


PostgreSQL流复制
0、前言
之前也做了一些流复制的实验,今天就想着把了解的PostgreSQL流复制的内容总结下,整理了这篇文章。
1、概述
1.1、什么是流复制?
如果有人问你PostgreSQL的流复制究竟是什么?你大概会说通过wal日志来进行数据同步之类的,的确如此,流复制大概就是这么回事。
但是准确的来说:PostgreSQL通过wal日志来传送的方式有两种:基于文件的日志传送和流复制。
不同于基于文件的日志传送,流复制的关键在于“流”,所谓流,就是没有界限的一串数据,类似于河里的水流,是连成一片的。因此流复制允许一台后备服务器比使用基于文件的日志传送更能保持为最新的状态。
比如我们有一个大文件要从本地主机发送到远程主机,如果是按照“流”接收到的话,我们可以一边接收,一边将文本流存入文件系统。这样,等到“流”接收完了,硬盘写入操作也已经完成。
1.2、流复制发展历史
流复制之前的手段:
像我们上面说的,pg在流复制出现之前,使用的就是基于文件的日志传送:对wal日志进行拷贝,因此从库始终落后主库一个日志文件,并且使用rsync工具同步data目录。
而流复制出现是从2010年推出的pg9.0开始的,其历史大致为:
- 起源:pg9.0开始支持流式物理复制,用户可以通过流式复制,构建只读备库
(主备物理复制,块级别一致)。流式物理复制可以做到极低的延迟(通常在1毫秒以内)。 - 同步流复制:pg9.1开始支持同步复制,但是当时只支持一个同步流复制备节点(例如配置了3个备,只有一个是同步模式的,其他都是异步模式)。同步流复制的出现,保证了数据的0丢失。
- 级联流复制:pg9.2支持级联流复制。即备库还可以再连备库。
- 流式虚拟备库:pg9.2还支持虚拟备库,即就是只有WAL,没有数据文件的备库。
- 逻辑复制:pg9.4开始可以实现逻辑复制,逻辑复制可以做到对主库的部分复制,例如表级复制,而不是整个集群的块级一致复制。
- 增加多种同步级别:pg9.6版本开始可以通过synchronous_commit参数,来配置事务的同步级别。
1.3、流复制概述
流复制其原理为:备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record。
PostgreSQL物理流复制按照同步方式分为两类:
- 异步流复制
- 同步流复制
物理流复制具有以下特点:
1、延迟极低,不怕大事务
2、支持断点续传
3、支持多副本
4、配置简单
5、备库与主库物理完全一致,并支持只读
2、流复制基础
在学习流复制之前,我们先来了解一些相关的基础知识。
2.1、wal日志介绍
这里简单介绍下:
WAL日志机制保证了事务的持久性和数据完整性,同时又避免了频繁IO对性能的影响。
为了保证数据库中数据的持久性,即事务提交后,即使数据库出现故障也能保证数据的可靠性。最简单的方法就是:数据一提交就刷到磁盘上。但是这样对于事务非常频繁的系统,一有事务提交就去刷新脏数据,会对数据库性能产生非常不好的影响。因此使用wal日志来记录数据的更改,这样每当发生事务提交,只需要通过提交wal日志即可,而且wal日志的提交是顺序的,性能也很高。
2.2、wal日志解读
对数据库操作会以record为单位首先记录到wal日志中,在checkpoint时才对数据进行刷
盘(background writer会定时刷脏数据,但最终还是都由checkpoint确认都刷盘成功)。
聊了这么久wal日志,我们都还不知道wal日志在哪?长啥样。。。
wal日志位置:
$PGDATA/pg_wal(pg10之前叫pg_xlog)
wal日志文件命名规则:
我们看到的wal日志是这样的:000000010000000100000092
其中前8位:00000001表示timeline;
中间8位:00000001表示logid;
最后8位:00000092表示logseg
wal日志LSN编号规则:
1/920001F8(高32位/低32位)
对照关系:
1、wal日志的logseg前6位始终是0,后两位是LSN低32位/16MB(2*24),即LSN的前两位。如上例中logseg最后两位是92,LSN低32前两位也是92。
2、LSN在wal日志中的偏移量即LSN低32位中后24位对应的十进制值。
例如当前wal日志偏移量为504
bill=# select pg_walfile_NAME_OFFSET(pg_current_wal_lsn()); pg_walfile_name_offset -------------------------------- (000000010000000100000092,504) (1 row) bill=# select x'1F8'::int; int4 ------ 504 (1 row)
2.3、wal日志内部详解
接下来我们来看看wal日志里面究竟记录的是些什么内容。如果你直接查看wal日志,可能会收到下面这样的提示:
因为wal日志是二进制格式的文件,不过我们可以使用pg_waldump这个工具来将其转换成可读的文件。
例1:
首先来看看insert数据时wal日志里面记录了些什么。
bill=# begin; BEGIN bill=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 1/92021290 (1 row) bill=# insert into tbl values(1,'bill'); INSERT 0 1 bill=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 1/92021308 (1 row) bill=# end; COMMIT
接下来我们看看wal日志里面内容:可以看到wal日志里面记录了上面的insert操作。
例2:
我们再看看update时wal日志里面记录的内容:
bill=# select pg_current_wal_lsn(); pg_current_wal_lsn -------------------- 1/92021450 (1 row) bill=# update tbl set info = 'foucus' where id = 1; UPDATE 1

这里简单介绍下这条记录的内容:
rmgr: Heap len (rec/tot): 65/ 177, tx: 717, lsn: 1/92021450, prev 1/92021418, desc: HOT_UPDATE off 1 xmax 717 flags 0x20 ; new off 2 xmax 0, blkref #0: rel 1663/16395/17623 blk 0 FPW
- rmgr: Heap :PostgreSQL内部将WAL日志归类到20多种不同的资源管理器。这条WAL记录所属资源管理器为 Heap,即堆表。除了Heap还有Btree,Transaction等。
- len (rec/tot): 65/ 177:wal记录的长度。
- tx: 717: 事务号。
- lsn: 1/92021450:本条wal记录的lsn。
- prev 1/92021418:上条wal记录的lsn。
- desc: HOT_UPDATE off 1 xmax 717 flags 0x20 ; new off 2 xmax 0: 这是一条热更新类型的记录,旧数据
offset为1,xmax为717。旧tuple在page中的位置为1(即ctid的后半部分),新tuple在page中的位置为2。 - blkref #0: rel 1663/16395/17623 blk 0 :引用的第一个page(新tuple所在page)所属的堆表文件为1663/13543/16469,块号为0(即ctid的前半部分)
3、流复制原理
3.1、日志提交过程
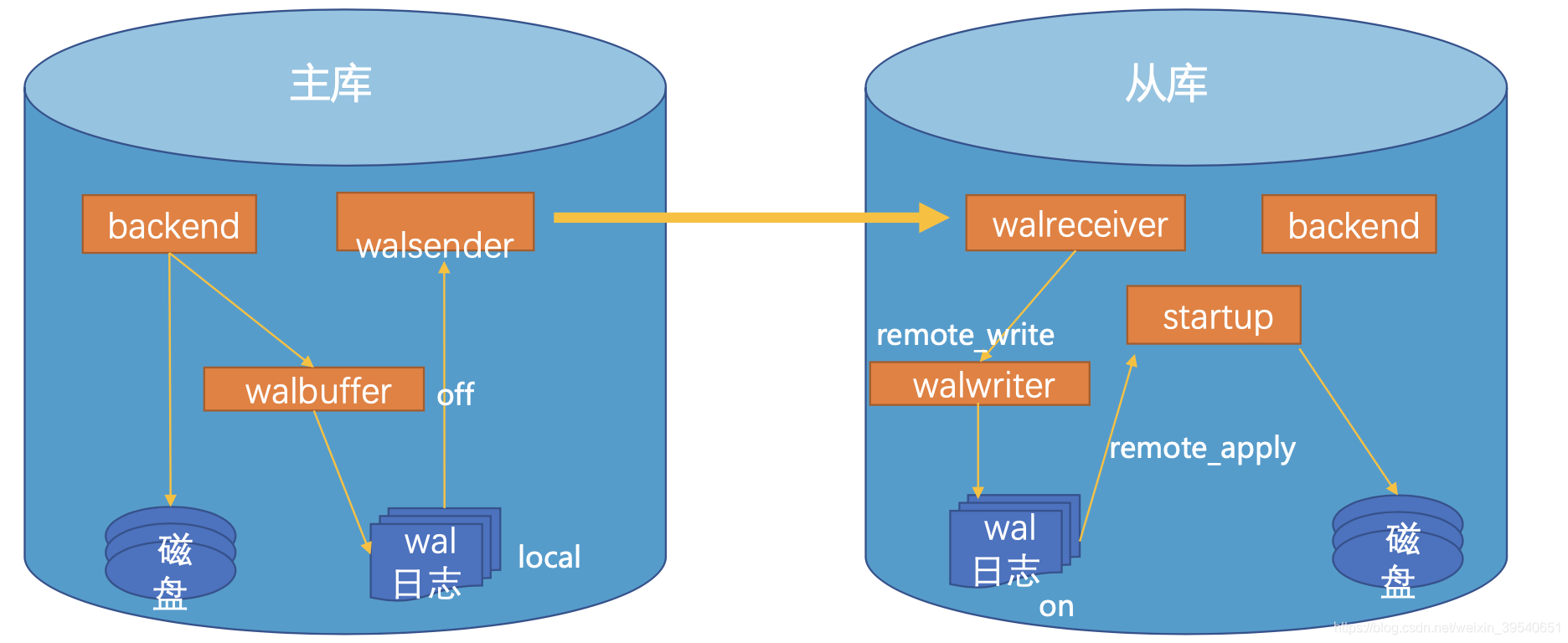
从上图我们可以看到流复制中日志提交的大致流程为:
1、事务commit后,日志在主库写入wal日志,还需要根据配置的日志同步级别,等待从库反馈的接收结果。
2、主库通过日志传输进程将日志块传给从库,从库接收进程收到日志开始回放,最终保证主从数据一致性。
3.2、流复制同步级别
PostgreSQL通过配置synchronous_commit (enum)参数来指定事务的同步级别。我们可以根据实际的业务需求,对不同的事务,设置不同的同步级别。
synchronous_commit = off # synchronization level;
# off, local, remote_write, or on
- remote_apply:事务commit或rollback时,等待其redo在primary、以及同步standby(s)已持久化,并且其redo在同步
standby(s)已apply。 - on:事务commit或rollback时,等待其redo在primary、以及同步standby(s)已持久化。
- remote_write:事务commit或rollback时,等待其redo在primary已持久化; 其redo在同步standby(s)已调用write接口(写到 OS, 但是还没有调用持久化接口如fsync)。
- local:事务commit或rollback时,等待其redo在primary已持久化;
- off:事务commit或rollback时,等待其redo在primary已写入wal buffer,不需要等待其持久化;
不同的事务同步级别对应的数据安全级别越高,对应的对性能影响也就越大。上述从上至下安全级别越来越低。
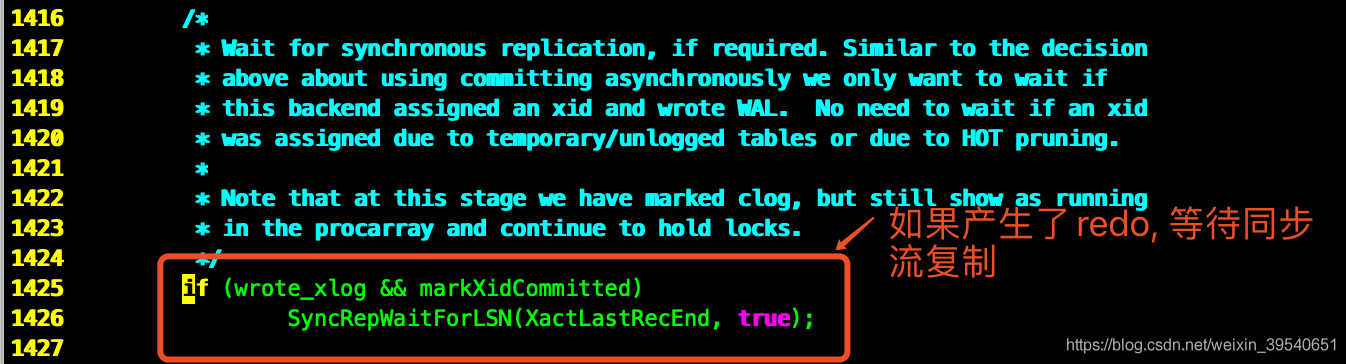
详细的同步流复制原理见:
CommitTransaction @ src/backend/access/transam/xact.c
RecordTransactionCommit @ src/backend/access/transam/xact.c

4、流复制配置过程
PostgreSQL物理流复制大致过程为:
1、PG软件安装
2、postgresql.conf参数配置
3、pg_hba.conf配置
4、pg_basebackup方式部署备库
5、配置简单
6、备库与主库物理完全一致,并支持只读
4.1、异步流复制参数配置
postgresql.conf :
wal_level = replica # minimal, replica, or logical max_wal_senders = 10 wal_keep_segments = 1024 hot_standby = on
pg_hba.conf :
host replication postgres # max number of walsender processes # in logfile segments, 16MB each; 0 disables 192.168.7.180/32 md5
standby recovery.conf :
recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password=xxx
4.2、同步流复制参数配置
postgresql.conf :
wal_level = replica # minimal, replica, or logical max_wal_senders = 10 # max number of walsender processes wal_keep_segments = 1024 # in logfile segments, 16MB each; 0 disables hot_standby = on synchronous_commit = remote_write、on、remote_apply synchronous_standby_names = 'standby2'
pg_hba.conf :
host replication postgres 192.168.7.180/32 md5
standby recovery.conf :
recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password=xxx application_name=standby2'
另外我们可以通过设置synchronous_standby_names参数来指定一个支持同步复制的后备服务器的列表,其支持格式大致为:
1、synchronous_standby_names =standby_name [, ...] 2、synchronous_standby_names =[FIRST] num_sync ( standby_name [, ...]) 3、synchronous_standby_names =ANY num_sync ( standby_name [, ...] )
4.3、主备切换流程
1、关闭主库,建议使用-m fast模式关闭。 2、在备库上执行pg_ctl promote命令激活备库,如果recovery.conf变成recovery.done表示 备库已切换成为主库。 3、这时需要将老的主库切换成备库,在老的主库的 $PGDATA目录下创建recovery.conf文 件(如果此目录下不存在recovery.conf文件,可以根据$PGHOME/recovery.conf. sample模板文件复制一个,如果此目录下存在recovery.done文件,需将recovery.done文件重命名为 recovery.conf),配置和老的从库一样,只是primary_conninfo参数中的IP换成对端IP。 4、启动老的主库,这时观察主、备进程是否正常,如果正常表示主备切换成功。
4.4、复制槽slot
因为pg在归档模式下,对于已经完成归档的wal日志会自动清理,所以提供了复制槽来避免主库在所有的备库收到 WAL 日志之前不会移除它们,并且主库也不会移除可能导致恢复冲突的行,即使备库断开也是如此。
例子:
创建一个复制槽:
bill=# SELECT * FROM pg_create_physical_replication_slot('node_a_slot'); slot_name | lsn -------------+----- node_a_slot |
bill=# SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active -------------+-----------+-------- node_a_slot | physical | f (1 row)
要配置后备机使用这个槽,在备库的recovery.conf中应该配置 primary_slot_name,例如:
standby_mode = 'on' primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password='xxx' primary_slot_name = 'node_a_slot'
5、pg12流复制新特性
PostgreSQL12中流复制有了一些改变:
把recovery.conf的内容全部移入postgresql.conf,配置恢复、archive based standby、stream based standby,都在postgresql.conf中。postgresql.conf以及对应的两个signal文件来表示进入recovery 模式或standby模式。
例子:
1、典型恢复模式配置
postgresql.conf:
# stream恢复模式配置 #primary_conninfo = '' 或 # archvie恢复模式配置 #restore_command = '' hot_standby = on # 配置是否跨时间线 #recovery_target_timeline = 'latest' # 配置恢复目标,例如 # 立即(达到一致性即停止恢复)、时间、XID、restore point name, LSN. #recovery_target = '' # 'immediate' to end recovery as soon as a # consistent state is reached # (change requires restart) #recovery_target_name = '' # the named restore point to which recovery will proceed # (change requires restart) #recovery_target_time = '' # the time stamp up to which recovery will proceed # (change requires restart) #recovery_target_xid = '' # the transaction ID up to which recovery will proceed # (change requires restart) #recovery_target_lsn = '' # the WAL LSN up to which recovery will proceed # (change requires restart) #recovery_target_inclusive = on # Specifies whether to stop: # just after the specified recovery target (on) # just before the recovery target (off) # (change requires restart) # 恢复目标到达后,暂停恢复、激活、停库 #recovery_target_action = 'pause' # 'pause', 'promote', 'shutdown' # (change requires restart)
在 $PGDATA目录中,touch recovery.signal
2、典型standby模式配置
postgresql.conf:
# stream恢复模式配置 #primary_conninfo = '' 或 # archvie恢复模式配置 #restore_command = '' hot_standby = on # 配置是否跨时间线 #recovery_target_timeline = 'latest'
在 $PGDATA目录中,touch standby.signal
3、如果standby.signal , recovery.signal两个文件都配置了,则优先为standby mode

 浙公网安备 33010602011771号
浙公网安备 33010602011771号