监督学习
监督学习
参考吴恩达2022MachineLearning视频教程
视频教程:(强推|双字)2022吴恩达机器学习Deeplearning.ai课程
机器学习分类
监督学习和无监督学习
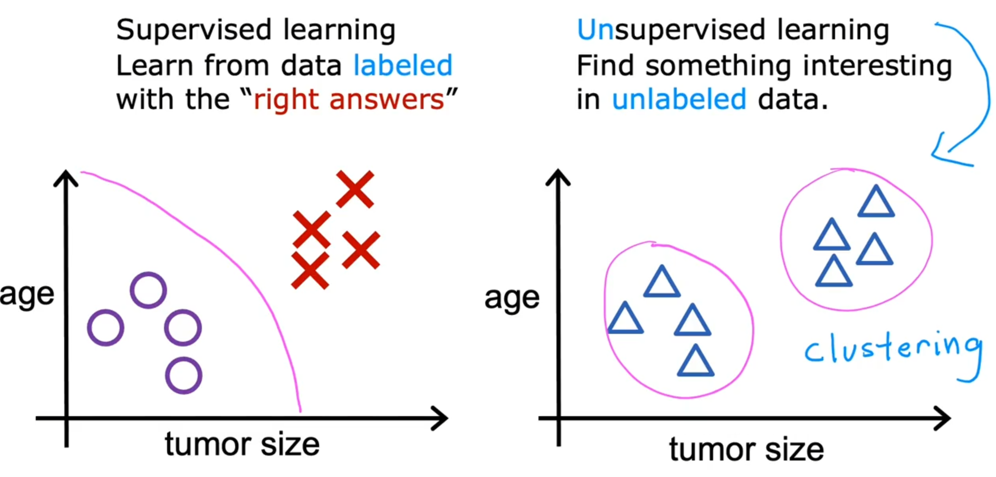
监督学习:回归、分类

无监督学习:聚集、异常检测、降维

回归问题
利用大量的样本,通过有监督的学习,学习到由x到y的映射f,利用该映射关系对未知的数据进行预估,其中y为连续值
1.线性回归
常用符号说明:

拟合函数:
利用一个线性函数去拟合数据:
\[ f_{w, b}(x) = wx +b ,其中w,b为参数 \]损失函数(loss function)
利用最小二乘法(最小平方法)计算其损失函数为:
\[ L(w,b) =\frac{1}{2} (\hat{y} - y)^2 = \frac{1}{2} (f_{w, b}(x) - y)^2 \]代价函数(cost function)
代价函数是所有样本误差总和(所有损失函数总和)的平均值:
\[ J(w,b) = \frac{1}{2m} \sum_{i=1}^m(f_{w, b}(x^{(i)}) - y^{(i)})^2 \]
拟合的目标就是找到合适的$w,b$参数能够使得代价函数最小,即$\hat$与$y$最接近
(批量)梯度下降算法
可以使用梯度下降算法来更新$w,b$参数,从而找到最合适的值:
\[ \left\{ \begin{matrix} w=w-\alpha \frac{\partial}{\partial w} J(w, b) \\ b=b-\alpha \frac{\partial}{\partial b} J(w, b) \end{matrix}\right. ,其中\alpha 是学习率,\partial表示偏导数 \]
将代价函数代入进去即可得到:
\[ \left\{ \begin{matrix} w= w-\alpha\frac{1}{m}\sum\limits_{i=1}^m (f_{w, b}(x^{(i)}) - y^{(i)})x^{(i)}\\ b= b-\alpha \frac{1}{m}\sum\limits_{i=1}^m (f_{w, b}(x^{(i)}) - y^{(i)}) \end{matrix}\right. ,其中\alpha 是学习率 \]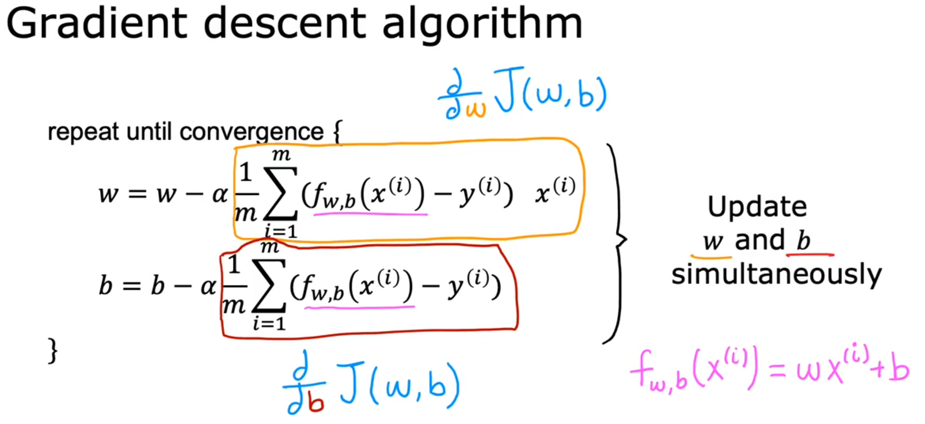
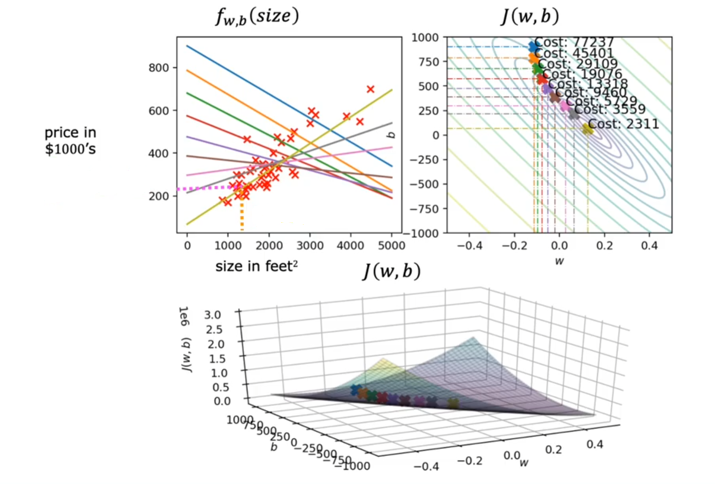
运行梯度下降算法:
2.多元线性回归
拟合函数:
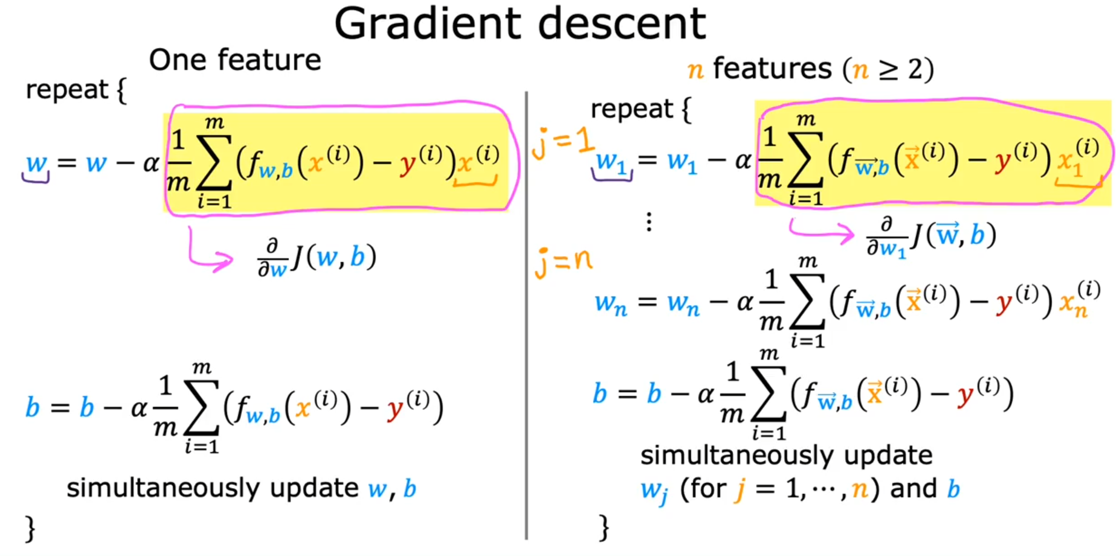
当数据集中有多个特征$x_{1},x_{2},...x_$时:
\[ f_{w_1,w_2,...,b}(x_1,x_2...) = w_{1}x_{1} +w_{2}x_{2} + ... +w_{n}x_{n} +b ,其中w_{1},w_{2},...,b为参数 \]向量化
将参数$w$和特征$x$进行向量化:
\[ f_{\vec{w}, b}(\vec{x}) = \vec{w}\vec{x}+b ,其中\vec{w},b为参数, \]梯度下降算法:
原来的公式变为:
\[ \left\{ \begin{matrix} w_1= w_1-\alpha\frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)})x_1^{(i)}\\ …… \\ w_n= w_n-\alpha\frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)})x_n^{(i)}\\ b= b-\alpha \frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)}) \end{matrix}\right. ,其中\alpha 是学习率 \]
3.多项式回归
特征工程
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性,直接决定了模型预测的结果好坏。俗话说就是对已有的特征进行预处理,比如已知房子的长和宽,此时可以增加房子的面积作为其新的特征,然后对模型进行预测。
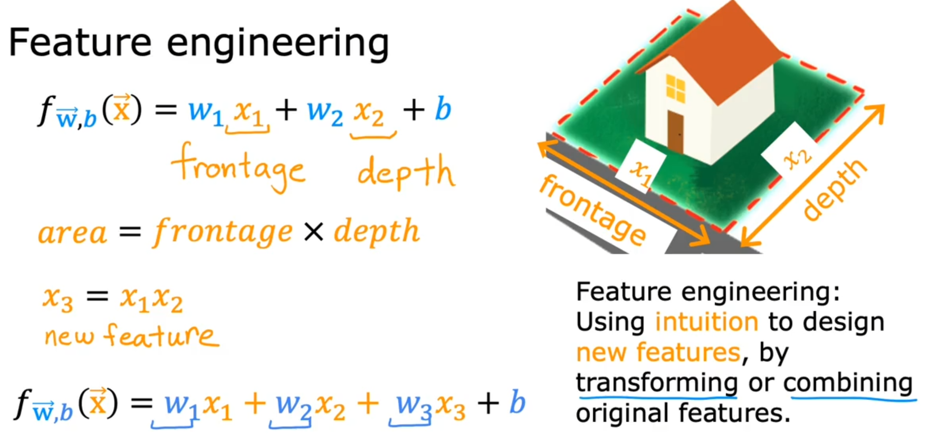
多项式回归
根据所给的特征,利用该特征对数据进行预处理,拟合函数为原特征的多项式类型。
比如原始特征为$x$,拟合函数为$f_{\vec,b}=w_1x+w_2x2+w_3x3+b$
分类问题
利用大量的样本,通过有监督的学习找到一个决策边界来完成分类的决策,其中决策为离散值
逻辑回归
线性回归可以预测连续值,但是不能解决分类问题,我们需要根据预测的结果判定其属于正类还是负类。所以逻辑回归就是将线性回归的$(-\infty,+\infty)$结果,通过$sigmoid$函数映射到$(0,1)$之间,来作为该结果的概率。
线性回归:\(z=\vec{w}\vec{x}+b\)
将其通过$g(x)= sigmoid$函数,获得逻辑回归的决策函数:
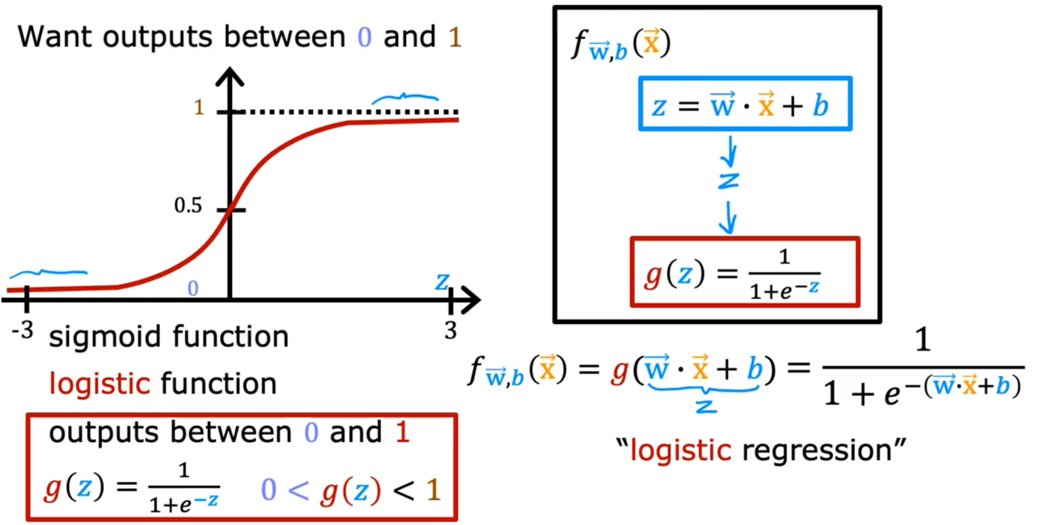
极大似然估计
极大似然估计是数理统计中参数估计的一种重要方法。其思想就是一个事件发生了,那么发生这个事件的概率就是最大的。对于样本$i$,其类别为$y_\epsilon (0,1)$。对于样本$i$,可以把$h(\mathbf_i)\(看成是一种`概率`:\)\mathbf_i$对应是1时,概率是$h(\mathbf_i)\(,即\)\mathbf_i$属于1的可能性;$\mathbf_i$对应是0时,概率是$1-h(\mathbf_i)\(,即\)\mathbf_i$属于0的可能性 。那么它构造极大似然函数:
\[ \prod_{i=1}^{i=k} h\left(\mathbf{x}_{i}\right) \prod_{i=k+1}^{m}\left(1-h\left(\mathbf{x}_{i}\right)\right) \\ 其中i从0到k是属于类别1的个数k,i从k+1到m是属于类别0的个数m-k。 \]由于$y_i$是标签0或1,所以上面的式子也可以写成:
\[ \prod_{i=1}^{m} h\left(\mathbf{x}_{i}\right)^{y_{i}}\left(1-h\left(\mathbf{x}_{i}\right)\right)^{1-y_{i}} \]这样无论$y$是0还是1,其中始终有一项会变成0方,也就是1,和第一个式子是等价的。
为了方便,我们对式子取对数。因为是求概率最大,即式子的最大值,可以转换成式子乘以-1,之后求最小值。同时对于$m$个数据,累加后值会很大,之后如果用梯度下降容易导致梯度爆炸,所以可以除以样本总数$m$,式子变为:
\[ \frac{1}{m} \sum_{i=1}^{n}-y_{i} \ln \left(h\left(\mathbf{x}_{i}\right)\right)-\left(1-y_{i}\right) \ln \left(1-h\left(\mathbf{x}_{i}\right)\right) \]代价函数
可以根据上面的最大似然估计定义逻辑回归的代价函数:
\[ J(\vec{w},b) =-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \ln \left(f_{\vec{w}, b}\left(\vec{x}^{(i)}\right)\right)+\left(1-y^{(i)}\right) \ln \left(1-f_{\vec{w}, b}(\vec{x}^{(i)})\right)\right] \]
梯度下降算法
此处涉及数学求导,可以跳过
已知代价函数,梯度下降的目标就是找到合适的$\vec,b$参数能够使得代价函数最小,即使得预测结果的概率最大。根据梯度下降算法的流程,我们需要对代价函数做导数运算:
\[ \begin{array}{l} \frac{\partial J(\vec{w},b)}{w_j}=- \frac{1}{m} \sum \limits_{i=1}^{m}[{y}^{(i)} \frac{1}{g(z)}-(1-y^{(i)}) \frac{1}{1-g(z)}] \frac{\partial g(z)}{\partial w_j} \\ =- \frac{1}{m} \sum \limits_{i=1}^{m}[y^{(i)} \frac{1}{g(z)}-(1-y^{(i)}) \frac{1}{1-g(z)}] \cdot g(z)(1-g(z)) \cdot \frac{\partial z}{\partial {w}_{j}} \\ =- \frac{1}{m} \sum \limits_{i=1}^{m}[y^{(i)}(1-g(z))-(1-y^{(i)}) g(z)] \cdot x_j^{(i)} \\ =- \frac{1}{m} \sum \limits_{i=1}^{m}(y^{(i)}-g(z)) \cdot x_j^{(i)} \\ =\frac{1}{m} \sum \limits_{i=1}^{m}(g(z)-y^{(i)}) \cdot x_j^{(i)} \\ =\frac{1}{m} \sum \limits_{i=1}^{m}[f_{\vec{w}, b}(\vec{x}^{(i)})-y^{(i)}] \cdot x_j^{(i)} \end{array} \]其中$\frac{\partial g(z)}{\partial w_j}$的计算如下:
\[ \frac{\partial g(z)}{\partial w_j} =\frac{\partial \frac{1}{1+e^{-z}}}{\partial w_j} = - \frac{1}{(1+e^{-z)^2}} \cdot e^{-z} \cdot (-1) \cdot \frac{\partial z}{\partial {w}_{j}} = g(z)(1-g(z)) \cdot \frac{\partial z}{\partial {w}_{j}} \]然后进行梯度下降:
\[ \left\{ \begin{matrix} w_1= w_1-\alpha\frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)})x_1^{(i)}\\ …… \\ w_n= w_n-\alpha\frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)})x_n^{(i)}\\ b= b-\alpha \frac{1}{m}\sum\limits_{i=1}^m (f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)}) \end{matrix}\right. ,其中\alpha 是学习率 \]可以发现其形式竟然和线性回归的形式一样,不过这里的$f_{\vec, b}(\vec^{(i)})$和线性回归的已经
不一样了。
数据处理
特征缩放(归一化)
可以通过变换来将各个特征统一到一个合适的范围内,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解:
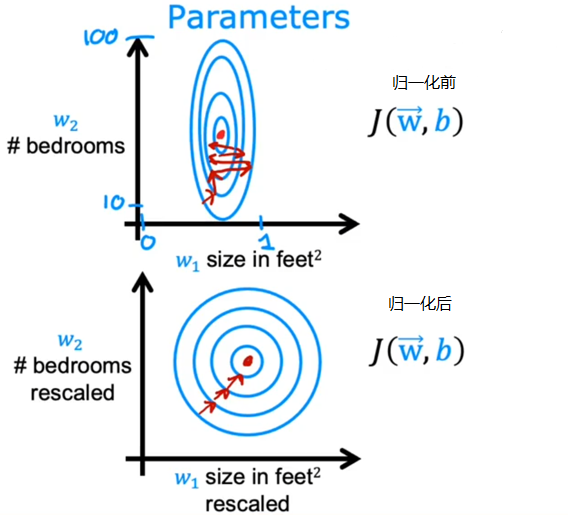
极差变换:
- 归一到$(0,1)$范围:
\[ x_{i}^{\prime}=\frac{x_{i}-\min (x)}{\max (x)-\min (x)} \]- 归一到$(-1,1)$范围:
\[ x_{i}^{\prime}=\frac{x_{i}-mean (x)}{\max (x)-\min (x)} \\ mean(x)为平均值 \]标准差变换(Z-score):
\[ x_{i}^{\prime}=\frac{x_{i}-μ}{\sigma} \\ μ为所有样本数据的均值,σ为所有样本数据的标准差 \]
过拟合和欠拟合
Overfitting : If we have too many features, the learned hypothesis may fit the training set vey well, but fail to generalize to new examples.
过拟合其实就是为了得到一致假设而使得假设过于地严格。使得其在训练集上的表现非常地完美,但是在训练集以外的数据集却表现不好。
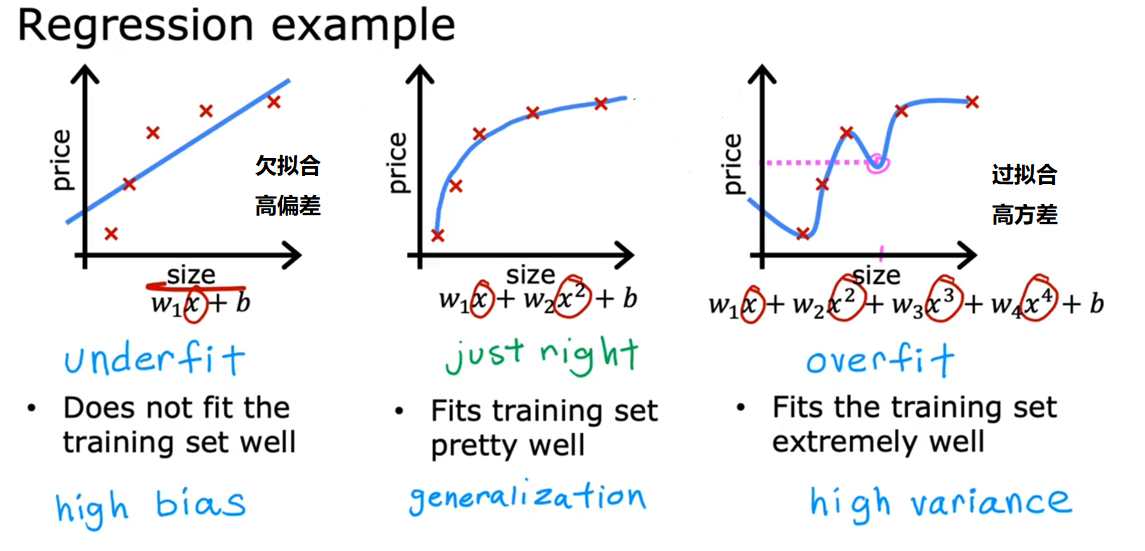
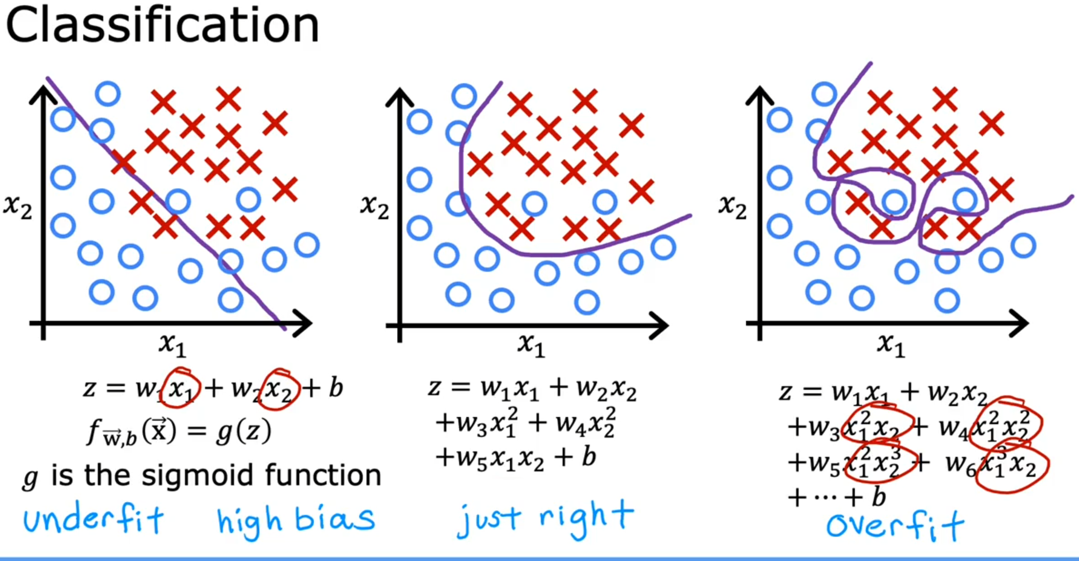
解决过拟合的方法:
收集更多的数据
减少特征值的数量:
- 人工选择哪些特征需要保留
- 使用模型选择算法
正则化
正则化
在原来的代价函数中添加
正则化项,主要是通过正则项来限制权重$w$参数的值的变化,使其尽可能的小或者尽可能地趋于0,以达到稀疏参数的效果,进而使得模型复杂度下降,避免过拟合(一般不对参数$b$进行正则化)。线性回归
\[ J(\vec{w},b) = \frac{1}{2m} \sum_{i=1}^m(f_{\vec{w}, b}(\vec{x}^{(i)}) - y^{(i)})^2 + \frac{\lambda}{2 m} \sum_{j=1}^{n} w_{j}^{2} \\ ,\lambda为正则化系数 \]逻辑回归
\[ J(\vec{w},b) =-\frac{1}{m} \sum_{i=1}^{m}\left[y^{(i)} \ln \left(f_{\vec{w}, b}\left(\vec{x}^{(i)}\right)\right)+\left(1-y^{(i)}\right) \ln \left(1-f_{\vec{w}, b}(\vec{x}^{(i)})\right)\right]+\frac{\lambda}{2 m} \sum_{j=1}^{n} w_{j}^{2} \]
正则化后的的梯度下降算法:

其中对于参数w的那一项还可以写成:
原来$w$前系数为1,现在$w$前面系数为 ,因为$\alpha、\lambda、m$都是正的,所以 $1-\alpha\frac{\lambda}$小于1,它的效果是减小$w$,这也就是权重衰减的由来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号