第一次作业-三次小作业
1.用requests和BeautifulSoup库方法定向爬取给定网址(http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html)的数据,屏幕打印爬取的大学排名信息。 打印示例: 排名 学校名称 省市 学校类型 1 清华大学 北京 综合
代码
from bs4 import BeautifulSoup import urllib.request url='http://www.shanghairanking.cn/rankings/bcur/2020' req=urllib.request.urlopen(url) data=req.read() #读取url网站的内容 html=data.decode() #将二进制数据转为字符串 soup=BeautifulSoup(html,"html.parser") #创建名称为soup的BeautifulSoup对象,指定html的解析器为’html.parser‘ lis=soup.find('tbody').children # 获取'tbody'的子元素结点 print("排名\t学校名称\t省市\t学校类型\t总分") for li in lis: r = li.find_all("td") print(r[0].text.strip() + "\t" + r[1].text.strip() + "\t" + r[2].text.strip() + " " + r[3].text.strip() + " " + r[4].text.strip()) #输出
结果

心得:了解了网页爬取的基本步骤,初步掌握了beautiful soup和request库的用法
2.要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码
import requests import re def getHTMLText(url): kv = {'cookie': 'cookie: t=d61223e23cf95eaf3a7427e46620aa24; cna=KknhFroZHEcCAXgEbDkPkMA5; uc3=id2=VyyY5AHPxrqV%2Fw%3D%3D&vt3=F8dBxd7Ed9v7gopWytk%3D&nk2=F5RDL9RuzK7CKw%3D%3D&lg2=W5iHLLyFOGW7aA%3D%3D; lgc=tb63955929; uc4=nk4=0%40FY4I7KuEOrzqo%2FORxKFzLHtXG%2FsW&id4=0%40VXtXDzG6mttLTb9dnw5IY8EDQymW; tracknick=tb63955929; _cc_=U%2BGCWk%2F7og%3D%3D; tg=0; enc=LkWXCr2rjtrUCLxXukiml03lT75soVzYczcswxlr3pPb91SbW6nkCHg9kH18ZBufnpJmNA%2BV4hlHn3ZYmwG5wA%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=43_1; thw=cn; _samesite_flag_=true; cookie2=7ca742e000f0e87cb18cd16d396d59c7; _tb_token_=fb77408ed1e35; tfstk=cAHPBOXQbLpyCdOD1RyURCxwrZoRZHHnCQELZfX6epLMjPPli9bLmUI-y2z9n7f..; JSESSIONID=F698065DA30CCD2462BC75EEB3EAA4CB; v=0; l=dBaLyT4nQF2x7TpkBOCgCm5f0AQTdIRAgul44rNpi_5dp1T1cDbOour9He96cjWftUTB4o0COBe9-etktBDmndK-g3fPaxDc.; isg=BK-vdiweLUCDhSl8udLLyqTuPsO5VAN2g_ZtwcE8YZ4lEM8SySTgxq3KkgAuaNvu; uc1=cookie14=UoTUOan4slJdzQ%3D%3D', 'user-agent': 'Mozilla/5.0'}#cookie try: r = requests.get(url, headers=kv, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt,html): try: plt=re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) slt = re.findall(r'\"view_sales\"\:\".*?\"', html) #识别销量 tlt=re.findall(r'\"raw_title\"\:\".*?\"',html) for i in range(len(plt)): price=eval(plt[i].split(':')[1]) sales=eval(slt[i].split(':')[1]) title=eval(tlt[i].split(':')[1]) ilt.append([price,sales,title]) except: print("")#获取商品信息 def printGoodList(ilt): tplt="{:4}\t{:8}\t{:16}" print(tplt.format("序号","价格","商品名称")) count=0 for g in ilt: count=count+1 print(tplt.format(count,g[0],g[1]))#输出函数 def main(): goods="书包" depth=2 start_url="https://s.taobao.com/search?q="+goods infoList=[] for i in range(depth+1): try: url=start_url+"&s="+str(44*i)#翻页处理 html=getHTMLText(url) parsePage(infoList,html) except: continue printGoodList(infoList) main()
结果
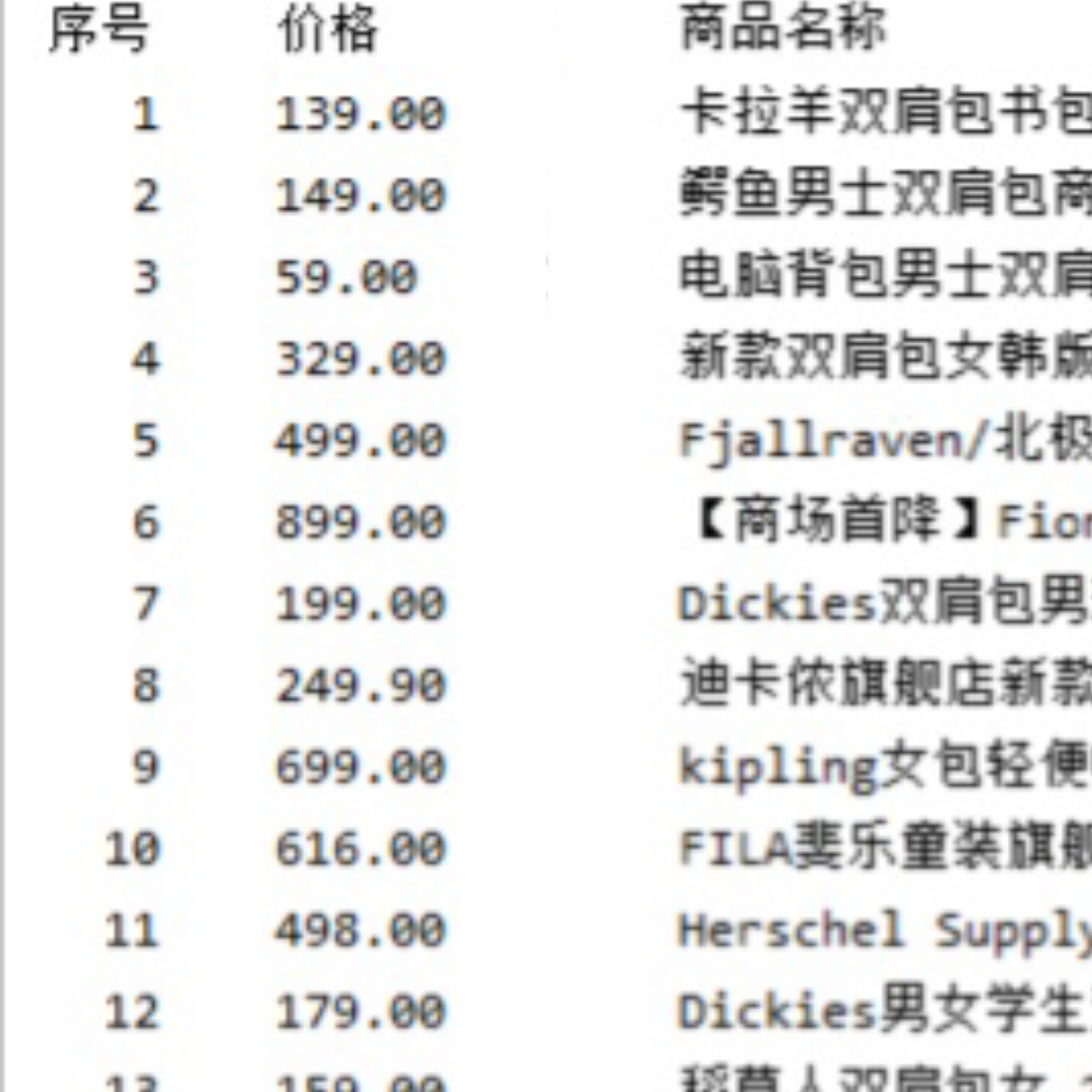
心得:由于淘宝不允许爬虫,所以要将headers改掉,在csdn上查阅后发现要用cookie,打开淘宝商品页面,登录淘宝账号,F12进入浏览器的开发者调试工具,点击Network,重新刷新页面,选择最上面的search?initiative_id=......的dos文件,找到Request Headers,复制获得cookie。
3.JPGFileDownload实验
作业要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
代码
import re import requests import urllib.request import os r = requests.get("http://xcb.fzu.edu.cn/") path = "D:/new file/images1/" html = re.sub("<!--(.|\n)*?-->", "", r.text) i = 0 if (not os.path.exists(path)): #判断文件路径是否存在,不存在就创建 os.mkdir(path) for jpg in re.compile("src=\".*\.jpg| \".*\.jpg", re.I).findall(html): # 图片地址筛选 i = i + 1 if (jpg[:3] == "src"): # 判断是否src开头 if (jpg[5:9] == "http"): # 判断是否绝对路径 url = jpg[5:] else: url = "http://xcb.fzu.edu.cn" + jpg[5:] else: url = "http://xcb.fzu.edu.cn" + jpg[2:] name = url.split("/")[-1] f = urllib.request.urlopen(url) # 图片写入文件夹 with open(path + name, "wb") as code: code.write(f.read()) print(url) #输出图片路径
结果
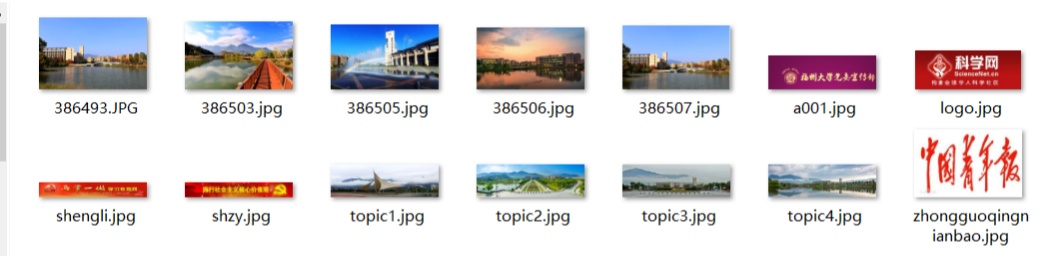
心得:使用正则表达式筛选下载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号