【Spark调优】数据倾斜及排查
【数据倾斜及调优概述】
大数据分布式计算中一个常见的棘手问题——数据倾斜:
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了百万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了百万数据,要运行一两个小时。木桶原理,整个作业的运行进度是由运行时间最长的那个task决定的。
出现数据倾斜的时候,绝大多数task执行得都非常快,但个别task执行极慢。例如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。原本能够正常执行的Spark作业,某天突然报出OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
此时Spark作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决不同类型的数据倾斜问题,以保证Spark作业的性能。
【定位发生数据倾斜的代码】
1) 数据倾斜只会发生在shuffle过程中。所以关注一些常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出现数据倾斜时,可能就是代码中使用了这些算子中的某一个所导致的。
2)通过观察spark UI的界面,定位数据倾斜发生在第几个stage中。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到当前运行到了第几个stage;如果是用yarn-cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。此外,无论是使用yarn-client模式还是yarn-cluster模式,我们都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
- 1段提交代码是1个Application
![]()
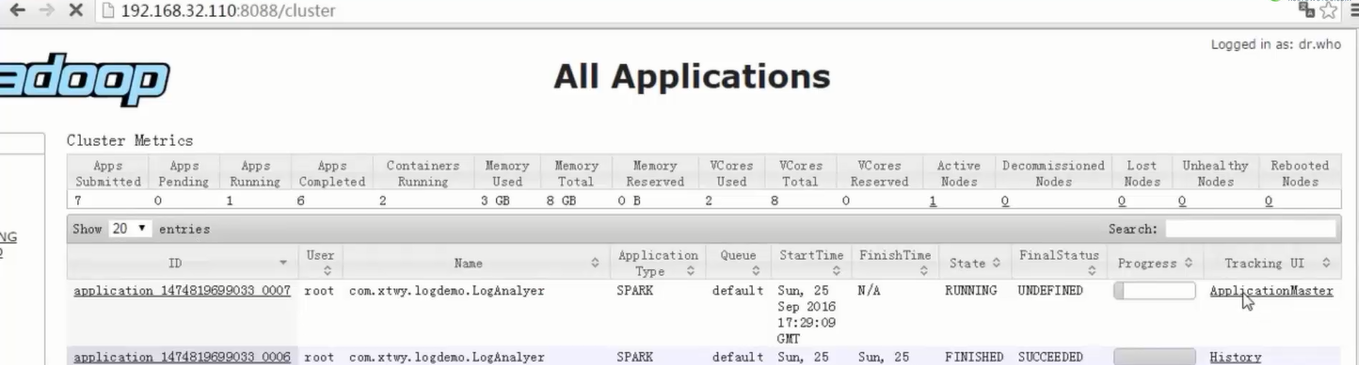
- 1个action算子是1个job
![]()
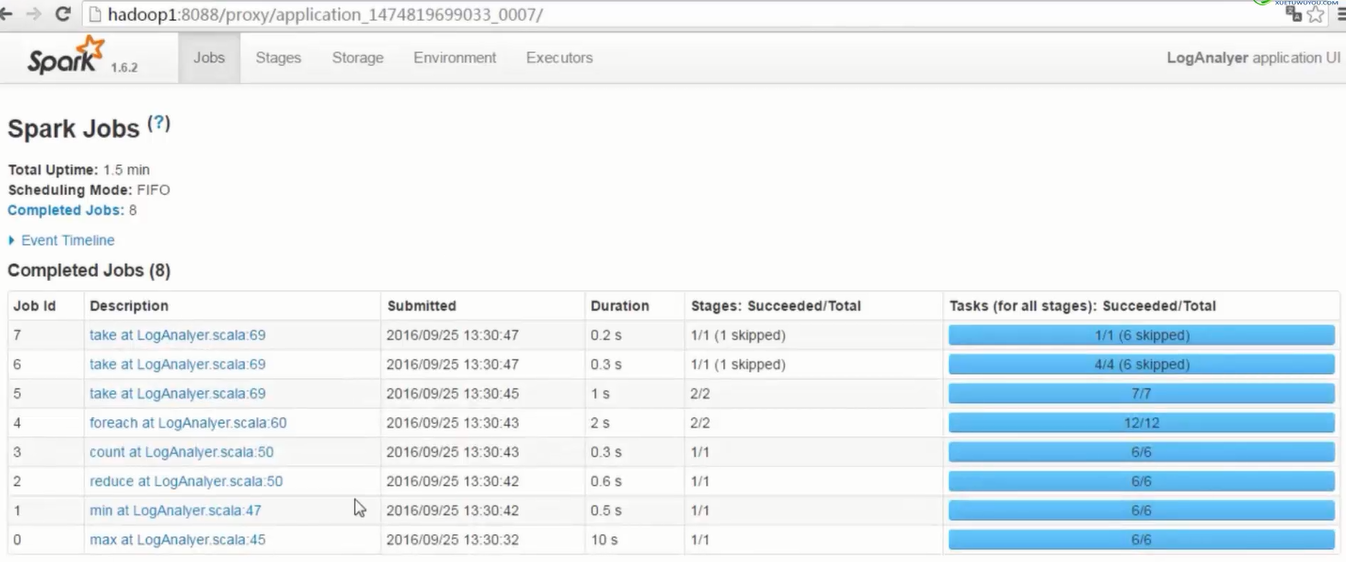
- 1个job中,以宽依赖为分割线,划分成不同stage,stage编号从0开始
![]()
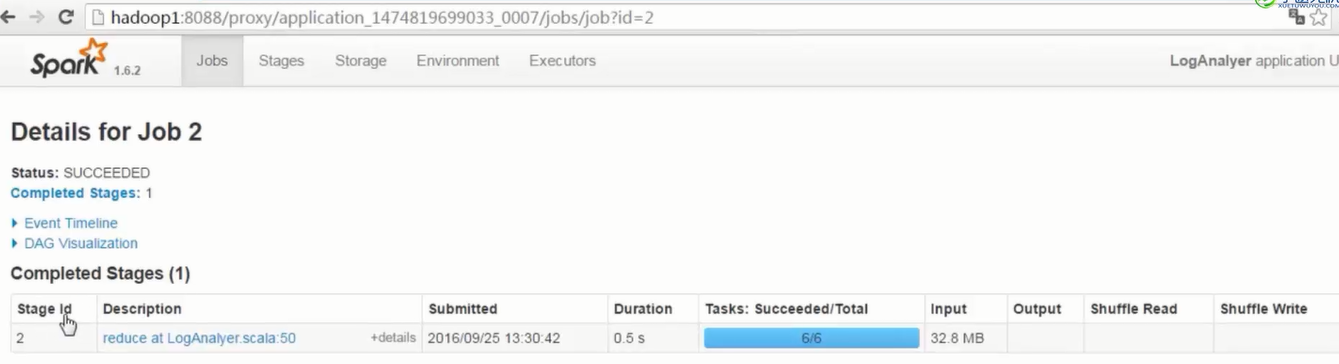
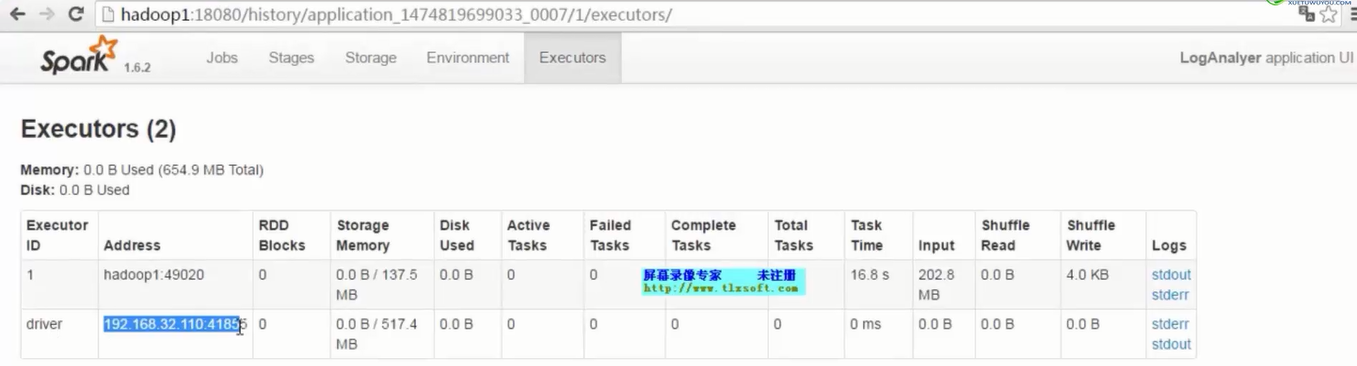
- 1个stage中,划分出参数指定数量的task,注意观察Locality Level和Duration列
![]()

- Executor数量是配置参数指定的
![]()
- 看结果文件---自己统计代码中println的打印
![]()
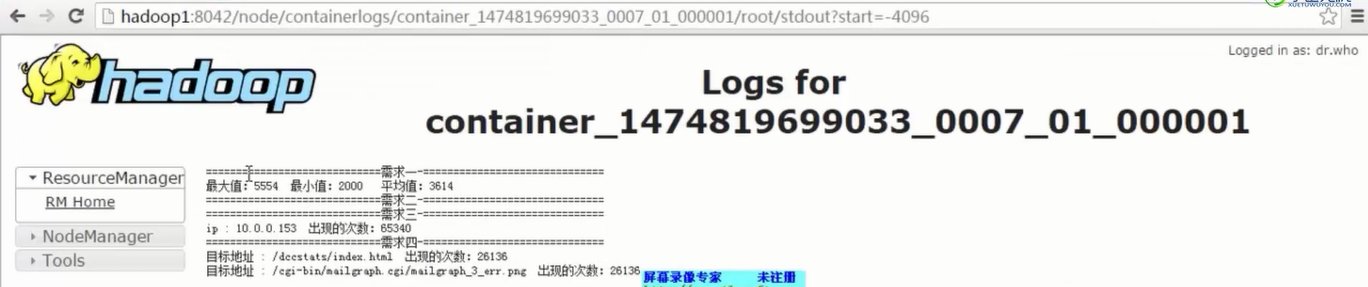
3)根据 【Spark工作原理】stage划分原理理解 中的stage的划分算法定位到极有可能发生数据倾斜的代码

【查看导致数据倾斜的key的分布情况】
1. 如果是Spark SQL中的group by、join语句导致的数据倾斜,那么就查询一下SQL中使用的表的key分布情况。
2. 如果是对Spark RDD执行shuffle算子导致的数据倾斜,那么可以在Spark作业中加入查看key分布的代码,比如RDD.countByKey()。然后对统计出来的各个key出现的次数,collect/take到客户端打印一下,就可以看到key的分布情况。
不放回sample+countByKey查看key分布,是否数据倾斜
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号