
mysql查询语句
4.条件查询,两种写法效果不一样
#==========时间: 11.393s 时间: 10.757s
SELECT id,name,sex,birthday,mobile,emergency_phone,create_time FROM student WHERE is_in_school=1 AND user_id IN
(
SELECT id FROM users_front WHERE regist_type = 4
)LIMIT 2000000 ;
SELECT s.id,s.`name`,s.sex,s.birthday,s.mobile,s.emergency_phone,s.create_time FROM student s,users_front u
WHERE s.is_in_school=1 AND s.user_id =u.id AND u.regist_type = 4 LIMIT 2000000; #查询更快一点
3.查询表中最后几条记录( ORDER BY id DESC LIMIT *)
查询最后20条记录
SELECT * from student_pay_master ORDER BY id DESC LIMIT 20 ;
2.查询某字段为空的记录 (用is null)
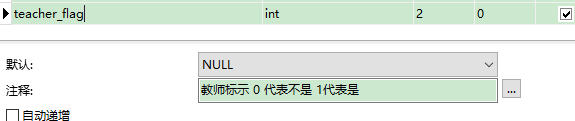
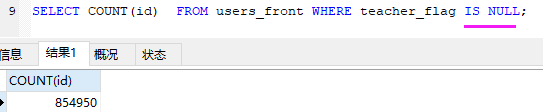
查询用户表中,学生身份的记录:
1.去重的使用
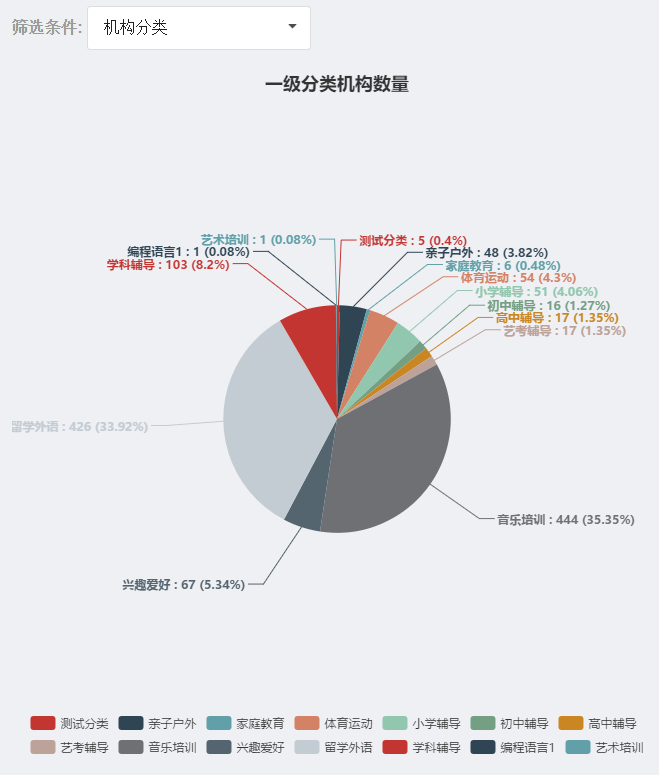
查询一级分类下的机构数量 如下面的效果图
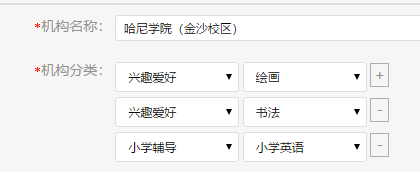
机构所属分类可以有多个,可以是同一级分类+不同二级分类,也可以是多个一级分类:
机构和分类的关系表:
ins_id(机构id)、one_level_id(一级分类的分类id) two_level_id(二级分类的分类id)
---------------------------------------------------------------------------------------------------------------
对应的sql,用到group by,按分类分组统计,另外注意去重
SELECT count(DISTINCT ins_id) FROM institution_relation GROUP BY one_level_id;
查询结果如下:

=============================================
in和exists的区别
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询
select * from user where userId in (1, 2, 3);
等效于
select * from user where userId = 1 or userId = 2 or userId = 3;
not in与in相反,如下
select * from user where userId not in (1, 2, 3);
等效于
select * from user where userId != 1 and userId != 2 and userId != 3;
总的来说,in查询就是先将子查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后在将子查询条件的结果集分解成m个,再进行m次查询
值得一提的是,in查询的子条件返回结果必须只有一个字段,例如
select * from user where userId in (select id from B);
而不能是
select * from user where userId in (select id, age from B);
而exists就没有这个限制
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号