为什么大语言模型推理要分成 Prefill 和 Decode?
一句话解释:Prefill 和 Decode 的分工
大语言模型生成文本的过程本质上是给定上下文,逐词预测下一个词。
但在实现上,这个过程被明确地分成两个阶段:
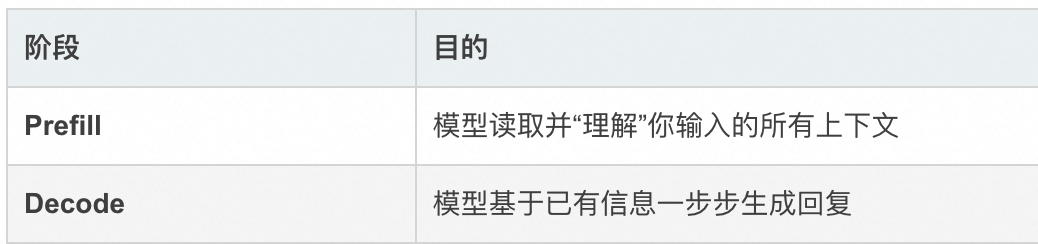
为什么不能用一个阶段做完?
因为输入和输出的计算特性完全不同:
- 输入 prompt 是完整的、一次性提供的,适合并行计算。
- 输出 token 是未知的,只能一个一个推理,必须串行。
这种“数据形态差异”导致我们不得不把它们拆成两个阶段,并用不同方式处理。
原文链接:https://blog.csdn.net/keeppractice/article/details/147012874
大模型系列:深度解析 Prefill-Decode 分离式部署架构 https://zhuanlan.zhihu.com/p/1918334902492963669
为什么LLM推理要分成Prefill和Decode两个阶段? https://zhuanlan.zhihu.com/p/1925514980343677032


 浙公网安备 33010602011771号
浙公网安备 33010602011771号