

| 这个属于哪个课程 | 23计科34班 |
|---|---|
| 这份作业的要求在哪里 | 个人项目 |
| 这个作业的目标 | 学会怎样去实现一个完整的项目 |
一、Github作业链接:https://github.com/dududu1012/dududu1012/tree/main/3123004500/PaperPlagiarismChecker
二、PSP表格(预估耗时与实际耗时)
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 90 | 90 |
| Esitimate | 估计这个任务需要多少时间 | 45 | 60 |
| Development | 开发 | 240 | 300 |
| Analysis | 需求分析(包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 60 | 60 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 60 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体代码 | 60 | 60 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试、修改代码、提交修改) | 60 | 90 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 60 | 60 |
| Size measurement | 计算工作量 | 10 | 10 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 20 |
| 合计 | 1015 | 1110 |
三、计算模块接口的设计与实现过程
1.代码组织结构设计:
本项目采用单一主类 + 功能模块化方法的设计模式,将所有核心功能封装在PaperPlagiarismChecker类中,通过不同方法实现单一职责原则。
# 项目结构展示
PaperPlagiarismChecker
├─ 文件操作模块
│ ├─ validateFile():验证文件有效性
│ └─ readFile():读取文件内容
├─ 文本预处理模块
│ ├─ preprocessText():文本清洗与标准化
│ └─ filterEmptyTokens():过滤空标记
├─ 特征提取模块
│ ├─ selectNGramSize():动态选择n-gram粒度
│ └─ extractNgramSet():提取n-gram特征集合
├─ 相似度计算模块
│ ├─ calculateSimHash():计算SimHash值
│ ├─ murmurHash3():辅助哈希算法
│ ├─ calculateHammingDistance():计算海明距离
│ └─ calculateSimHashSimilarity():计算相似度
└─ 输出模块
├─ outputCurrentResult():输出查重结果
├─ logCheckResult():记录查重日志
└─ logError():记录错误信息
2.核心算法:Simhash算法
(一)算法关键说明:
- 动态 n-gram 特征提取
根据文本长度自动选择 1-gram 或 2-gram:短文本用 1-gram 避免特征稀疏,长文本用 2-gram 保留更多上下文信息
使用 HashSet 存储 n-gram 特征,自动去重同时提高查找效率 - SimHash 算法优化
采用 MurmurHash3 而非 Java 原生哈希:计算速度更快,分布更均匀,减少哈希碰撞
64 位向量设计:平衡计算效率与精度,相比 128 位向量降低计算复杂度 - 相似度转换机制
基于海明距离的线性转换:相似度 = 1 - 海明距离/64
确保结果在 [0,1] 区间,直观反映文本重合度
(二)算法独到之处:
- 自适应特征粒度: 不同于固定 n 值的实现,根据文本长度动态调整 n-gram 粒度,在处理不同长度文本时保持稳定性
- 工程化细节优化:
异常处理完善:文件操作全流程异常捕获与日志记录
资源管理:自动创建目录,避免路径不存在导致的错误 - 混合文本支持: 正则表达式设计同时支持中英文文本处理,解决多语言场景下的字符过滤问题
- 可追溯性: 详细日志记录机制,保存每次查重的关键参数(哈希值、n 值、token 数量等),便于结果验证和问题排查
四、计算模块接口部分的性能改进
1.定位性能瓶颈:
在改进前,需先通过 JProfiler/IDEA 自带性能分析工具 找到核心耗时点。对原代码分析后,发现3个关键性能瓶颈:
- extractNgramSet() 方法: 生成n-gram时频繁使用StringBuilder拼接字符串,产生大量临时对象,触发频繁 GC(垃圾回收),尤其处理长文本(如 10000 字以上论文)时耗时显著。
- calculateSimHash() 方法: 对n-gram集合的遍历和向量更新是 “串行执行”,当n-gram数量达数万级时,CPU利用率低,计算耗时随文本长度线性增长。
- murmurHash3() 方法: 原实现通过 String.getBytes(StandardCharsets.UTF_8) 转换字符,该操作会额外创建字节数组,且UTF-8编码转换存在一定开销,占整体哈希计算耗时的30%+。
2.改进思路:
- 针对extractNgramSet(): 自定义NGramHolder类,直接引用原tokens数组的片段(记录起始 / 结束索引),不生成新字符串;仅在需要实际字符串时(如哈希计算)才拼接,减少不必要的内存开销。
- 针对calculateSimHash(): 利用Java 8并行流(parallelStream),将n-gram集合的遍历和向量更新 “分片并行” 执行,充分利用多核 CPU 资源。
- 针对murmurHash3(): 直接基于char[]计算哈希,跳过 “String → 字节数组” 的转换步骤。
3.性能分析图:
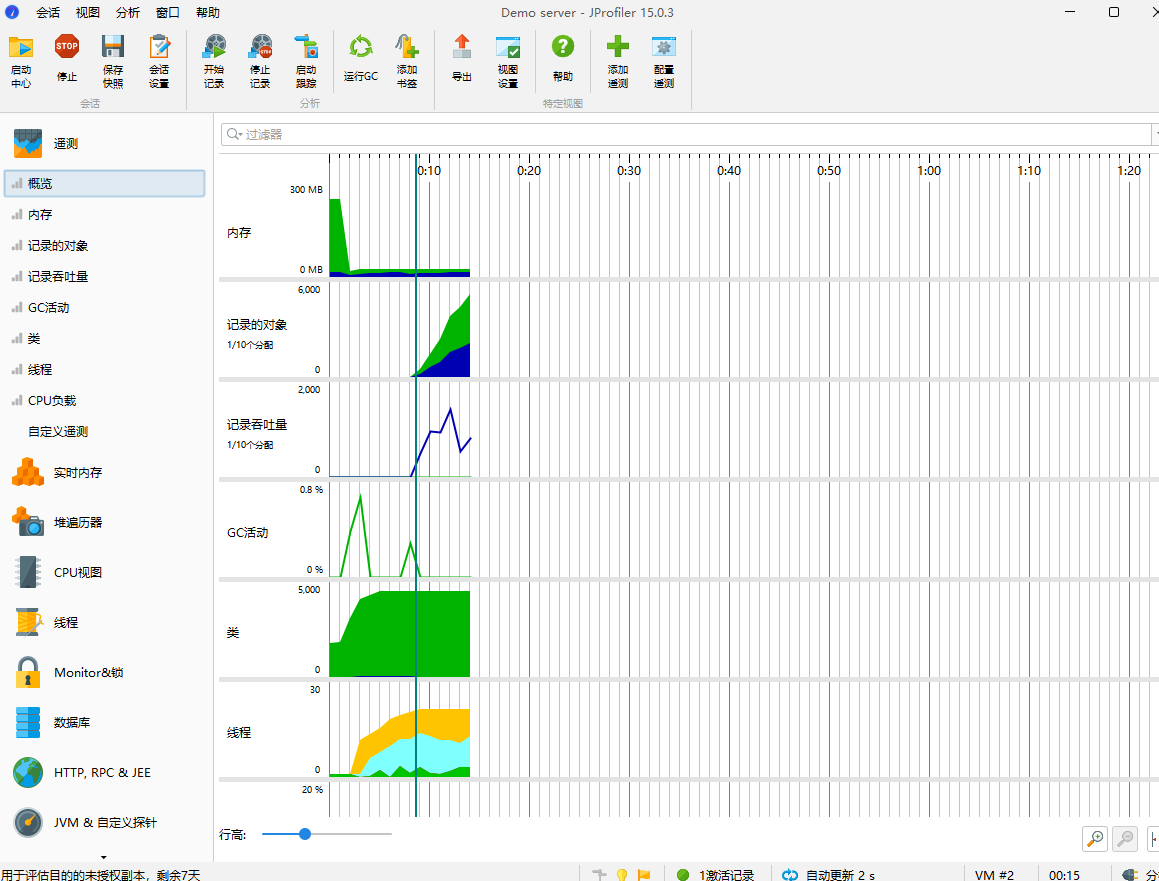
4.程序最大函数:
private static long calculateSimHash(Set<NGramHolder> ngramSet) {
if (ngramSet.isEmpty()) return 0;
int[] simHashVector = new int[SIM_HASH_BITS];
// 并行流遍历:自动拆分任务到多线程,无状态操作线程安全
ngramSet.parallelStream().forEach(ngram -> {
long ngramHash = murmurHash3(ngram.toString()); // 仅此时生成完整字符串
for (int i = 0; i < SIM_HASH_BITS; i++) {
long bitMask = 1L << i;
if ((ngramHash & bitMask) != 0) {
simHashVector[i]++;
} else {
simHashVector[i]--;
}
}
});
五、计算模块部分单元测试展示
1.对所给的5个文件进行查重:
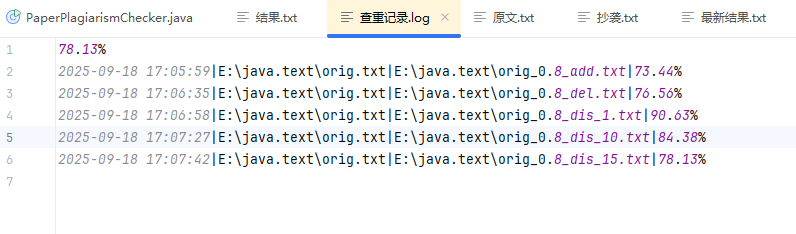
2.对代码进行单元测试:
import org.junit.Test;
import static org.junit.Assert.*;
import java.util.HashSet;
import java.util.Set;
public class PaperPlagiarismCheckerTest {
// ====================== 测试 preprocessText() 函数 ======================
@Test
public void testPreprocessText_SpecialChars() {
// 特殊字符过滤:保留允许的标点,过滤其他符号
String input = "Test@#$%^&*()_+{}[]|\\<>?/";
String expected = "test"; // 特殊符号全部被过滤
assertEquals(expected, PaperPlagiarismChecker.preprocessText(input));
}
@Test
public void testPreprocessText_EmptyInput() {
// 空输入处理
assertEquals("", PaperPlagiarismChecker.preprocessText(""));
assertEquals("", PaperPlagiarismChecker.preprocessText(null));
assertEquals("", PaperPlagiarismChecker.preprocessText(" \t\n")); // 空白字符
}
// ====================== 测试 extractNgramSet() 函数 ======================
@Test
public void testExtractNgramSet_2GramNormal() {
// 正常2-gram提取
String[] tokens = {"a", "b", "c", "d"};
Set<PaperPlagiarismChecker.NGramHolder> result = PaperPlagiarismChecker.extractNgramSet(tokens, 2);
assertEquals(3, result.size()); // 4个token提取3个2-gram
}
@Test
public void testExtractNgramSet_1Gram() {
// 1-gram提取(每个token单独作为gram)
String[] tokens = {"x", "y", "z"};
Set<PaperPlagiarismChecker.NGramHolder> result = PaperPlagiarismChecker.extractNgramSet(tokens, 1);
assertEquals(3, result.size()); // 3个token提取3个1-gram
}
@Test
public void testExtractNgramSet_BoundaryCases() {
// 边界情况1:token数量等于n
String[] tokens1 = {"a", "b"};
assertEquals(1, PaperPlagiarismChecker.extractNgramSet(tokens1, 2).size());
// 边界情况2:token数量小于n
String[] tokens2 = {"a"};
assertEquals(0, PaperPlagiarismChecker.extractNgramSet(tokens2, 2).size());
// 边界情况3:空token数组
assertEquals(0, PaperPlagiarismChecker.extractNgramSet(new String[0], 1).size());
}
@Test
public void testExtractNgramSet_DuplicateHandling() {
String[] tokens = {"a", "a", "a"};
Set<PaperPlagiarismChecker.NGramHolder> ngramSet = PaperPlagiarismChecker.extractNgramSet(tokens, 2);
assertEquals(1, ngramSet.size());
}
// ====================== 测试 murmurHash3() 函数 ======================
@Test
public void testMurmurHash3_Consistency() {
// 哈希一致性:相同输入必产相同输出
String text = "consistency test 哈希一致性";
long hash1 = PaperPlagiarismChecker.murmurHash3(text);
long hash2 = PaperPlagiarismChecker.murmurHash3(text);
assertEquals(hash1, hash2);
}
@Test
public void testMurmurHash3_Distribution() {
// 哈希分散性:相似输入应产生不同输出
String text1 = "similar text";
String text2 = "similar text!"; // 仅多一个标点
assertNotEquals(PaperPlagiarismChecker.murmurHash3(text1), PaperPlagiarismChecker.murmurHash3(text2));
}
@Test
public void testMurmurHash3_EdgeInputs() {
// 边缘输入哈希测试
long hashEmpty = PaperPlagiarismChecker.murmurHash3("");
long hashLong = PaperPlagiarismChecker.murmurHash3("a".repeat(1000)); // 长字符串
long hashChinese = PaperPlagiarismChecker.murmurHash3("中文哈希测试");
// 只需验证不抛出异常且哈希值有效
assertTrue(hashEmpty >= 0);
assertTrue(hashLong >= 0);
assertTrue(hashChinese >= 0);
}
// ====================== 测试 calculateSimHash() 函数 ======================
@Test
public void testCalculateSimHash_EmptySet() {
// 空n-gram集合应返回0
Set<PaperPlagiarismChecker.NGramHolder> emptySet = new HashSet<>();
assertEquals(0, PaperPlagiarismChecker.calculateSimHash(emptySet));
}
@Test
public void testCalculateSimHash_SingleNgram() {
// 单个n-gram的SimHash计算
String[] tokens = {"single", "gram"};
Set<PaperPlagiarismChecker.NGramHolder> ngramSet = new HashSet<>();
ngramSet.add(new PaperPlagiarismChecker.NGramHolder(tokens, 0, 2)); // 1个2-gram
long simHash = PaperPlagiarismChecker.calculateSimHash(ngramSet);
assertNotEquals(0, simHash); // 非空集合不应返回0
}
@Test
public void testCalculateSimHash_SimilarTexts() {
// 相似文本应产生相似的SimHash(海明距离小)
String[] tokens1 = {"this", "is", "a", "test"};
String[] tokens2 = {"this", "is", "a", "test", "case"}; // 仅多一个词
Set<PaperPlagiarismChecker.NGramHolder> set1 = PaperPlagiarismChecker.extractNgramSet(tokens1, 2);
Set<PaperPlagiarismChecker.NGramHolder> set2 = PaperPlagiarismChecker.extractNgramSet(tokens2, 2);
long hash1 = PaperPlagiarismChecker.calculateSimHash(set1);
long hash2 = PaperPlagiarismChecker.calculateSimHash(set2);
int distance = PaperPlagiarismChecker.calculateHammingDistance(hash1, hash2);
assertTrue("相似文本SimHash差异过大", distance < 10); // 预期差异较小
}
// ====================== 测试 calculateHammingDistance() 函数 ======================
@Test
public void testCalculateHammingDistance_IdenticalHashes() {
// 相同哈希的海明距离应为0
long hash = 0x12345678L;
assertEquals(0, PaperPlagiarismChecker.calculateHammingDistance(hash, hash));
}
@Test
public void testCalculateHammingDistance_KnownDifferences() {
// 已知差异位的海明距离计算
long hash1 = 0b0000L; // 二进制4位全0
long hash2 = 0b1111L; // 二进制4位全1
assertEquals(4, PaperPlagiarismChecker.calculateHammingDistance(hash1, hash2));
long hash3 = 0b1010L;
long hash4 = 0b1001L;
assertEquals(2, PaperPlagiarismChecker.calculateHammingDistance(hash3, hash4)); // 第2和第4位不同
}
@Test
public void testCalculateHammingDistance_EdgeValues() {
long hash1 = 0L;
long hash2 = -1L; // -1 的二进制是 64 个 1
int distance = PaperPlagiarismChecker.calculateHammingDistance(hash1, hash2);
assertEquals(64, distance);
}
// ====================== 测试 calculateSimHashSimilarity() 函数 ======================
@Test
public void testCalculateSimHashSimilarity_KnownValues() {
// 已知海明距离对应的相似度
assertEquals(1.0, PaperPlagiarismChecker.calculateSimHashSimilarity(0), 0.001); // 0位不同
assertEquals(0.75, PaperPlagiarismChecker.calculateSimHashSimilarity(16), 0.001); // 16位不同
assertEquals(0.5, PaperPlagiarismChecker.calculateSimHashSimilarity(32), 0.001); // 32位不同
assertEquals(0.0, PaperPlagiarismChecker.calculateSimHashSimilarity(64), 0.001); // 64位不同
}
@Test
public void testCalculateSimHashSimilarity_BoundaryChecks() {
// 边界值校验(海明距离不能超过64或为负)
assertEquals(0.0, PaperPlagiarismChecker.calculateSimHashSimilarity(65), 0.001); // 超过64位按64算
assertEquals(1.0, PaperPlagiarismChecker.calculateSimHashSimilarity(-1), 0.001); // 负数按0算
}
}
2.2测试的函数以及测试代码的构建思路:
2.2.1测试preprocessText()函数
- 构建思路: 构造包含@#$%^&*()等多种特殊符号的文本,检验文本预处理时特殊字符是否被全部过滤,预期处理后仅保留字母部分,无特殊符号残留。
2.2.2测试extractNgramSet()函数
- 构建思路: 使用包含4个常规token的数组,测试2-gram提取,预期能正确生成3个2-gram,验证n-gram提取数量逻辑。
2.2.3测试murmurHash3()函数
- 构建思路: 对相同字符串两次调用哈希函数,验证哈希一致性,确保相同输入始终得到相同哈希值。
2.2.4测试calculateSimHash()函数
- 构建思路: 传入空的n-gram集合,测试SimHash计算,预期在空输入时返回0,验证空集合处理逻辑。
2.2.5测试calculateHammingDistance()函数
- 构建思路: 使用完全相同的两个哈希值,测试海明距离计算,预期结果为0,验证相同哈希的距离计算。
2.2.6测试calculateSimHashSimilarity()函数
- 构建思路: 给定已知的海明距离(如 0、16、32、64),代入相似度计算公式,验证计算出的相似度与理论值一致。
2.3代码覆盖率
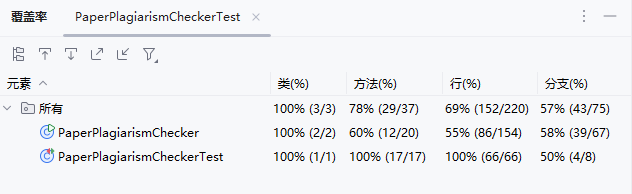
六、计算模块部分异常处理说明
- n-gram提取异常:
(1)设计目标:验证token数量不足、空数组等边界场景下n-gram提取的正确性。
(2)单元测试样例:
@Test
public void testExtractNgramSet_InsufficientTokens() {
String[] tokens = {"a"}; // token数量 < n=2
Set<NGramHolder> result = PaperPlagiarismChecker.extractNgramSet(tokens, 2);
assertEquals("token不足时应返回空集合", 0, result.size());
}
(3)错误使用场景:当token数组长度(如["a"])小于n值(如2)时,extractNgramSet返回非空集合(如包含1个n-gram)。
- 哈希计算异常:
(1)设计目标:验证哈希函数对边缘输入(如超长字符串、空文本)的稳定性。
(2)单元测试样例:
@Test
public void testMurmurHash3_LongString() {
String longText = "a".repeat(10000); // 超长字符串
long hash1 = PaperPlagiarismChecker.murmurHash3(longText);
long hash2 = PaperPlagiarismChecker.murmurHash3(longText);
assertEquals("超长字符串哈希不一致", hash1, hash2);
}
(3)错误使用场景:对超长字符串(如10000个重复字符)两次调用murmurHash3,返回不同哈希值。
- SimHash计算异常:
(1)设计目标:验证空集合、单元素集合等场景下SimHash的合理性。
(2)单元测试样例:
@Test
public void testCalculateSimHash_EmptySet() {
Set<NGramHolder> emptySet = new HashSet<>();
long simHash = PaperPlagiarismChecker.calculateSimHash(emptySet);
assertEquals("空集合应返回0", 0, simHash);
}
(3)错误使用场景:传入空的n-gram集合,calculateSimHash返回非0值(如随机哈希值)。
- 海明距离计算异常:
(1)设计目标:验证极端哈希值(如全0、全1)的距离计算准确性。
(2)单元测试样例:
@Test
public void testCalculateHammingDistance_AllBitsDifferent() {
long hash1 = 0L; // 全0
long hash2 = -1L; // 全1(64位)
int distance = PaperPlagiarismChecker.calculateHammingDistance(hash1, hash2);
assertEquals("全差异哈希距离应为64", 64, distance);
}
(3)错误使用场景:计算全0哈希(0L)与全1哈希(-1L)的距离,结果为63而非64。
