房价爬取+数据可视化
(一)、选题的背景
在当下社会住房成为人们生活的一个必需品,在生活中月来越重要本课题从该地区的人口,出生率,工人工资分析房价与他们的关系
(二)、主题式网络爬虫设计方案
1.主题式网络爬虫名称
全国房价,人口爬取
1 url="https://www.gotohui.com/top/"
2.主题式网络爬虫爬取的内容与数据特征分析
爬取该网站的房价以及对应城市的人口,出生率,工人工资做分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
爬取当前网站的房价与城市名称并找到该标签下的链接进行跳转爬取下一个页面的有关数据,再数据清洗,数据可视化。在对页面标签的再爬取采取的循化爬取会因为数据的不对称报错。具体的思路和分析通过下列代码与图片展示。
(三)、主题页面的结构特征分析
1.主题页面的结构与特征分析

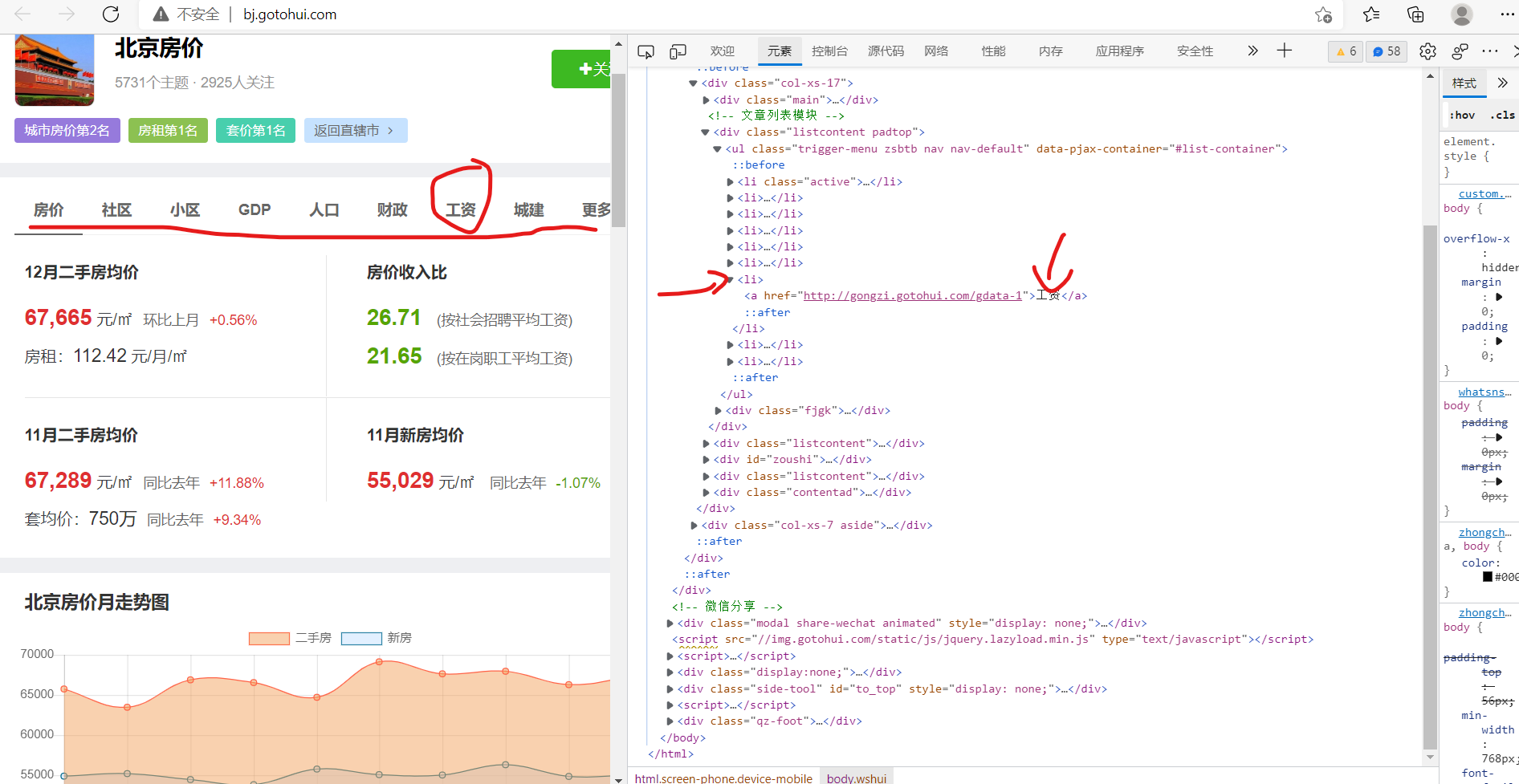

2.Htmls 页面解析
第一张图可以发现所需要的数据存在于tobody标签中的tr中的td下,tr中的第一个td里有该城市的具体数据,通过点击进入到第二张图,可以发现我们需要的数据链接在ul标签的li下,找到该标签点击进入第3张图,可以发现我们所需要的数据在tobody标签的tr的td中,然而我们需要的数据还有人口从第2张图重复即可该地方不再叙述下面用代码展示。
3.节点(标签)查找方法与遍历方法
通过三循环第一个遍历找到的有效tr标签,第二个遍历tr中的td得到数据和链接,第三个对得到的链接访问遍历爬取的数据取出。
(必要时画出节点树结构)
(四)、网络爬虫程序设计(60 分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后
面提供输出结果的截图。
1.数据爬取与采集
1):所需要的库
源码:
1 from bs4 import BeautifulSoup 2 import requests 3 import pandas as pd 4 import csv 5 import matplotlib.pyplot as plt 6 from sklearn import metrics 7 import warnings 8 import seaborn as sns 9 import plotly 10 import plotly.express as px 11 import plotly.graph_objects as go 12 import plotly.io as pio 13 import numpy as np 14 warnings.filterwarnings("ignore")
截图展示:

第1部分数据爬取和展示
源码:
1 def getHTMLText(url): 2 try: 3 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/\ 4 537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"} 5 r=requests.get(url,headers=headers) 6 r.raise_for_status()#如果状态不是200,就会引发HTTPError异常 7 r.encoding = r.apparent_encoding 8 return r.text 9 except: 10 return "no" 11 def dataProcessing(html):#传入Html数据 12 soup=BeautifulSoup(html) 13 #通过对页面分析可以发现,每个城市房价数据存在于tbody下的td中我们只需要其中的三个数据 14 datas=[] 15 hrefs=[] 16 for i in soup.find_all("tr"): 17 data=i.find_all("td") #找到所有的td标签返回一个集合 18 if len(data)==6: #必须要执行的判断过滤数据 19 ranks=[] #创建一个集合用于存放每一个城市的数据 20 city=i.find("a").string#找到城市的名字 21 ranks.append(data[0].string) #房价排名存在data集合的第一个 22 ranks.append(city) #添加城市名称 23 ranks.append(data[2].string)#房价信息存在于data的第3个 24 datas.append(ranks) #将这个城市的数据放入集合 25 #datas.append(ranks) 26 #datas.append(citys) 27 #datas.append(housePrices) 28 return datas 29 def hrefs(html): 30 hrefs=[] 31 soup=BeautifulSoup(html) 32 for i in soup.find_all("tr"): 33 data=i.find_all("td") #找到所有的td标签返回一个集合 34 if len(data)==6: 35 hrefs.append(i.find("a").get("href"))#创建一个集合用于存放其他数据链接 36 return hrefs 37 url="https://www.gotohui.com/top/" 38 html_1=getHTMLText(url) 39 da=dataProcessing(html_1) 40 hrefs=hrefs(html_1) 41 df=pd.DataFrame(da) 42 df
截图展示:

第二部分由于数据量大爬取网站多需要大概4分钟跑完(这里尽量截取大部分代码)
源码:
1 a=1 2 dig_data=[] 3 for g in hrefs: 4 html_2=getHTMLText(g) 5 soup_2=BeautifulSoup(html_2) 6 f=[] 7 a_data=[] 8 hreds_data=soup_2.find_all("li")[46:51] 9 for b in hreds_data: 10 f.append(b.find("a").get("href")) 11 #f集合里的5条链接分别是GDP,人口,财政,工资,城建 12 #------------因为这些数据是在同一段数据下没法单独查找,但我只需要其中的2个链接---------------------------- 13 #每个数据的值都给出页面对应的属性 14 #因为这是对每个城市的后续链接进行访问,后续链接的HTML格式一样用循环可以去除大量的代码 15 #-------------------------------------------#这是对人口数据的爬取这些数据最终都被添加于集合中 16 if len(f)==5: 17 html_3=getHTMLText(f[1]) 18 soup_3=BeautifulSoup(html_3) 19 people_data=[] 20 #这里捕捉异常因为在代码运行中发现有些页面并不存在这会导致索引错误 21 try: 22 for c in soup_3.find_all("tr")[7]: 23 people_data.append(c.string) 24 #年份,户籍人口,常住人口,城镇化率(%),增长率(‰),出生率‰ 25 #['\n','2014','\n','332.21','\n','1077.89','\n','100.00','\n','17.48','\n','19.89','\n'] 26 except: 27 people_data=["","","","","","","","","","","","",""] 28 finally: 29 if len(people_data)==13: 30 ok="ok" 31 else: 32 people_data=["","","","","","","","","","","","",""] 33 #-------------------------------------------#这是对工人每年平均工资的爬取这些数据最终都被添加于集合中 34 html_4=getHTMLText(f[3]) 35 soup_4=BeautifulSoup(html_4) 36 price_data=[] 37 #if soup_4.find_all("tr")==None: 38 #这里捕捉异常因为在代码运行中发现有些页面并不存在这会导致索引错误 39 try: 40 for d in soup_4.find_all("tr")[5]: 41 price_data.append(d.string) 42 except: 43 price_data=["","","","","","","","","","",""] 44 finally: 45 if len(price_data)==11: 46 ok="ok" 47 else: 48 price_data=["","","","","","","","","","",""] 49 #年份,职工平均工资(元/年),职工平均工资(元/月),职工人数(万人),职工工资总额(亿元) 50 #['\n','2015','\n','81034.00','\n','6752.83','\n','452.00','\n','3662.72','\n'] 51 a_data.append(people_data[3])#这是户籍人口 52 a_data.append(people_data[5])#这是常住人口 53 a_data.append(people_data[11])#这是出生率 54 a_data.append(price_data[3])#这是当地职员工资 55 dig_data.append(a_data) 56 #这里可以对收集的数据展示,不需要可以删除后面变量,这代码爬取数据实在是太慢, 57 #print("ok",dig_data) 58 #因为数据是跳转了多个网站数据在两个不同的集合这里进行处理 59 big_data=[] 60 for gh in range(len(da)): 61 data=[] 62 data.extend(da[gh]) 63 data.extend(dig_data[gh]) 64 big_data.append(data) 65 #这里将数据写入文件可以方便使用不需要多次爬取数据 66 big_data
截图展示:
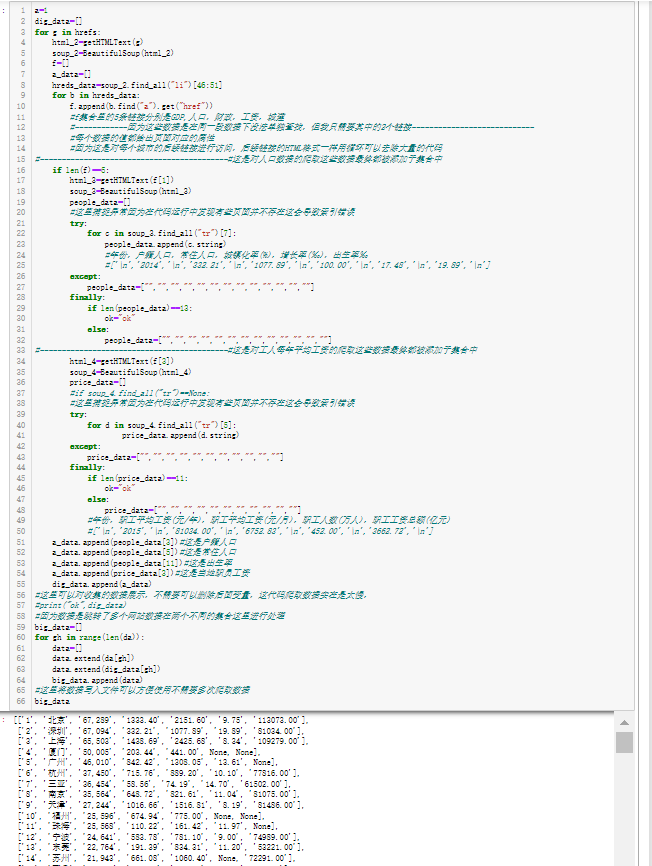
这里的数据并没有整理好游戏数字还是字符串处理在下面进行
源码:
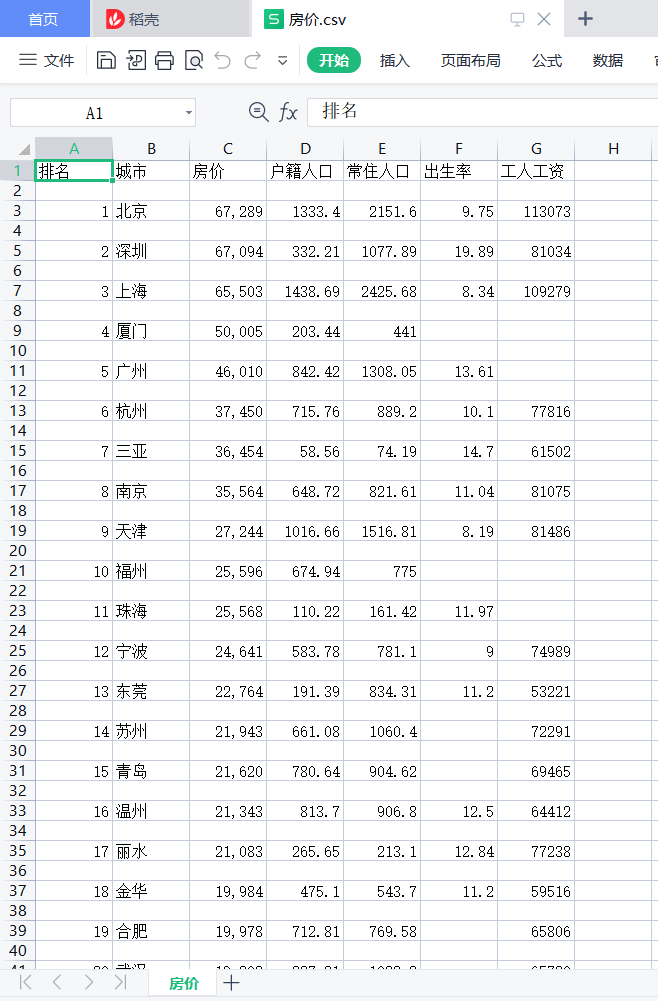
1 with open("F:\\新建文件夹 (2)\\房价.csv","w",encoding="utf-8") as fi: 2 writer=csv.writer(fi) 3 writer.writerow(["排名","城市","房价","户籍人口","常住人口","出生率","工人工资"])#给每列的数据列名 4 for a in big_data: 5 writer.writerow(a) 6 fi.close()#数据到此爬取完成
截图展示:

6.数据持久化
数据保存,
2.对数据进行清洗和处理
源码:
1 df=pd.read_csv("F:\\新建文件夹 (2)\\房价.csv") 2 df["户籍人口"]=df["户籍人口"].fillna(df["户籍人口"].mean()) 3 df["常住人口"]=df["常住人口"].fillna(df["常住人口"].mean()) 4 df["出生率"]=df["出生率"].fillna(df["出生率"].mean()) 5 df["工人工资"]=df["工人工资"].fillna(df["工人工资"].mean()) 6 #df.loc[0:,"房价"].split(",")[0] 7 for h in range(300): 8 f=[] 9 f.extend(df.loc[h,"房价"].split(",")) 10 df.loc[h,"房价"]=".".join(f) 11 df["房价"]=df["房价"].apply(float) 12 df
截图展示:
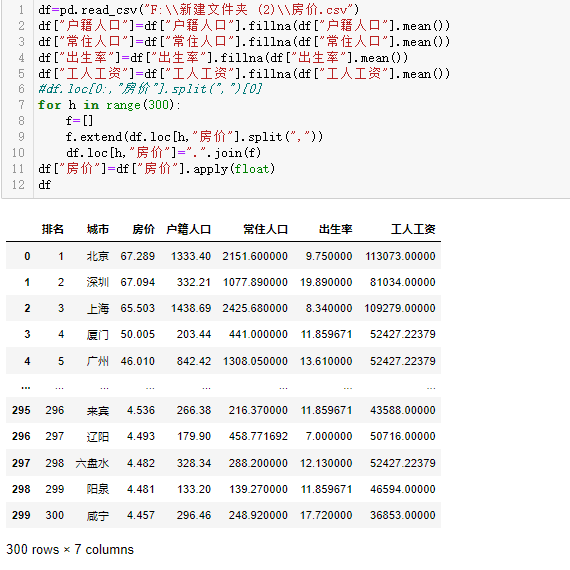
这里将保存的数据读取出来并对空值补中位数(这个地方补中位数可能并不是很好)
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
源码:
1 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 2 #房价 3 plt.subplot(2,2,1) 4 plt.boxplot(df["房价"], 5 patch_artist=True, 6 meanline=True, 7 showmeans=True,) 8 plt.title("房价") 9 #常住人口 10 plt.subplot(2,2,2) 11 plt.boxplot(df["常住人口"], 12 patch_artist=True, 13 meanline=True, 14 showmeans=True,) 15 plt.title("常住人口") 16 #出生率 17 plt.subplot(2,2,3) 18 plt.boxplot(df["出生率"], 19 patch_artist=True, 20 meanline=True, 21 showmeans=True,) 22 plt.title("出生率") 23 #工人工资 24 plt.subplot(2,2,4) 25 plt.boxplot(df["工人工资"], 26 patch_artist=True, 27 meanline=True, 28 showmeans=True,) 29 plt.title("工人工资") 30 plt.show()
截图展示:

通过盒图可以观察到4个数据的总体信息,
我国房价大部分在1万5,工人工资年薪大部分在5万。
源码:
1 #对房价和出生率进行分析并拟合观察房价的高低是否影响到房价 2 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 3 plt.plot(df["房价"], 4 df["出生率"], 5 label="房价-出生率") 6 sns.regplot(df["房价"], 7 df["出生率"], 8 label="预测曲线")#二次拟合 9 plt.xlabel("房价") 10 plt.ylabel("出生率") 11 plt.title('房价出生率分析') 12 plt.legend() 13 plt.grid() 14 plt.show()
1 #通过对工人工资分析与房价关系 2 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 3 plt.plot(df["工人工资"], 4 df["房价"], 5 label='工人工资-房价') 6 sns.regplot(df["工人工资"], 7 df["房价"], 8 label="拟合") 9 plt.xlabel("工人工资") 10 plt.ylabel("房价") 11 plt.title('房价出生率分析') 12 plt.legend() 13 plt.grid() 14 plt.show()
1 #通过对常住分析与房价关系 2 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 3 plt.plot(df["常住人口"], 4 df["房价"], 5 label='常住人口-房价') 6 sns.regplot(df["常住人口"], 7 df["房价"], 8 label='拟合') 9 plt.xlabel("常住人口") 10 plt.ylabel("房价") 11 plt.title('房价常住人口分析') 12 plt.legend() 13 plt.grid() 14 plt.show()
截图展示:


通过折线图拟合可以看出两数据之间的关系
源码:
1 #折线不能很好反应数据这里用散点拟合 2 plt.subplot(2,2,1) 3 plt.scatter(df["房价"], 4 df["常住人口"], 5 label="拟合", 6 color="b") 7 sns.regplot(df["房价"], 8 df["常住人口"], 9 label="拟合", 10 color="b") 11 plt.subplot(2,2,2) 12 plt.scatter(df["房价"], 13 df["出生率"]) 14 sns.regplot(df["房价"], 15 df["出生率"], 16 label="拟合", 17 color="r") 18 plt.subplot(2,2,3) 19 plt.scatter(df["工人工资"], 20 df["房价"]) 21 sns.regplot(df["工人工资"], 22 df["房价"], 23 label="拟合", 24 color="k") 25 plt.subplot(2,2,4) 26 plt.scatter(df["常住人口"], 27 df["工人工资"]) 28 sns.regplot(df["常住人口"], 29 df["工人工资"], 30 label="拟合", 31 color="g") 32 plt.show()
截图展示:

通过散点图拟合观察数据的关系
源码:
1 #print(df.describe())#这里可看各数据的中位数,最值 2 edu=[len(df[df["房价"]<5.62525]["房价"]), 3 len(df[df["房价"]>5.62525][df["房价"]<6.963]["房价"]), 4 len(df[df["房价"]>6.963][df["房价"]<9.073075]["房价"]), 5 len(df[df["房价"]>9.073075]["房价"])] 6 #-----------------------------------------------------------数据初处理用来观察我国房价大部分处在什么位置 7 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 8 plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理 9 plt.axes(aspect='equal') #将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆 10 #构造数据 11 labels = ["0-25%", "25-50%", "50-75%", "75-100%"] 12 explode = [0, 0, 0, 0.1] #生成数据,用于凸显房价大部分 13 colors = ['#9999ff', '#ff9999', '#7777aa', '#2442aa'] #自定义颜色 14 plt.pie(edu, #绘图数据 15 explode=explode, #指定饼图某些部分的突出显示,即呈现爆炸式 16 labels=labels, #添加教育水平标签 17 colors=colors, 18 autopct='%.2f%%', #设置百分比的格式,这里保留两位小数 19 pctdistance=0.8, #设置百分比标签与圆心的距离 20 labeldistance=1.1, #设置教育水平标签与圆心的距离 21 startangle=180, #设置饼图的初始角度 22 radius=1.2, #设置饼图的半径 23 counterclock=False, #是否逆时针,这里设置为顺时针方向 24 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值 25 textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值 26 ) 27 #添加图标题 28 plt.title('房价分布') 29 #显示图形 30 plt.show()
截图展示:
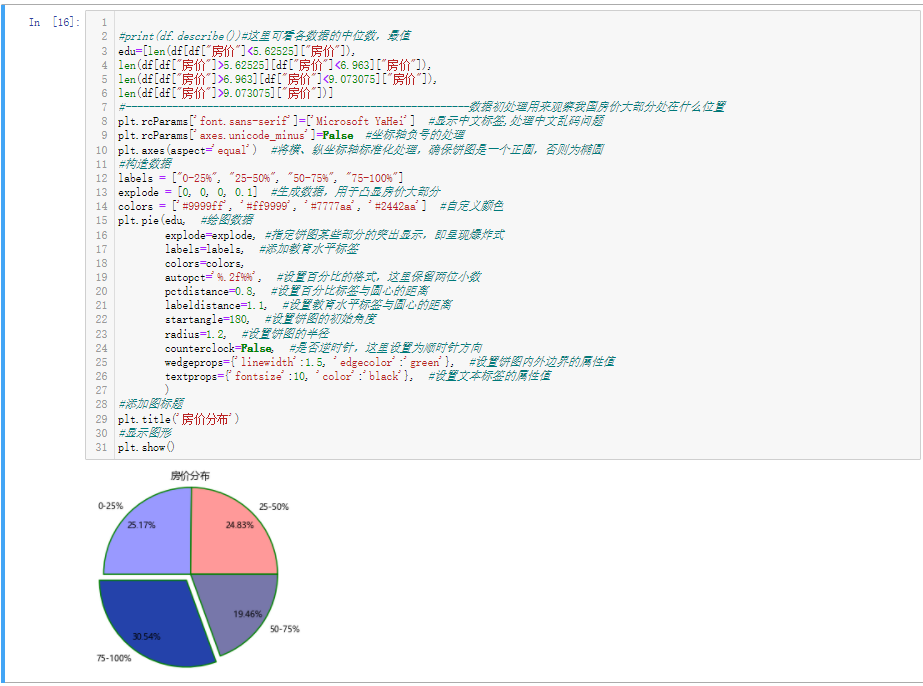
这里通过饼图了解房价的整体分布情况,感觉上还是比较合理,
源码:
1 import pandas as pd 2 from pyecharts.charts import Geo 3 from pyecharts import options as opts 4 attr = df['城市'] 5 value = df['房价'] 6 #str(int(df["房价"][i])) 7 geo = Geo(is_ignore_nonexistent_coord = True) 8 geo.add_schema(maptype = "china", 9 ) 10 #for i in range(len(df["城市"])): 11 # try: 12 # geo.add("2014年全国各城市房价", 13 # [attr,str(int(value))], 14 # type_="scatter", 15 # ) 16 # except: 17 # pass 18 geo.add("2014年全国各城市房价", 19 list(zip(attr,value)), 20 type_="scatter", 21 blur_size=5, 22 point_size=10, 23 is_polyline=True 24 ).set_series_opts(label_opts=opts.LabelOpts(is_show=False) 25 ).set_global_opts(visualmap_opts=opts.VisualMapOpts(max_ = 67), #设置legend显示的最大值 26 title_opts=opts. 27 TitleOpts(title="房价分析图"), #左上角标题 28 ) 29 30 geo.render(path="F:\\2014年全国各城市房价.html")
截图展示:


通过对对应的地区按房价绘制地图发现我国房价大部分处于比较低的。这个图是可以对左下标签索引可以观察区间的这里没办法展示。
源码:
1 # 旭日图 2 a=df[0:50] 3 px.sunburst(a[0:30], # 绘图数据 4 path=["排名","城市"], 5 values='房价', # 数据大小:人口数 6 color='出生率', # 颜色 7 hover_data=['城市'] # 显示数据 8 )
截图展示:
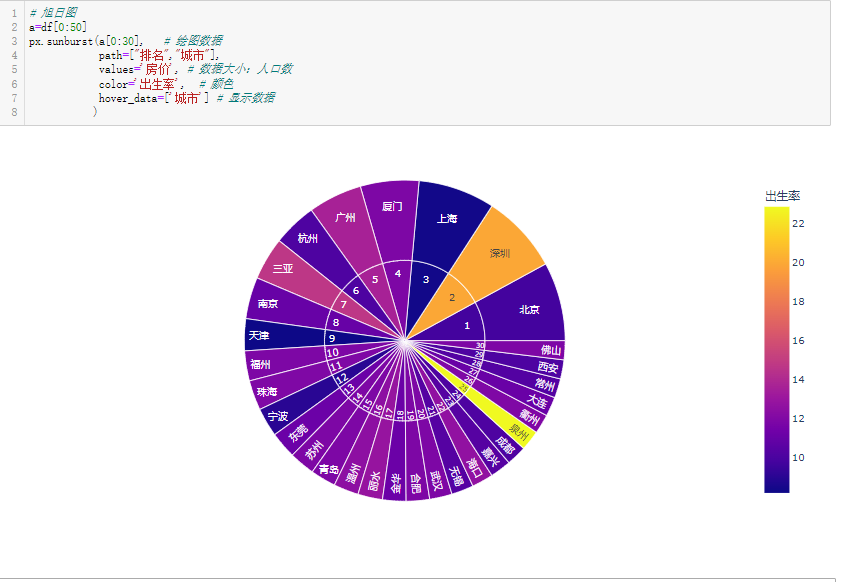
通过旭日图按房价分布绘图前50发现房价高的地区高得离谱。
7.将以上各部分的代码汇总,附上完整程序代码
1 from bs4 import BeautifulSoup 2 import requests 3 import pandas as pd 4 import csv 5 import matplotlib.pyplot as plt 6 from sklearn import metrics 7 import warnings 8 import seaborn as sns 9 import plotly 10 import plotly.express as px 11 import plotly.graph_objects as go 12 import plotly.io as pio 13 import numpy as np 14 warnings.filterwarnings("ignore") 15 def getHTMLText(url): 16 try: 17 headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/\ 18 537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"} 19 r=requests.get(url,headers=headers) 20 r.raise_for_status()#如果状态不是200,就会引发HTTPError异常 21 r.encoding = r.apparent_encoding 22 return r.text 23 except: 24 return "no" 25 def dataProcessing(html):#传入Html数据 26 soup=BeautifulSoup(html) 27 #通过对页面分析可以发现,每个城市房价数据存在于tbody下的td中我们只需要其中的三个数据 28 datas=[] 29 hrefs=[] 30 for i in soup.find_all("tr"): 31 data=i.find_all("td") #找到所有的td标签返回一个集合 32 if len(data)==6: #必须要执行的判断过滤数据 33 ranks=[] #创建一个集合用于存放每一个城市的数据 34 city=i.find("a").string#找到城市的名字 35 ranks.append(data[0].string) #房价排名存在data集合的第一个 36 ranks.append(city) #添加城市名称 37 ranks.append(data[2].string)#房价信息存在于data的第3个 38 datas.append(ranks) #将这个城市的数据放入集合 39 #datas.append(ranks) 40 #datas.append(citys) 41 #datas.append(housePrices) 42 return datas 43 def hrefs(html): 44 hrefs=[] 45 soup=BeautifulSoup(html) 46 for i in soup.find_all("tr"): 47 data=i.find_all("td") #找到所有的td标签返回一个集合 48 if len(data)==6: 49 hrefs.append(i.find("a").get("href"))#创建一个集合用于存放其他数据链接 50 return hrefs 51 url="https://www.gotohui.com/top/" 52 html_1=getHTMLText(url) 53 da=dataProcessing(html_1) 54 hrefs=hrefs(html_1) 55 df=pd.DataFrame(da) 56 a=1 57 dig_data=[] 58 for g in hrefs: 59 html_2=getHTMLText(g) 60 soup_2=BeautifulSoup(html_2) 61 f=[] 62 a_data=[] 63 hreds_data=soup_2.find_all("li")[46:51] 64 for b in hreds_data: 65 f.append(b.find("a").get("href")) 66 #f集合里的5条链接分别是GDP,人口,财政,工资,城建 67 #------------因为这些数据是在同一段数据下没法单独查找,但我只需要其中的2个链接---------------------------- 68 #每个数据的值都给出页面对应的属性 69 #因为这是对每个城市的后续链接进行访问,后续链接的HTML格式一样用循环可以去除大量的代码 70 #-------------------------------------------#这是对人口数据的爬取这些数据最终都被添加于集合中 71 if len(f)==5: 72 html_3=getHTMLText(f[1]) 73 soup_3=BeautifulSoup(html_3) 74 people_data=[] 75 #这里捕捉异常因为在代码运行中发现有些页面并不存在这会导致索引错误 76 try: 77 for c in soup_3.find_all("tr")[7]: 78 people_data.append(c.string) 79 #年份,户籍人口,常住人口,城镇化率(%),增长率(‰),出生率‰ 80 #['\n','2014','\n','332.21','\n','1077.89','\n','100.00','\n','17.48','\n','19.89','\n'] 81 except: 82 people_data=["","","","","","","","","","","","",""] 83 finally: 84 if len(people_data)==13: 85 ok="ok" 86 else: 87 people_data=["","","","","","","","","","","","",""] 88 #-------------------------------------------#这是对工人每年平均工资的爬取这些数据最终都被添加于集合中 89 html_4=getHTMLText(f[3]) 90 soup_4=BeautifulSoup(html_4) 91 price_data=[] 92 #if soup_4.find_all("tr")==None: 93 #这里捕捉异常因为在代码运行中发现有些页面并不存在这会导致索引错误 94 try: 95 for d in soup_4.find_all("tr")[5]: 96 price_data.append(d.string) 97 except: 98 price_data=["","","","","","","","","","",""] 99 finally: 100 if len(price_data)==11: 101 ok="ok" 102 else: 103 price_data=["","","","","","","","","","",""] 104 #年份,职工平均工资(元/年),职工平均工资(元/月),职工人数(万人),职工工资总额(亿元) 105 #['\n','2015','\n','81034.00','\n','6752.83','\n','452.00','\n','3662.72','\n'] 106 a_data.append(people_data[3])#这是户籍人口 107 a_data.append(people_data[5])#这是常住人口 108 a_data.append(people_data[11])#这是出生率 109 a_data.append(price_data[3])#这是当地职员工资 110 dig_data.append(a_data) 111 #这里可以对收集的数据展示,不需要可以删除后面变量,这代码爬取数据实在是太慢, 112 #print("ok",dig_data) 113 #因为数据是跳转了多个网站数据在两个不同的集合这里进行处理 114 big_data=[] 115 for gh in range(len(da)): 116 data=[] 117 data.extend(da[gh]) 118 data.extend(dig_data[gh]) 119 big_data.append(data) 120 #这里将数据写入文件可以方便使用不需要多次爬取数据 121 big_data 122 with open("F:\\新建文件夹 (2)\\房价.csv","w",encoding="utf-8") as fi: 123 writer=csv.writer(fi) 124 writer.writerow(["排名","城市","房价","户籍人口","常住人口","出生率","工人工资"])#给每列的数据列名 125 for a in big_data: 126 writer.writerow(a) 127 fi.close()#数据到此爬取完成 128 df=pd.read_csv("F:\\新建文件夹 (2)\\房价.csv") 129 df["户籍人口"]=df["户籍人口"].fillna(df["户籍人口"].mean()) 130 df["常住人口"]=df["常住人口"].fillna(df["常住人口"].mean()) 131 df["出生率"]=df["出生率"].fillna(df["出生率"].mean()) 132 df["工人工资"]=df["工人工资"].fillna(df["工人工资"].mean()) 133 #df.loc[0:,"房价"].split(",")[0] 134 for h in range(300): 135 f=[] 136 f.extend(df.loc[h,"房价"].split(",")) 137 df.loc[h,"房价"]=".".join(f) 138 df["房价"]=df["房价"].apply(float) 139 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 140 #房价 141 plt.subplot(2,2,1) 142 plt.boxplot(df["房价"], 143 patch_artist=True, 144 meanline=True, 145 showmeans=True,) 146 plt.title("房价") 147 #常住人口 148 plt.subplot(2,2,2) 149 plt.boxplot(df["常住人口"], 150 patch_artist=True, 151 meanline=True, 152 showmeans=True,) 153 plt.title("常住人口") 154 #出生率 155 plt.subplot(2,2,3) 156 plt.boxplot(df["出生率"], 157 patch_artist=True, 158 meanline=True, 159 showmeans=True,) 160 plt.title("出生率") 161 #工人工资 162 plt.subplot(2,2,4) 163 plt.boxplot(df["工人工资"], 164 patch_artist=True, 165 meanline=True, 166 showmeans=True,) 167 plt.title("工人工资") 168 plt.show() 169 #对房价和出生率进行分析并拟合观察房价的高低是否影响到房价 170 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 171 plt.plot(df["房价"], 172 df["出生率"], 173 label="房价-出生率") 174 sns.regplot(df["房价"], 175 df["出生率"], 176 label="预测曲线")#二次拟合 177 plt.xlabel("房价") 178 plt.ylabel("出生率") 179 plt.title('房价出生率分析') 180 plt.legend() 181 plt.grid() 182 plt.show() 183 #通过对工人工资分析与房价关系 184 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 185 plt.plot(df["工人工资"], 186 df["房价"], 187 label='工人工资-房价') 188 sns.regplot(df["工人工资"], 189 df["房价"], 190 label="拟合") 191 plt.xlabel("工人工资") 192 plt.ylabel("房价") 193 plt.title('房价出生率分析') 194 plt.legend() 195 plt.grid() 196 plt.show() 197 #通过对常住分析与房价关系 198 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] 199 plt.plot(df["常住人口"], 200 df["房价"], 201 label='常住人口-房价') 202 sns.regplot(df["常住人口"], 203 df["房价"], 204 label='拟合') 205 plt.xlabel("常住人口") 206 plt.ylabel("房价") 207 plt.title('房价常住人口分析') 208 plt.legend() 209 plt.grid() 210 plt.show() 211 #折线不能很好反应数据这里用散点拟合 212 plt.subplot(2,2,1) 213 plt.scatter(df["房价"], 214 df["常住人口"], 215 label="拟合", 216 color="b") 217 sns.regplot(df["房价"], 218 df["常住人口"], 219 label="拟合", 220 color="b") 221 plt.subplot(2,2,2) 222 plt.scatter(df["房价"], 223 df["出生率"]) 224 sns.regplot(df["房价"], 225 df["出生率"], 226 label="拟合", 227 color="r") 228 plt.subplot(2,2,3) 229 plt.scatter(df["工人工资"], 230 df["房价"]) 231 sns.regplot(df["工人工资"], 232 df["房价"], 233 label="拟合", 234 color="k") 235 plt.subplot(2,2,4) 236 plt.scatter(df["常住人口"], 237 df["工人工资"]) 238 sns.regplot(df["常住人口"], 239 df["工人工资"], 240 label="拟合", 241 color="g") 242 plt.show() 243 244 #print(df.describe())#这里可看各数据的中位数,最值 245 edu=[len(df[df["房价"]<5.62525]["房价"]), 246 len(df[df["房价"]>5.62525][df["房价"]<6.963]["房价"]), 247 len(df[df["房价"]>6.963][df["房价"]<9.073075]["房价"]), 248 len(df[df["房价"]>9.073075]["房价"])] 249 #-----------------------------------------------------------数据初处理用来观察我国房价大部分处在什么位置 250 plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题 251 plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理 252 plt.axes(aspect='equal') #将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆 253 #构造数据 254 labels = ["0-25%", "25-50%", "50-75%", "75-100%"] 255 explode = [0, 0, 0, 0.1] #生成数据,用于凸显房价大部分 256 colors = ['#9999ff', '#ff9999', '#7777aa', '#2442aa'] #自定义颜色 257 plt.pie(edu, #绘图数据 258 explode=explode, #指定饼图某些部分的突出显示,即呈现爆炸式 259 labels=labels, #添加教育水平标签 260 colors=colors, 261 autopct='%.2f%%', #设置百分比的格式,这里保留两位小数 262 pctdistance=0.8, #设置百分比标签与圆心的距离 263 labeldistance=1.1, #设置教育水平标签与圆心的距离 264 startangle=180, #设置饼图的初始角度 265 radius=1.2, #设置饼图的半径 266 counterclock=False, #是否逆时针,这里设置为顺时针方向 267 wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值 268 textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值 269 ) 270 #添加图标题 271 plt.title('房价分布') 272 #显示图形 273 plt.show() 274 import pandas as pd 275 from pyecharts.charts import Geo 276 from pyecharts import options as opts 277 attr = df['城市'] 278 value = df['房价'] 279 #str(int(df["房价"][i])) 280 geo = Geo(is_ignore_nonexistent_coord = True) 281 geo.add_schema(maptype = "china", 282 ) 283 #for i in range(len(df["城市"])): 284 # try: 285 # geo.add("2014年全国各城市房价", 286 # [attr,str(int(value))], 287 # type_="scatter", 288 # ) 289 # except: 290 # pass 291 geo.add("2014年全国各城市房价", 292 list(zip(attr,value)), 293 type_="scatter", 294 blur_size=5, 295 point_size=10, 296 is_polyline=True 297 ).set_series_opts(label_opts=opts.LabelOpts(is_show=False) 298 ).set_global_opts(visualmap_opts=opts.VisualMapOpts(max_ = 67), #设置legend显示的最大值 299 title_opts=opts. 300 TitleOpts(title="房价分析图"), #左上角标题 301 ) 302 303 geo.render(path="F:\\2014年全国各城市房价.html") 304 # 旭日图 305 a=df[0:50] 306 px.sunburst(a[0:30], # 绘图数据 307 path=["排名","城市"], 308 values='房价', # 数据大小:人口数 309 color='出生率', # 颜色 310 hover_data=['城市'] # 显示数据 311 )
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
对我国房价对比大部分处于还是比较正常的位置,但多数处于南方地区,但这只是对我们国家里面的房价对比,也许不太合理。我国今后的住房建设可以向西北地区倾斜。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
进一步了解的python在大数据方面的优越,对基础语法更加了解,该爬虫的后续可以通过于世界房价的比较进一步总结,又因为该数据是2014年的我在爬取的时候对于加密的数据没法处理,如何去爬取经过加密的数据是今后要解决的问题。因为如此该数据不能很好反应今天的状况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号