
第一次个人编程作业
| 软件工程 | 班级链接 |
|---|---|
| 作业要求 | 作业要求链接 |
| 作业目标 | PSP表格记录+查重代码实现+GitHub过程记录 |
| github地址 |
psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 50 |
| Estimate | 估计这个任务需要多少时间 | 400 | 700 |
| Development | 开发 | 30 | 50 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 40 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 300 | 420 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 40 | 60 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 30 | 40 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 1130 | 1730 |
计算模块实现方法
使用python编写,流程查阅资料后汇总得
1. 首先实现分词,采用jieba接口
结巴分词支持3中分词模式:
1,全模式:把句子中的所有可以成词的词语都扫描出来,
2, 精确模式:试图将文本最精确的分开,适合于做文本分析。
3,搜索引擎模式:在精确的基础上对长词进行进一步的切分。
这里采用精确模式:
seg_list = jieba.cut("香农在信息论中提出的信息熵定义为自信息的期望")
print(" ".join(seg_list))
其输出结果为
2. 使用正则表达去除html标签及符号等
代码举例
str_first = re.sub('<.*?>',"",str) #匹配所有html标签并用“”代替
str_enfin = str_first.replace('/n',"") #将换行符替换成空
3. 采用TF-IDF统计词频率并构造用于算法的向量
TF-IDF:一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。

4. 使用余弦相似性算法求值
设向量a和向量向量b,他们的夹角的余弦计算如下

余弦相似度算法代码实现
def CosSimilarity(UL,p1,p2):
si = GetSameItem(UL,p1,p2)
n = len(si)
if n == 0:
return 0
s = sum([UL[p1][item]*UL[p2][item] for item in si])
den1 = math.sqrt(sum([pow(UL[p1][item],2) for item in si]))
den2 = math.sqrt(sum([pow(UL[p2][itme],2) for item in si]))
性能测试图
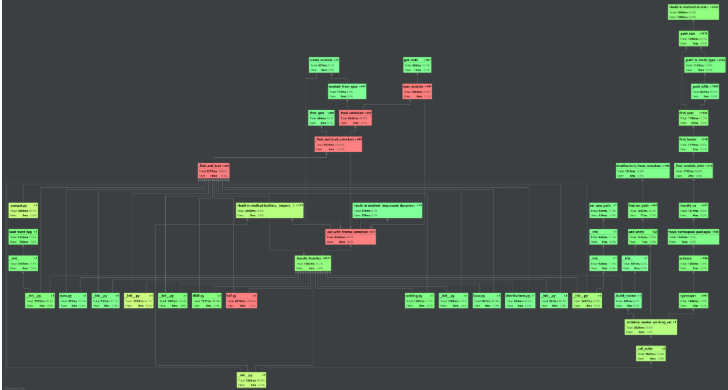
模块部分单元测试结果

