【MySQL】常用监控指标及监控方法
对之前生产中使用过的MySQL数据库监控指标做个小结。
| 指标分类 | 指标名称 | 指标说明 |
| 性能类指标 | QPS | 数据库每秒处理的请求数量 |
| TPS | 数据库每秒处理的事务数量 | |
| 并发数 | 数据库实例当前并行处理的会话数量 | |
| 连接数 | 连接到数据库会话的数量 | |
| 缓存命中率 | 查询命中缓存的比例 | |
| 高可用指标 | 可用性 | 数据库是否可以正常对外服务 |
| 阻塞 | 当前阻塞的会话数 | |
| 慢查询 | 慢查询情况 | |
| 主从延迟 | 主从延迟时间 | |
| 主从状态 | 主从链路是否正常 | |
| 死锁 | 查看死锁信息 |
【QPS指标】
show global status where variable_name in ('Queries', 'uptime');
QPS = (Queries2 -Queries1) / (uptime2 - uptime1)

【TPS指标】
show global status where variable_name in ('com_insert' , 'com_delete' , 'com_update', 'uptime');
事务数TC ≈'com_insert' , 'com_delete' , 'com_update'
TPS ≈ (TC2 -TC1) / (uptime2 - uptime1)
【并发数】
show global status like 'Threads_running';

【连接数】
当前连接数:
show global status like 'Threads_connected';
最大连接数:
show global status like 'max_connections';
生产中配置报警阈值:Threads_connected / max_connections > 0.8
【缓存命中率】
innodb缓冲池查询总数:
show global status like 'innodb_buffer_pool_read_requests';
innodb从磁盘查询数:
show global status like 'innodb_buffer_pool_reads';
生产中配置报警阈值:(innodb_buffer_pool_read_requests - innodb_buffer_pool_reads) / innodb_buffer_pool_read_requests > 0.95

【可用性】
方法1:周期性连接数据库并执行 select @@version;
方法2:mysqladmin -u数据库用户名 -p数据库密码 -h数据库实例IP ping 
【阻塞】
MySQL5.7之前:
select b.trx_mysql_thread_id as '被阻塞线程', b.trx_query as '被阻塞SQL', c.trx_mysql_thread_id as '阻塞线程', c.trx_query as '阻塞SQL', (unix_timestamp()-unix_timestamp(c.trx_started)) as '阻塞时间' from information_schema.innodb_lock_waits a join information_schema.innodb_trx b on a.requesting_trx_id=b.trx_id join information_schema.innodb_trx c on a.blocking_trx_id=c.trx.id where(unix_timestamp()-unix_timestamp(c.trx_started))>阻塞秒数
MySQL5.7及之后:
为方便查询阻塞指标,MySQL将2张表join构造了一个view sys.innodb_lock_waits,查询语句得以大大简化。
select waiting_pid as '被阻塞线程', waiting_query as '被阻塞SQL', blocking_pid as '阻塞线程', blocking_query as '阻塞SQL', wait_age as '阻塞时间', sql_kill_blocking_query as '建议操作' from sys.innodb_lock_waits where(unix_timestamp()-unix_timestamp(wait_started))>阻塞秒数

【慢查询】
方法1:开启慢查询日志。my.inf
slow_query_log=on slow_query_log_file=存放目录 long_query_time=0.1秒 log_queries_not_using_indexes=on
注:只对新建连接生效,实时生效使用命令set global 上述配置项。
方法2:
select * from information_schema.'processlist';

【主从延迟】
方法1:
show slave status;

问题:
该方法是基于relaylog的时间与master的时间差值,并不太准,例如大事务时,主从延时已发生,但relaylog还未生成。
方法2:使用Percona的pt-heartbeat工具
- Master后台周期写入:
pt-heartbeat --user=Master用户名 --password=Master密码 --h MasterIP --create-table --database 测试库名 --updatte --daemonize --interval=1
--create-table 在Master上创建心跳监控表heartbeat,通过更新该表知道主从延迟的差距。
--daemonize 后台执行。
--interval=1 默认1秒执行一次。
- Slave后台周期同步读取:
pt-heartbeat --user=Slave用户名 --password=Slave密码 --h SlaveIP --database 库名 --monitor --daemonize --log /slave_lag.log
--monitor参数是持续监测并输出结果
【主从状态】
show slave status;

【死锁】
方法1:查看最近一次死锁信息:
show engine innodb status;

方法2:使用Percona的pt-deadlock-logger工具
1.打开死锁打印全局开关
set global innodb_print_all_deadlocks=on;
2.使用pt-deadlock-logger工具
监控到的死锁结果可以输出到文件、指定表、或者界面打印。
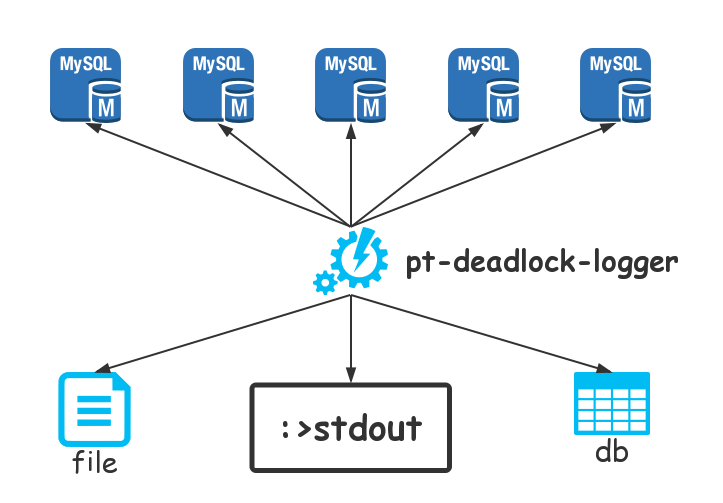
pt-deadlock-logger h=数据库IP,u=数据库用户名,p=数据库密码
输出结果非常详尽:
server:数据库服务器地址,即死锁产生的数据库主机
ts:检测到死锁的时间戳
thread:产生死锁的线程id,这个id和show processlist里面的线程id是一致的
txn_id:innodb的事务ID
txd_time:死锁检查到前,事务执行时间
user:执行transcation的用户名
hostname:客户端主机名
ip:客户端ip
db:发生死锁的DB名
tbl:死锁发生的表名
idx:产生死锁的索引名(在上面这个demo里面, 我们直接走的主键,加的记录锁)
lock_type:锁的类型(记录锁,gap锁,next-key锁)
lock_mode:锁模式(S,X)
wait_hold:是否等着锁释放,一般死锁都是两个wait
victim:该会话是否做了牺牲,终止了执行
query:造成死锁的SQL语句


 浙公网安备 33010602011771号
浙公网安备 33010602011771号