
Python学习系列之列表增删改操作(十一)
一、为什么需要列表
- 变量可以存储一个元素,而列表是一个"大容器"可以存储N多个元素,程序可以方便地对这些数据进行整体操作
- 列表相当于其它语言中的数组
二、列表的创建
1.列表需要使用中括号[],元素之间使用英文的逗号进行分隔
比如:
a=10 #变量存储的是一个对象的引用 list1=['hello','world',98] #列表存储的是多个对象的引用,将列表创建好后赋值给对象list1
2.列表的创建方式:
- 使用中括号
- 调用内置函数list()
2.1 使用中括号创建:
lst=['hello','world',98]
2.2 使用内置函数list()创建:
lst2=list(['hello','world',98])
三、列表的特点
列表的特点:
- 列表元素按顺序有序排序
- 索引映射唯一一个数据
- 列表可以存储重复数据
- 任意数据类型混存
- 根据需要动态分配和回收内存
四、获取列表指定元素的索引
1.获取列表中指定元素的索引
- 使用index()函数
- 如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
- 如果查询的元素在列表中不存在,则会跑出ValueError
- 还可以在指定的start和stop之间进行查找
比如:
lst=['hello','world',98,'hello']
print(lst.index('hello')) #当list中有两个相同元素时,会取第一个元素的索引
执行结果如下:

解析:如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
2.获取列表中不存在的元素会报ValueError
lst=['hello','world',98,'hello']
print(lst.index('python'))
执行结果如下:

解析:python在列表lst中不存在,所以在列表中查找'python'的索引会报错
3.在指定的start和stop之间进行查找
比如:
lst=['hello','world',98,'hello']
print(lst.index('hello',1,4))
执行结果如下:

如果步长的值中不存在改值时,则会报错,比如:
lst=['hello','world',98,'hello']
print(lst.index('hello',1,3))
执行结果如下:

解析:1-3的步长中只包含1和2的位置,对应的值是'world'和98
五、获取列表中指定的元素
获取列表中的单个元素:
- 正向索引从0到N-1,举例:lst[0]
- 逆向索引从-N到-1,举例:lst[-N]
- 指定索引不存在,跑出IndexError
比如:
lst=['hello','world',98,'hello'] print(lst[2]) print(lst[-3])
执行结果如下:
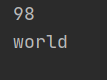
解析:正向索引是从0开始的,[2]表示获取第三个,第三个的值是98,逆向索引是从-N到-1,即从最后一个'hello'的索引是-1算起,[-3]索引的值为'world'
lst=['hello','world',98,'hello'] print(lst[5])
执行结果:

解析:列表lst对象中共4个元素,正向索引包含0,1,2,3,索引5不存在,所以当输出索引5的值时会报IndexError
六、列表元素的查询操作
获取列表中的多个元素
语法格式:
列表名[start:stop:step]
切片操作:
- 切片的结果,原列表片段的拷贝
- 切片的范围,[start,stop]
step默认为1,简写为[start,stop]
step为正数,[:stop:step] ,切片的第一个元素默认是列表的第一个元素,从start开始往后计算切片
step为正数,[start::step],切片的最后一个元素默认是列表的最后一个元素,从start开始往后计算切片
step为负数,[:stop:step],切片的第一个元素默认是列表的最后一个元素,从start开始往前计算切片
step为负数,[start::step],切片的最后一个元素默认是列表的第一个元素,从start开始往前计算切片
举例:
#[start:stop:step] lst1=[10,20,30,40,50,60,70,80,90] print(lst1[0:6]) #省去步长,步长默认为1,最后一位值的index为5,所以打印出:10,20,30,40,50,60 print(lst1[0:6:2]) #打印从index为0开始,最后一个是index为5,步长为2的数据,打印结果为:10,30,50 print(lst1[:6:1]) #不输入start,打印起始index为0,最后一个是index为5,步长为1的数据,打印结果是:10,20,30,40,50,60 print(lst1[0::2]) #不输入stop,打印起始index为0,步长为2的列表值,打印结果为:10, 30, 50, 70, 90
执行结果如下:

解析:见print语句后的注释
七、列表元素的判断及遍历
1.列表元素的判断
判定指定元素在列表中是否存在
元素 in 列表名
元素 not in 列表名
举例:
lst2=[10,20,'hello','python'] print(10 in lst2) print(10 not in lst2)
执行结果如下:
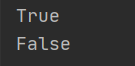
解析:10在列表中,所以第一个Print的结果为True,第二个print的结果是False
2.列表元素的遍历
语法结构:
for 迭代变量 in 列表名:
执行体
举例:
lst2=[10,20,'hello','python']
for item in lst2:
print(item)
执行结果如下:
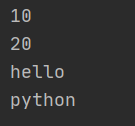
解析:for循环将lst2中的每个值赋值给item,然后将item打印出来,得到的是lst2列表中的所有值
八、列表元素的增删改查
1.列表元素的增加操作
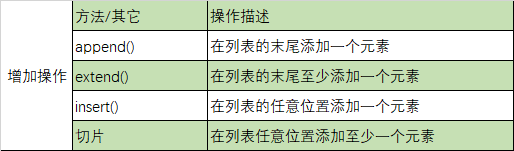
1.1 append()举例:
#列表增加操作,增加操作只是在列表的末尾添加一个元素,内存id不会改变
lst=['hello','world',98]
print('增加前:',lst,id(lst))
lst.append(100)
print('增加后:',lst,id(lst))
执行结果如下:

解析:append操作不会改变列表对象的内存id,只会在列表的最后一个位置新增一个内存位置来存储值。
1.2 extend()举例
#extend lst=[10,20,30] lst1=['hello','world'] lst.append(lst1) print(lst) lst.extend(lst1) print(lst)
执行结果如下:

解析:使用append方法,是将整个lst1列表中的值作为一个元素存储到lst列表中,使用extend方法,是将lst1中的值取出来一个一个存到lst列表中
1.3 insert()举例:
#insert(),在列表任意位置添加元素 lst=[10,20,30] lst.insert(1,90) #在索引为1的位置上添加90这个元素 print(lst)
执行结果如下:
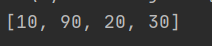
解析:index为1的位置插入90,就是在索引为0的位置之后插入一个值为90的元素,后面值的index值往后移
1.4 切片举例
#切片,在任意位置上添加N个元素 lst=[10,20,30] print(lst) lst3=['hello','world'] lst[1:]=lst3 print(lst)
执行结果如下:
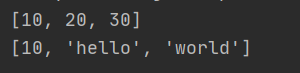
解析:lst[1:]表示将lst列表中index为1及其以后的所有数据都用lst3的值来替换,切片后,lst中20,30的值都被lst3中的'hello','world'替代,所以最终lst列表中存的值是[10,'hello','world']
2.列表元素的删除操作
2.1 remove()举例:
#删除列表元素
#使用remove()
lst=[10,20,30,40,50]
print('删除前:',lst)
lst.remove(20)
print('删除后:',lst)
执行结果:

解析:remove()直接删除列表里的元素,删除成功后列表值会减少已删除的值
2.2 pop()删除举例:
#pop()根据索引移除元素
lst=[10,20,30,40,50]
print('删除前:',lst)
lst.pop(2)
print('删除后:',lst)
执行结果如下:

解析:lst.pop(2)表示删除索引为2的值即删除30,所以删除后的列表中没有30这个元素
如果pop()不指定索引,将删除列表中的最后一个元素
#如果pop()不指定索引,将删除列表中的最后一个元素
lst=[10,20,30,40,50]
print('删除前:',lst)
lst.pop()
print('删除后:',lst)
执行结果如下:

解析:如果pop()不指定索引,将删除列表中的最后一个元素,lst列表中最后一个元素是50,则执行pop()后lst列表中没有50这个元素
2.3 切片
切片删除表示至少删除一个元素,将产生一个新的列表对象
举例:
#切片,删除至少一个元素,将产生一个新的列表对象
lst=[10,20,30,40,50]
new_list=lst[1:3]
print('原列表:',lst,id(lst))
print('新列表:',new_list,id(new_list))
执行结果如下:

解析:new_list=lst[1:3]表示将lst列表中索引为1和2的值单独拿出来,放到new_list列表中,lst列表中索引为1和2的值分别是20和30,故new_list的值是20,30,从后面输出的对象id可以看出,lst和new_list是两个不同的对象
如果不想产生新列表对象,则可以使用[]空列表来替代要删除的部分,如下:
lst=[10,20,30,40,50,60,70,80,90] print(id(lst)) lst[1:5]=[] print(lst,id(lst))
执行结果如下:

解析:索引为1-4的值是20,30,40,50,将此部分的值替换为空,lst列表只剩下10,60,70,80,90,列表指向的内存id没有变化,还是原列表地址,之不过列表长度缩短了
2.4 使用clear()方法删除
举例:
#clear()方法删除整个列表的值 lst=[10,20,30,40,50,60,70,80,90] lst.clear() print(lst)
执行结果如下:

解析:使用clear()方法仅仅只是删除列表中的值,是列表成为一个空列表,此时并不会释放内存空间
2.5 使用del删除整个列表
举例:
#del删除列表 lst=[10,20,30,40,50,60,70,80,90] del lst print(lst)
执行结果如下:

解析:当使用del将列表对象删除后,内存空间释放,所以会报NameError,提示列表未定义即内存中没有这个列表,表示删除成功
3.列表元素的修改
列表元素的修改操作:
- 为指定索引的元素赋予一个新值
- 为指定的切片赋予一个新值
3.1 为指定索引的元素赋予一个新值
举例:
#一次修改一个值,即通过索引修改索引的值 lst=[10,20,30,40] lst[2]=100 print(lst)
执行结果如下:

解析:lst[2]=100表示将lst列表中索引为2对应的值替换成100,索引为2对应的值是30,所以最终结果是10,20,100,40
3.2 为指定的切片赋予一个新值
#为指定的切片赋一个新值 lst=[10,20,30,40] lst[1:3]=[222,333] print(lst)
执行结果如下:
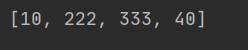
解析:表达式:lst[1:3]=[222,333]表示将lst列表中索引为1和2对应的值替换为222,333,所以最终结果值是10,222,333,40
以上,就是Pyhton中列表元素的增删改查

 浙公网安备 33010602011771号
浙公网安备 33010602011771号