than(val1) tablespace tspace( subpartition subpname11 values(vall1) tablespace tspace; ... ), partition pname2 less than(val2) tablespace tspace( subpartition subpname21 values(vall1) tablespace tspace; ... ), ... ); //不同主分区的子分区无需同名,与主分区一样各自为营 create table xxx(...) partition by range(col1) subpartition hash(col2) subpartitions 子分区数 store in (tspace1,tspace2,...) ( partition pname1 less than (val1) tablespace tspace; ... );
oracle 11g版本中有拓展出其他组合分区:如range-range,list-range,list-list,list-hash,语法类似。另外11g还推出interval分区和虚拟列分区。
分区一般是面向虚拟优化的,但是如果有时候想要查看某个分区的数据,可以用下面语法查看。
//查询指定分区
select ... from tableName partition(parName);
//查看表的分区目录
select * from user_tab_partitions where tabe_name='大写表名';
//查看当前用户下属的所有分区表
select * from user_part_tables;
//查看分区表使用分区字段
select * from user_part_key_columns [where object_type='TABLE' and name=''];
//查看当前用户下属的组合分区表
select * from user_tab_subpartitions;
//查看组合分区表使用的分区列、
select * from user_subpart_key_columns [object_type='TABLE' and name=''];
如果在分区已经创建好的基础上,想要额外再添加一个分区(如果分区容量到达极限)。但是增加分区意味着将其他(至少一个)分区数据进行分流,中间一旦出错就GG。务必要小心翼翼。
注:增加分区产生分流可能需要改动默认分区的名,方便按序号增加分区。
alter table Name rename partition pname to newPname;
删除(默认)分区
alter table Name drop partition pname;
删除分区数据保留结构
alter table Name truncate partition pname;
合并分区
alter table Name merge partition pname1,pname2,... into newPname;
-
对于range分区表增加分区,要面向两种情况,有maxvalue分区,无maxvalue分区。如果没有maxvalue,直接
alter table Name add partition pname less than (value);如果有maxvalue(默认)分区,就不能像上面那样直接add,需要对maxvalue分区split。
alter table Name split partition maxvalue分区名 at (value) into (partition 新增分区名,partition maxvalue分区名); -
对于有默认分区的表,实现增加分区使用split拆分默认分区是及其耗费时间的。效率比较低。不妨试试交换分区技术。这种方式效率相当高,可以实现数据快速转移,一般在数据加载提速、历史数据清除等方面有奇效,它是直接修改数据的物理位置所以速度快。言归正传,来谈谈如何通过交换分区实现增加分区:首先创建一个承载默认分区数据的临时表
create table xxxDefault as (select * from tableName where 1=2);然后将目标表的默认分区交换到临时表上alter table tableName exchange partition defaultpName with table xxxDefault;然后将目标表的默认分区删除,再添加主分区和默认分区;最后在将临时表的数据重新插入到 目标表insert into tableName select * from xxxDefault。注:这里有一点要强调,交换技术要求双方约束(索引)一致
另外立一个flag,最后用insert恢复数据感觉有点low,哪天试试能不能用交换分区技术将数据交换回来。这里只是求稳使用insert。
最后再来说一下视图,这可是老朋友了。MySQL也是存在视图这种东西。视图就是一个动态查询数据集,存放指定字段数据结合体。不占用物理空间,从基表直接映射。
还有一种物化视图,又叫快照。这是要占用空间的。
既然视图脱胎于实际表,实际表(基表)对应数据产生变化,视图数据也会对应发生变化,且视图存在,其基表不能轻易删除。
存在即合理,视图可以跨表将不同表的数据排列展示;也相当于将那些复杂的查询逻辑具体化为一张表,方便使用;另外视图相当于基表的替代品,不同用户可以访问视图查询数据,而不能直接接触基表查询敏感数据;视图也可以赋权,方便对用户限权。
创建视图
create or replace view viewName
[col1,col2,...] //列别名
as select ... //查询基表
[with check opinion] //针对增删改,默认。但是操作的数据仅限视图数据范围内(包括插入)
[with read only]; //只读,与上面只取其一
对于多表联查获得的视图,如果视图中有主外键关联,才能实现增删改(影响基表)。
事实上,视图一般不轻易做增删改操作,如果想操作,为什么不直接对基表操作呢?
删除视图
drop view viewName;
视图删除后,其他引用该视图的视图或存储过程等对象都将失效。
查看视图
视图相关表
dba_views,all_views,user_views //分别是所有,可访问,本用户所有的视图
dba_tab_columns,all_tab_columns,user_tab_columns //对应上面的视图的所有列
select view_name,text from xxx where table_name='大写视图名';

 浙公网安备 33010602011771号
浙公网安备 33010602011771号