
JVM之工具分析
JVM分析工具有很多;
jdk自带工具:jconsole、jvisualvm
其他工具:jprofile ,yourkit等
不要在线上用,影响性能,在测试环境中使用。
一、jconsole ——jdk自带工具分析
内存监控——内存”页签相当于可视化的jstat命令的话
1、没有任何操作,内存还在上升,why???
rmi协议导致的,rmi通信的时候会产生一些对象,所以这里内存会上升,可以点击右上角的绿色那个,断开rmi连接,就不会增长了。
执行gc这里是full-gc,系统调用都是full-gc。
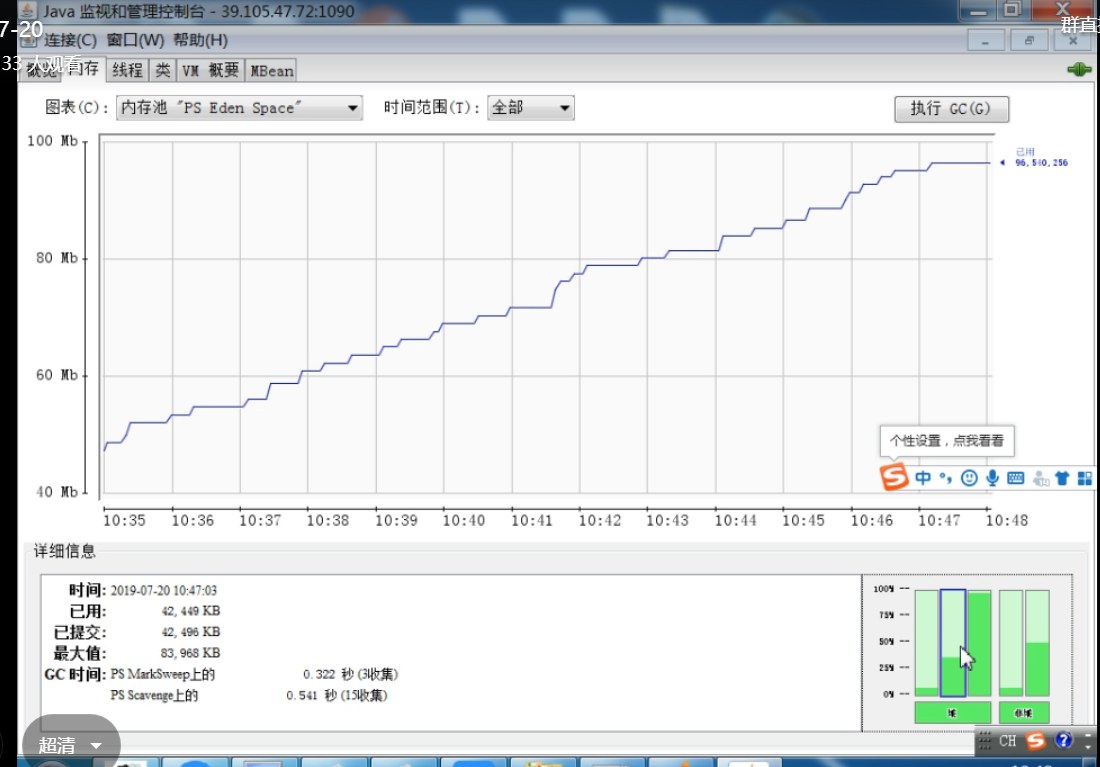
2、很有规律的波动,是在进行y-gc。

相关gc日志如下:
[GC (Allocation Failure) [DefNew: 27277K->3392K(30720K), 0.0349173 secs] 27277K->14749K(99008K), 0.0350411 secs] [Times: user=0.03 sys=0.00, real=0.04 secs] [GC (Allocation Failure) [DefNew: 30691K->3378K(30720K), 0.0446635 secs] 42049K->39217K(99008K), 0.0447387 secs] [Times: user=0.03 sys=0.01, real=0.04 secs] [GC (Allocation Failure) [DefNew: 30679K->3372K(30720K), 0.0408609 secs] 66518K->64734K(99008K), 0.0409604 secs] [Times: user=0.02 sys=0.02, real=0.04 secs] [Full GC (System.gc()) [Tenured: 61362K->66352K(68288K), 0.0372192 secs] 67024K->66352K(99008K), [Metaspace: 9535K->9535K(1058816K)], 0.0373411 secs] [Times: user=0.05 sys=0.00, real=0.04 secs]
3、出现问题
下面代码的作用是以64kb/50ms的速度王java堆中填充数据,一共1000次,然后使用jconsole监控,
/** * 内存占位符对象,一个OOMObject大约占64KB */ static class OOMObject { public byte[] placeholder = new byte[64 * 1024]; }  public static void fillHeap(int num) throws InterruptedException { List<OOMObject> list = new ArrayList<OOMObject>(); for (int i = 0; i < num; i++) { //稍作延时,令监视曲线的变化更加明显 Thread.sleep(50); list.add(new OOMObject()); } System.gc(); }  public static void main(String[] args) throws Exception { fillHeap(1000); }
程序运行后,在“内存”页签中可以看到内存池Eden区的运行趋势呈现折线状,如图4-6所示。而监视范围扩大至整个堆后,会发现曲线是一条向上增长的平滑曲线。并且从柱状图可以看出,在1000次循环执行结束,运行了System.gc()后,虽然整个新生代Eden和Survivor区都基本被清空了,但是代表老年代的柱状图仍然保持峰值状态,说明被填充进堆中的数据在System.gc()方法执行之后仍然存活。

为何执行了System.gc()之后,图4-6中代表老年代的柱状图仍然显示峰值状态,代码需要如何调整才能让System.gc()回收掉填充到堆中的对象?
答:执行完System.gc()之后,空间未能回收是因为List<OOMObject>list对象仍然存活,fillHeap()方法仍然没有退出,因此list对象在System.gc()执行时仍然处于作用域之内。如果把System.gc()移动到fillHeap()方法外调用就可以回收掉全部内存。
线程监控——“线程”页签的功能相当于可视化的jstack命令
遇到线程停顿时可以使用这个页签进行监控分析。线程长时间停顿的主要原因主要有:等待外部资源(数据库连接、网络资源、设备资
源等)、死循环、锁等待(活锁和死锁)
/**
* 等待控制台输入
* @throws IOException
*/
public static void waitRerouceConnection () throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
br.readLine();
}
/**
/** * 线程死循环演示 */ public static void createBusyThread() { Thread thread = new Thread(new Runnable() { @Override public void run() { while (true) //第41行 ; } }, "testBusyThread"); thread.start(); }  /** * 线程锁等待演示 */ public static void createLockThread(final Object lock) { Thread thread = new Thread(new Runnable() { @Override public void run() { synchronized (lock) { try { lock.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } } }, "testLockThread"); thread.start(); }  public static void main(String[] args) throws Exception { BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); br.readLine(); createBusyThread(); br.readLine(); }
程序运行后,首先在“线程”页签中选择main线程,如图4-7所示。堆栈追踪显示BufferedReader在readBytes方法中等待System.in的键盘输入,这时线程为Runnable状态,Runnable状态的线程会被分配运行时间,但readBytes方法检查到流没有更新时会立刻归还执行令牌,这种等待只消耗很小的CPU资源。
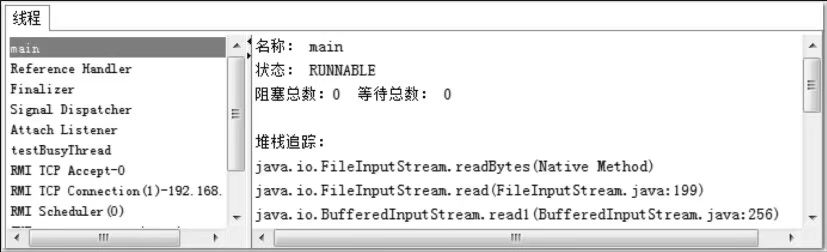
接着监控testBusyThread线程,testBusyThread线程一直在执行空循环,从堆栈追踪中看到一直在MonitoringTest.java代码的41行停留,41行为:while (true)。这时候线程为Runnable状态,而且没有归还线程执行令牌的动作,会在空循环上用尽全部执行时间直到线程切换,这种等待会消耗较多的CPU资源。如下图:
testLockThread线程在等待着lock对象的notify或notifyAll方法的出现,线程这时候处于WAITING状态,在被唤醒前不会被分配执行时间。如下图:

线程死锁案例演示:
testLockThread线程正在处于正常的活锁等待,只要lock对象的notify()或notifyAll()方法被调用,这个线程便能激活以继续执行。下面代码演示了一个无法再被激活的死锁等待。
/** * 线程死锁等待演示 */ static class SynAddRunalbe implements Runnable { int a, b; public SynAddRunalbe(int a, int b) { this.a = a; this.b = b; }  @Override public void run() { synchronized (Integer.valueOf(a)) { synchronized (Integer.valueOf(b)) { System.out.println(a + b); } } } }  public static void main(String[] args) { for (int i = 0; i < 100; i++) { new Thread(new SynAddRunalbe(1, 2)).start(); new Thread(new SynAddRunalbe(2, 1)).start(); } }
这段代码开了200个线程去分别计算1+2以及2+1的值,其实for循环是可省略的,两个线程也可能会导致死锁,不过那样概率太小,需要尝试运行很多次才能看到效果。一般的话,带for循环的版本最多运行2~3次就会遇到线程死锁,程序无法结束。造成死锁的原因是Integer.valueOf()方法基于减少对象创建次数和节省内存的考虑,[-128,127]之间的数字会被缓存,当valueOf()方法传入参数在这个范围之内,将直接返回缓存中的对象。也就是说,代码中调用了200次Integer.valueOf()方法一共就只返回了两个不同的对象。假如在某个线程的两个synchronized块之间发生了一次线程切换,那就会出现线程A等着被线程B持有的Integer.valueOf(1),线程B又等着被线程A持有的Integer.valueOf(2),结果出现大家都跑不下去的情景。
出现线程死锁之后,点击JConsole线程面板的“检测到死锁”按钮,将出现一个新的“死锁”页签,如下图:

上图很清晰地显示了线程Thread-43在等待一个被线程Thread-12持有Integer对象,而点击线程Thread-12则显示它也在等待一个Integer对象,被线程Thread-43持有,这样两个线程就互相卡住,都不存在等到锁释放的希望了。
二、jvisualvm ——jdk自带分析工具, jconsole的升级版
JVisualVM的有一个很大的优点:不需要被监视的程序基于特殊Agent运行,因此它对应用程序的实际性能的影响很小,使得它可以直接应用在生产环境中。这个优点是JProfiler、YourKit等工具无法与之媲美的。
jvisualvm需要自己安装插件,点击工具-插件,然后点击可用插件,都安装上。
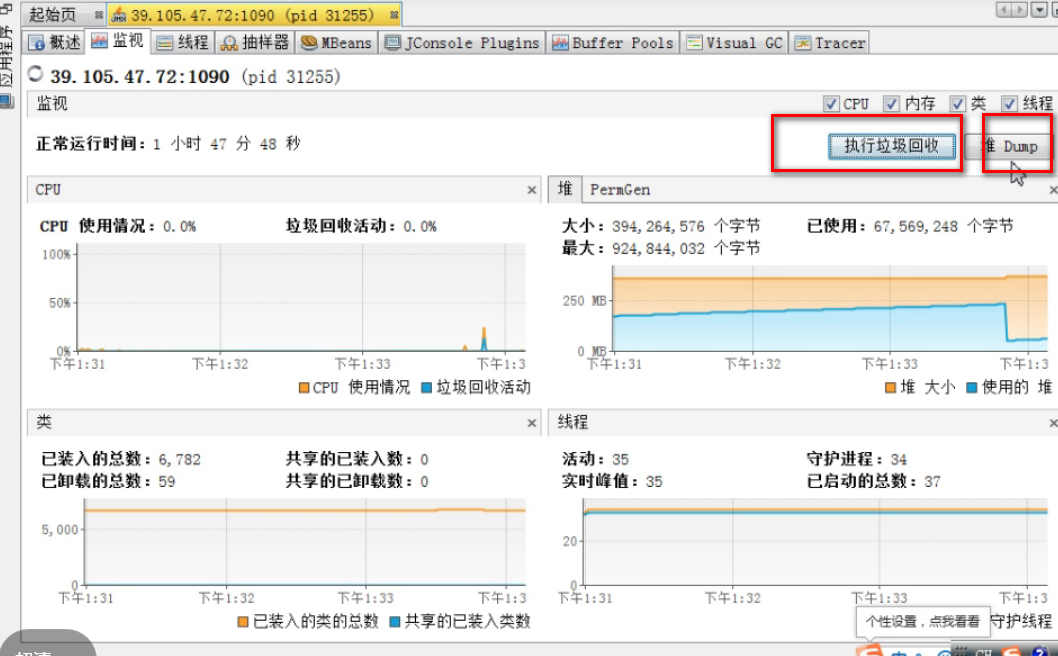
执行垃圾回收:system.gc
堆 Dump:把内存信息dump下来
还可以对dump下的东西进行分析,装入
对tomcat下的test1里的init2.jsp进行压测, http://192.168.1.17:8080/test1/init2.jsp,然后监控线程,cpu,内存等。
1、监控线程

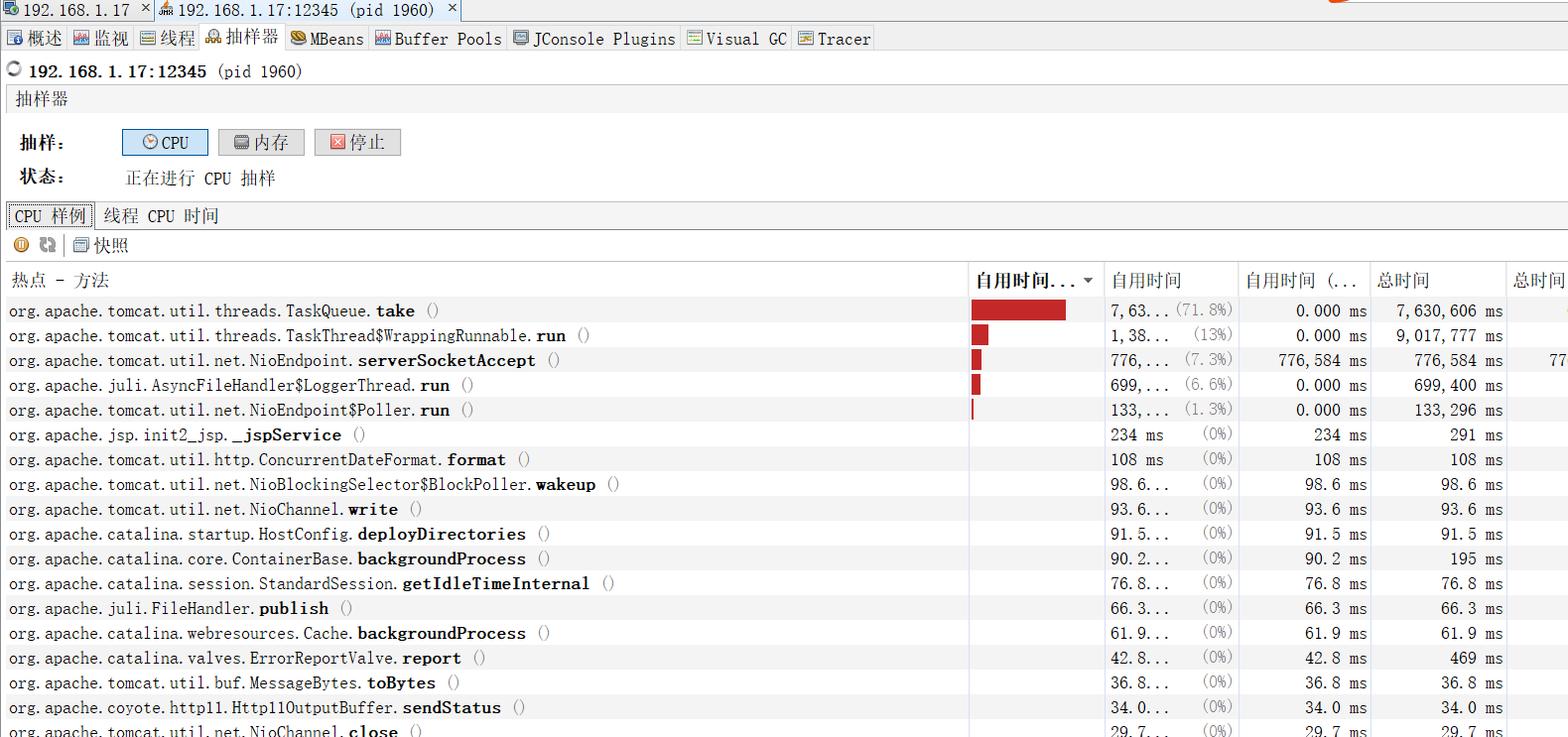
2、cpu抽样
cpu样例是 方法维度的
线程cpu时间是 线程维度的
线程cpu看8080.exec线程的就行了,这才是真正工作的线程。
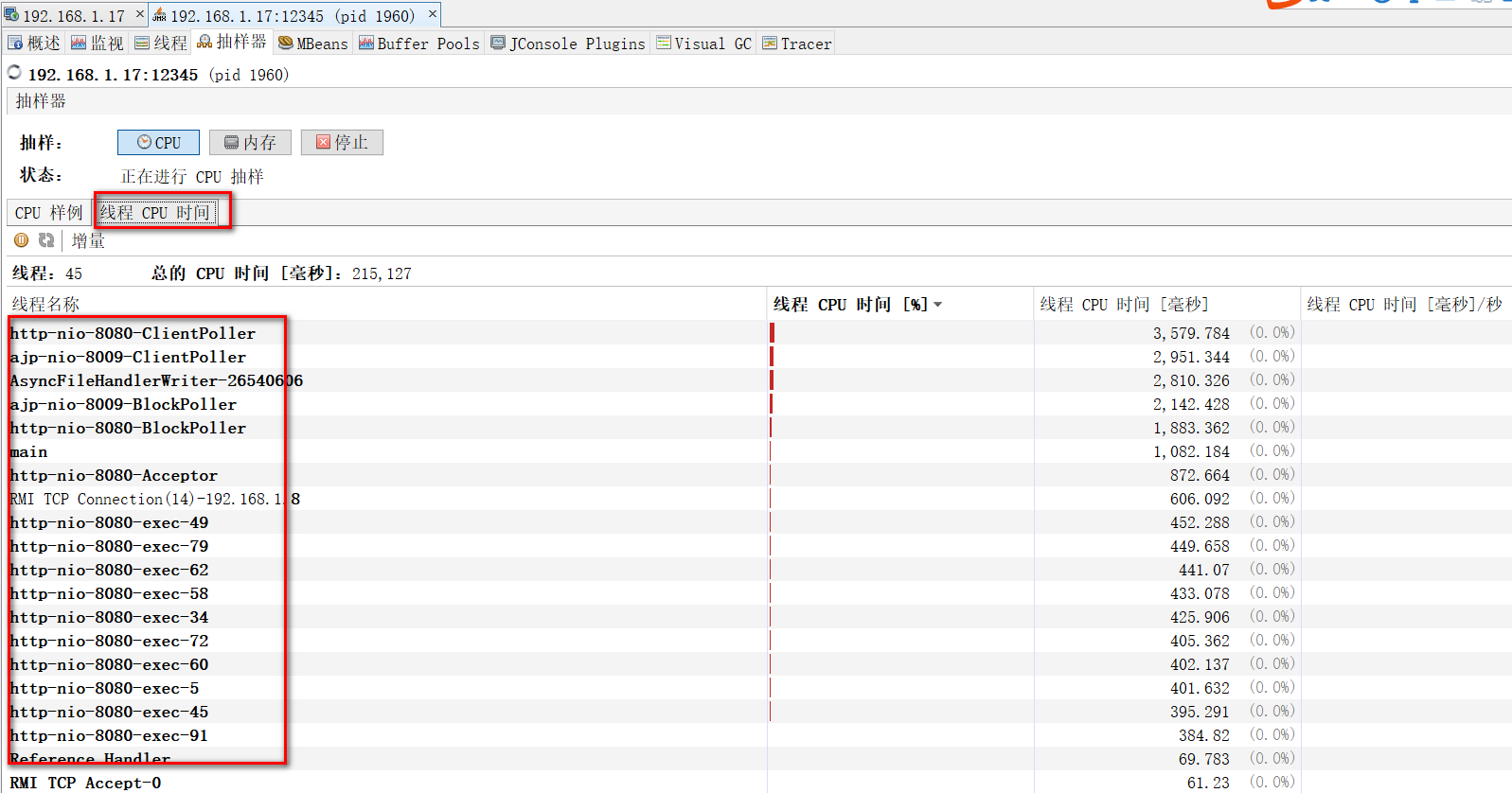
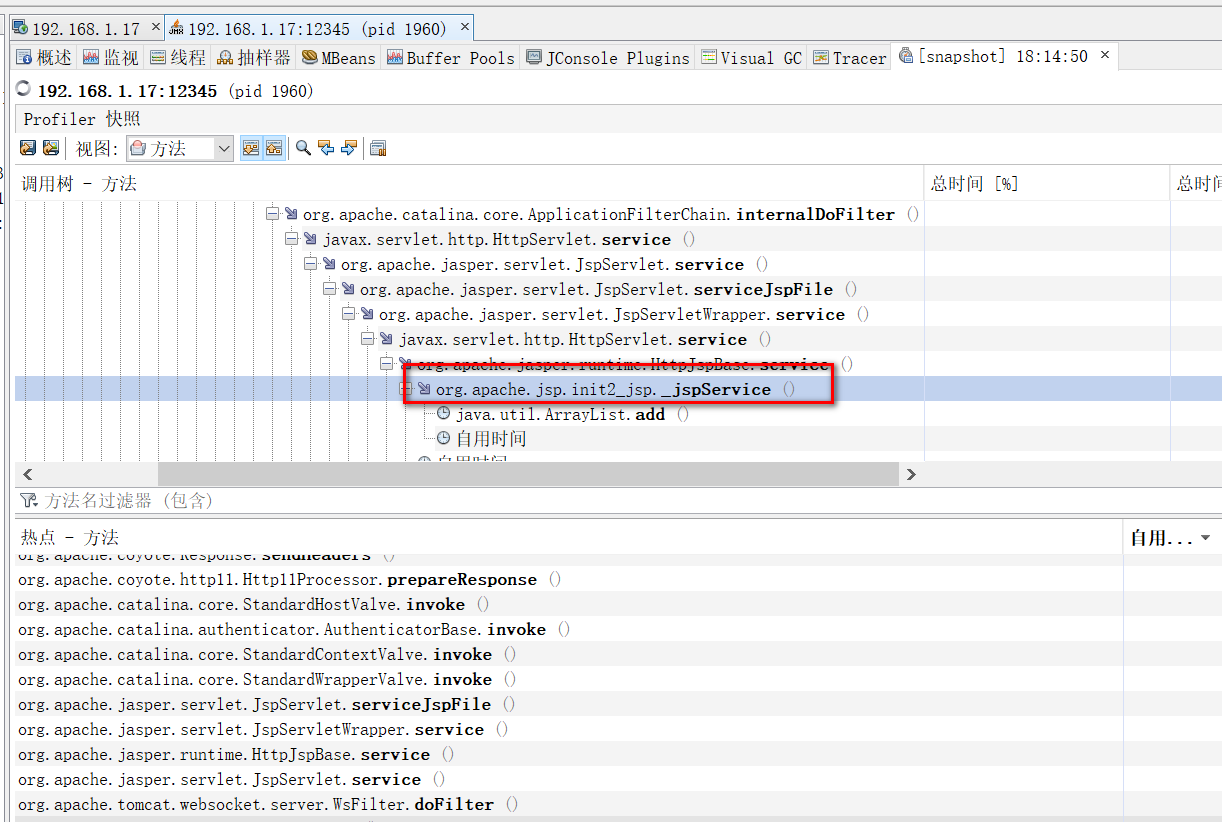
一段时间后,然后进行快照,快照保存后进行分析,看组合视图,并且按总时间(cpu)进行排序。

是init2.jsp的导致的cpu过高,好的时候,可以快照到init2.jsp下的add list方法的问题。
3、内存抽样
可以看到TestBean这个类占用的内存比较多。

java mem = max mem+direct mem + meta mem
遇到问题:java程序,有次压测,系统响应很慢,但是top查看 cpu、负载都很正常,排除cpu问题
然后看jvm内存问题,jstat 看堆的情况,也没有频繁的full-gc,奇怪了,什么问题呢?
cpu、内存都没问题,难道是磁盘导致的??
看磁盘队列,使用比率,pidstat等看io的命令,也很正常。
有点问题,压着压着,系统响应很慢,问题还是在操作系统层级。看操作系统内存资源,
free内存在减小,swap交换空间内存开始上升(堆内存不会大于java内存和堆外内存的)
这里是一个16G的机器,堆内存配了8个G,持久带配了0.5G,总共才8.5个G,怎么会内存占没了呢??
看系统进程谁消耗最多内存呢? top 按内存排序,或者pidstat
还是java占最多,其他没有占很多,看RES组成超过了8.5G,这里还有个direct mem,这里不设置,会和堆内存一样大都为8.5个G,也会慢慢增大。
这里要么别用,要么指定大小,也是JVM里配置。
三、jpfiler
添加一个远程连接,如何配置见以前的博客。


到监控页面后,选择live memory,然后标记Mark (相当于增量),然后访问几次下面的init2.jsp页面,可以看到如下图褐色的增量。
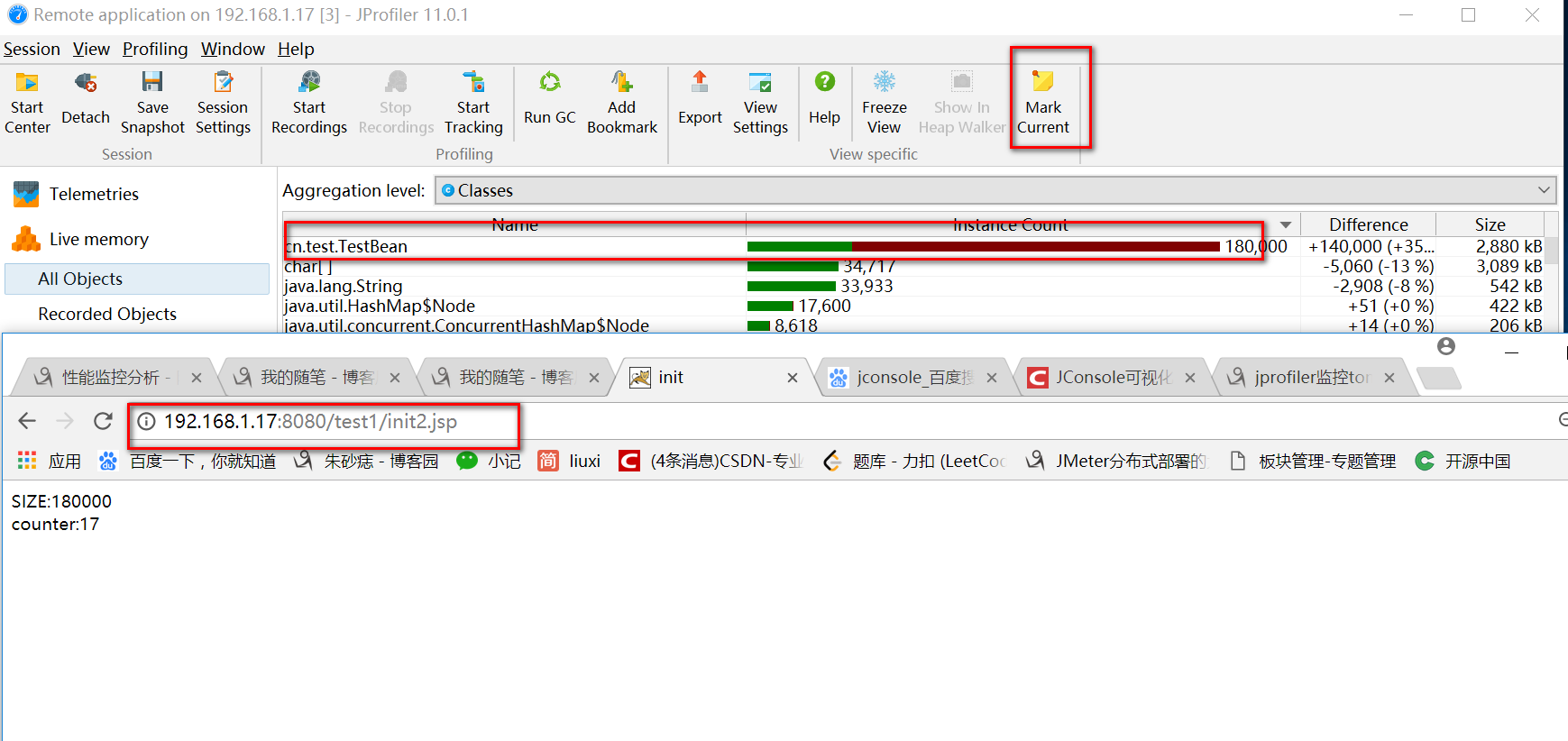
这里内存一直增加并且经过gc之后,没有减少,分析这可能就是这个对象造成内存溢出的原因。
如何分析???
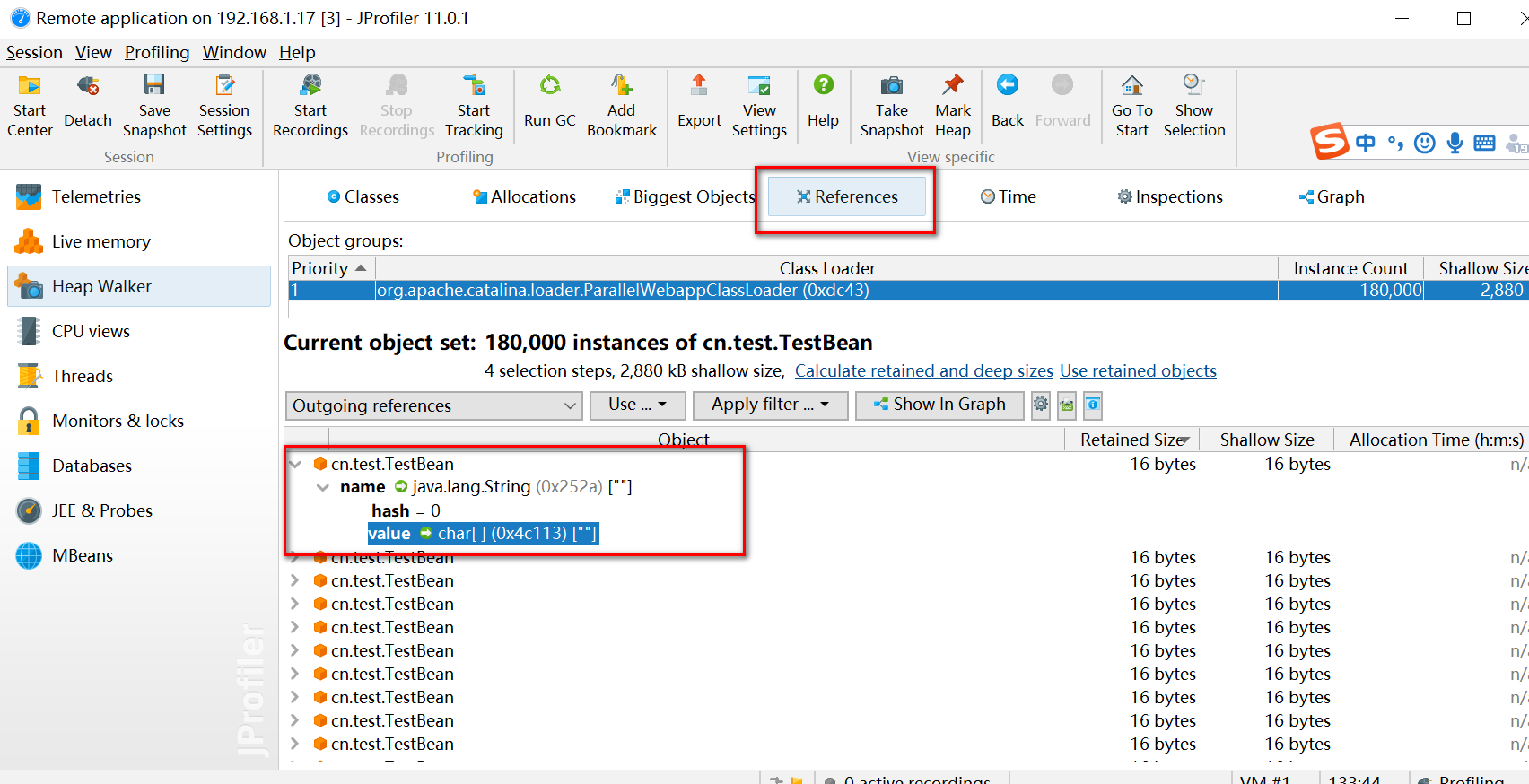
这里选中这个对象放到heap worker里面进行分析。
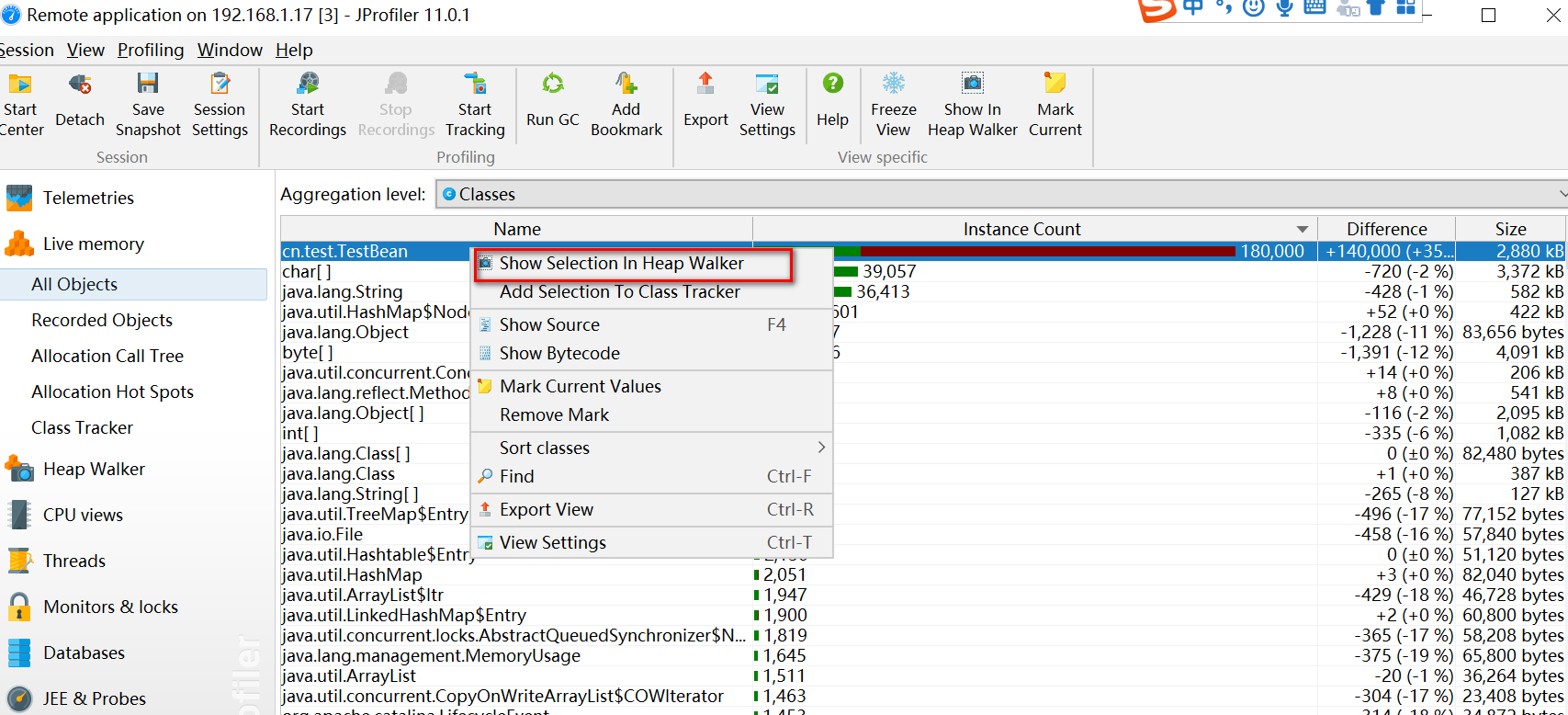
heap worker页面,references 视图看引用关系,biggest objects看大对象,一般就看这两个视图,优先看大对象。
分析cpu,基本就堆和cpu(栈)就好了。
问题:压测的时候要把cpu打满,和cpu太高要进行分析,这是矛盾的?
如果一个线程消耗很多则说明这个线程是有问题的,如果每个线程的使用cpu都差不多的情况,则证明cpu使用的是正常的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号