Hadoop综合大作业
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
f = open('note.txt', 'r') song = f.read() f.close() def writeFilenote(contnet): f = open('newnote.txt', 'a', encoding='utf-8') f.write(contnet) f.close() symbol = ''',.?!’;?!:"“”-%$''' exclude = ''' a an the in on to at and of is was are were i he she you your they us their our it or for be too do no that s so as but it's ''' for i in symbol: song = song.replace(i, ' ') writeFilenote(song) print(song)
先用python将文本当中的不合法词汇剔除,然后另存为newnote.txt
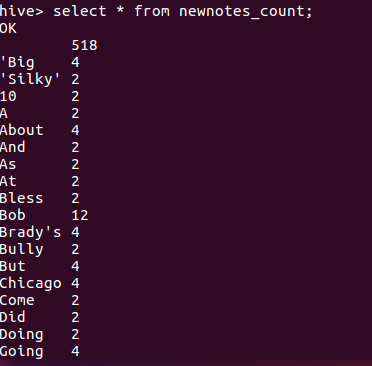
然后hive一系列猛操作,出现结果如下图。(过程不贴了,毕竟跟上次差不多)
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
def getNewsDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') NewsDict={} NewsDict['source']=soupd.select('.comeFrom')[0].select('a')[0].text NewsDict['title']=soupd.select('.headline')[0].text NewsDict['time']=soupd.select('#pubtime_baidu')[0].text #NewsDict['content'] = soupd.select('.artical-main-content')[0].text return NewsDict def Get_page(url): res = requests.get(url) res.encoding = 'utf-8' pagelist=[] soup = BeautifulSoup(res.text, 'html.parser') # print(soup.select('.tag-list-box')[0].select('.list')) for new in soup.select('.tag-list-box')[0].select('.list'): #print(new.select('.list-content')[0] .select('.name')[0].select('.n1')[0].select('a')[0]['href']) url =new.select('.list-content')[0] .select('.name')[0].select('.n1')[0].select('a')[0]['href'] pagedict=getNewsDetail(url) pagelist.append(pagedict) return pagelist #break # break # print(url) url = 'https://voice.hupu.com/nba/tag/3023-1.html' resd = requests.get(url) resd.encoding = 'utf-8' soup1 = BeautifulSoup(resd.text, 'html.parser') total=[] # listCount = int(soup.select('.a1')[0].text.rstrip('条'))//10+1 pagelist=Get_page(url) total.extend(pagelist) for i in range(2, 25): total.extend(Get_page('https://voice.hupu.com/nba/tag/3023-{}.html'.format(i))) pan = pandas.DataFrame(total) pan.to_csv('result3.csv')
---恢复内容结束---
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)词频统计。
f = open('note.txt', 'r') song = f.read() f.close() def writeFilenote(contnet): f = open('newnote.txt', 'a', encoding='utf-8') f.write(contnet) f.close() symbol = ''',.?!’;?!:"“”-%$''' exclude = ''' a an the in on to at and of is was are were i he she you your they us their our it or for be too do no that s so as but it's ''' for i in symbol: song = song.replace(i, ' ') writeFilenote(song) print(song)
先用python将文本当中的不合法词汇剔除,然后另存为newnote.txt
然后hive一系列猛操作,出现结果如下图。(过程不贴了,毕竟跟上次差不多)
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
def getNewsDetail(newsUrl): resd = requests.get(newsUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') NewsDict={} NewsDict['source']=soupd.select('.comeFrom')[0].select('a')[0].text NewsDict['title']=soupd.select('.headline')[0].text NewsDict['time']=soupd.select('#pubtime_baidu')[0].text #NewsDict['content'] = soupd.select('.artical-main-content')[0].text return NewsDict def Get_page(url): res = requests.get(url) res.encoding = 'utf-8' pagelist=[] soup = BeautifulSoup(res.text, 'html.parser') # print(soup.select('.tag-list-box')[0].select('.list')) for new in soup.select('.tag-list-box')[0].select('.list'): #print(new.select('.list-content')[0] .select('.name')[0].select('.n1')[0].select('a')[0]['href']) url =new.select('.list-content')[0] .select('.name')[0].select('.n1')[0].select('a')[0]['href'] pagedict=getNewsDetail(url) pagelist.append(pagedict) return pagelist #break # break # print(url) url = 'https://voice.hupu.com/nba/tag/3023-1.html' resd = requests.get(url) resd.encoding = 'utf-8' soup1 = BeautifulSoup(resd.text, 'html.parser') total=[] # listCount = int(soup.select('.a1')[0].text.rstrip('条'))//10+1 pagelist=Get_page(url) total.extend(pagelist) for i in range(2, 25): total.extend(Get_page('https://voice.hupu.com/nba/tag/3023-{}.html'.format(i))) pan = pandas.DataFrame(total) pan.to_csv('result3.csv')
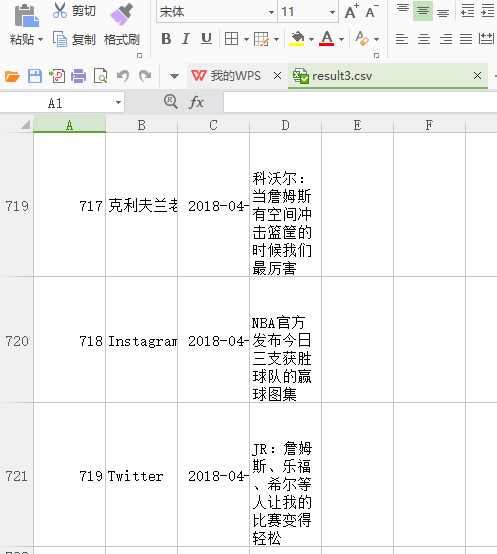
因为title太长的原因影响到后面的排版,所以我就删掉了,然后就是这个表导出来后id第一列显示是空的,与我后面的操作相违背,所以我直接删掉。
查了以下百度,好像是用了index=false 夹在to_csv(csv,index=false)这样。出来的表就是我想要的
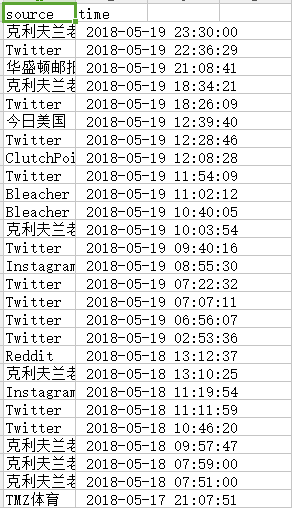
然后就是基本操作,插入excel,然后删掉第一行这些拉。写下我的,水平不行跟老师有点像。 这个sh文件如以下

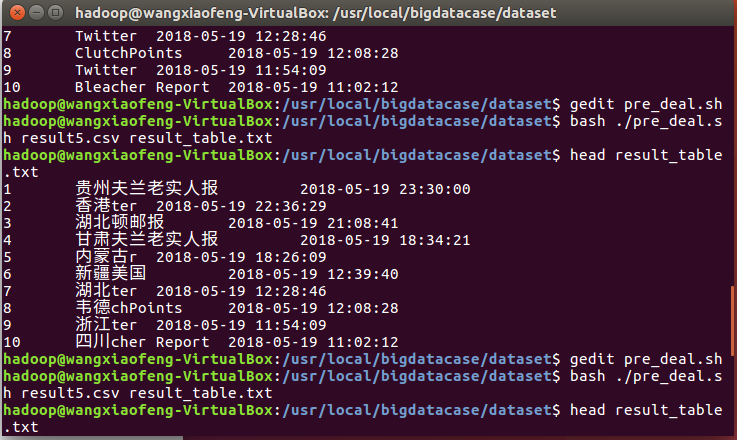
刚开始没注意到时间要改,随意就变成了格式不正确,修改之后数据才正确
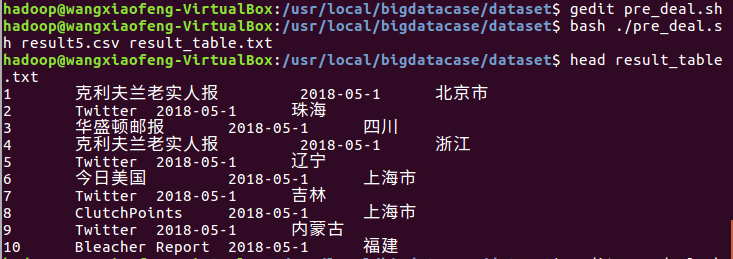
小小一步废了我好长时间。
然后发现这个时间,不对于是我就去改了下pre_deal.sh的范围,结果如图。
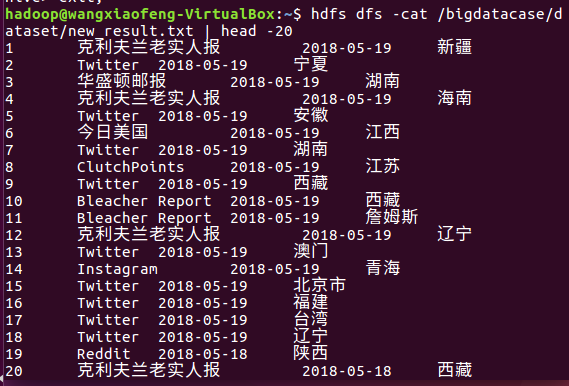
然后继续hive操作日常猛如虎系列:
然后看到这玩意,我呆滞了,我的时间出来md是null
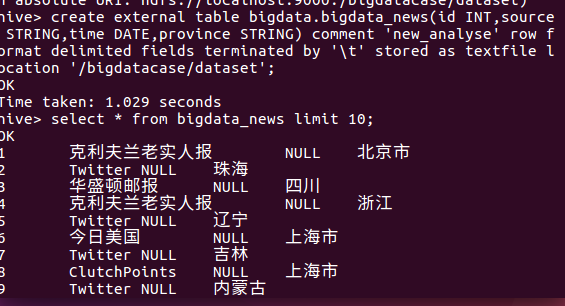
积极的我时间定义改为string,然后正常输出


然后进行数据分析,本来想把5月10日至5月14日的新闻发布次数提取出来的,竟然结果为0,好的这个操作看来只能拿针对date,而不能用来String,碍于重新开始用爬虫爬其他网站,于是就改成计算表里面一共有多少条数据把。
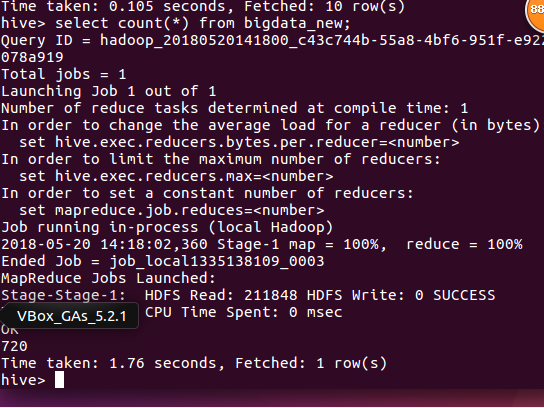
总结:虽然结果很简单,但是过程很曲折,想要后面不踩坑,前面要踏踏实实一步一步走,不然像我上面这些步骤做了好几次,气得我要死,下次选择爬网站的时候要看看自己扒下来的数据类型是什么,这东西影响到最后的数据分析,我反正我是在这载了,下次我会好好选择爬网站的对象了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号