

Pulsar 安装及消息特性基础
Pulsar 是一个用于服务器到服务器的消息系统,具有多租户、高性能等优势。 Pulsar 最初由 Yahoo 开发,目前由 Apache 软件基金会管理。
Pulsar 的关键特性如下:
- Pulsar 的单个实例原生支持多个集群,可跨机房在集群间无缝地完成消息复制。
- 极低的发布延迟和端到端延迟。
- 可无缝扩展到超过一百万个 topic。
- 简单的客户端 API,支持 Java、Go、Python 和 C++。
- 支持多种 topic 订阅模式(独占订阅、共享订阅、故障转移订阅)。
- 通过 Apache BookKeeper 提供的持久化消息存储机制保证消息传递 。
- 由轻量级的 serverless 计算框架 Pulsar Functions 实现流原生的数据处理。
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得数据更易移入、移出 Apache Pulsar。
- 分层式存储可在数据陈旧时,将数据从热存储卸载到冷/长期存储(如S3、GCS)中。
By default, Pulsar allocates 2G JVM heap memory to start. It can be changed in conf/pulsar_env.sh file under PULSAR_MEM. This is extra options passed into JVM.
# PULSAR_MEM=${PULSAR_MEM:-"-Xms2g -Xmx2g -XX:MaxDirectMemorySize=4g"}
PULSAR_MEM=${PULSAR_MEM:-"-Xms512m -Xmx512m -XX:MaxDirectMemorySize=1g"}
单机启动:bin/pulsar standalone 。pulsar-daemon start/stop standalone: 后台运行的standalone服务模式
在 logs 目录下会出现一个 pulsar-standalone-m.log 日志,查看一下 看到如下信息说明服务启动成功。

控制台启动发布订阅,bin/pulsar-client consume my-topic -s "first-subscription"
如果消息成功发送到 topic,则会在 pulsar-client 日志中出现一个确认,如下所示:

bin/pulsar-client produce my-topic --messages "hello-pulsar"
如果消息成功发送到 topic,则会在 pulsar-client 日志中出现一个确认,如下所示:

消息是 Pulsar 的基础“单元”。消息的缺省大小为5mb。您可以通过以下配置来配置消息的最大大小。
//在 broker.conf 文件中
maxMessageSize=5242880
//在 bookkeeper.conf 配置文件中
nettyMaxFrameSizeBytes=5253120
Java API:
Producer 可以以同步(sync) 或 异步(async) 的方式发布消息到 broker。Comsumer 可以通过同步(sync) 或者异步(async)的方式接受消息。下面演示简单的生产消费demo:
消费者:
public class PulsarSimpleConsumer extends Thread {
private Consumer consumer;
public PulsarSimpleConsumer() {
try {
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://192.168.1.101:6650")
.build();
consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.subscribe();
// consumer = client.newConsumer()
// .topic("my-topic")
// .messageListener(new MessageListener<byte[]>() {
// @Override
// public void received(Consumer<byte[]> consumer, Message<byte[]> message) {
// System.out.printf("Message received MessageListener: %s", new String(message.getData()));
// try {
// consumer.acknowledge(message);
// } catch (PulsarClientException e) {
// e.printStackTrace();
// }
// }
// })
// .subscriptionName("my-subscription")
// .subscribe();
} catch (PulsarClientException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
PulsarSimpleConsumer pulsarConsumer = new PulsarSimpleConsumer();
pulsarConsumer.start();
}
@Override
public void run() {
while (true) {
Message msg = null;
try {
// Wait for a message
msg = consumer.receive();
System.out.printf("Message received: %s", new String(msg.getData()));
// Acknowledge the message so that it can be deleted by the message broker
consumer.acknowledge(msg);
} catch (Exception e) {
// Message failed to process, redeliver later
consumer.negativeAcknowledge(msg);
}
}
}
}
生产者:
public class PulsarSimpleProducer {
public static void main(String[] args) {
Producer<byte[]> producer = null;
try {
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://192.168.1.101:6650")
.build();
producer = client.newProducer()
.topic("my-topic")
.blockIfQueueFull(true) // 发送模式
.create();
// 然后你就可以发送消息到指定的broker 和topic上:
producer.send("My message".getBytes());
//异步发送
// producer.sendAsync("my-async-message".getBytes()).thenAccept(msgId -> {
// System.out.printf("Message with ID %s successfully sent", msgId);
// });
client.close();
} catch (PulsarClientException e) {
e.printStackTrace();
} finally {
producer.closeAsync().thenRun(() -> {
System.out.println("Producer closed");
});
}
}
}
Access mode:
访问模式分为 Shared(默认),Exclusive。当设置为 Exclusive ,是不允许同时有多个生产者向该topic 发送消息,否则将抛出以下异常:

消息压缩:
您可以压缩在传输期间由生产者发布的消息。目前支持以下几种压缩方式:
批量处理:
启用批处理后,生产者将在单个请求中累积并发送一批消息。 批处理大小由最大消息数和最大发布延迟定义。 因此,待办事项的大小表示批处理的总数而不是消息的总数。在Pulsar中,批次被跟踪存储存储不是以单条信息为单位,而是以batch为单位。消费者会将batch的数据拆分成一条一条的数据。然而,调度信息无论是否配置了batch总是以一条一条进行发送的。通常情况下,只有所有消息都被consumer 发送ack了,这个batch才会被ack。这就意味着,非预期的失败、超时或者否定ack 都会导致整个批次信息的重传。
为了避免将已确认的消息批量分发给使用者,自Pulsar 2.6.0起,Pulsar引入了批处理索引确认。 启用批处理索引确认后,使用者将筛选出已确认的批处理索引,并将批处理索引确认请求发送给Broker。 Broker维护批次索引确认状态,并跟踪每个批次索引的确认状态,以避免将已确认的消息发送给使用者。 确认批处理消息的所有索引后,该批处理消息将被删除。默认情况下批处理索引确认功能是关闭的(batchIndexAcknowledgeEnable=false)。可以在broker上通过设置这个配置打开这个功能。启用批处理索引确认会导致更多的内存开销
producer = client.newProducer() .topic("my-topic") .blockIfQueueFull(true) // 发送模式 //是否开启批量处理消息,默认true,需要注意的是enableBatching只在异步发送sendAsync生效, // 同步发送send失效。因此建议生产环境若想使用批处理,则需使用异步发送,或者多线程同步发送 .enableBatching(true) //设置将对发送的消息进行批处理的时间段,10ms; // 可以理解为若该时间段内批处理成功,则一个batch中的消息数量不会被该参数所影响。 .batchingMaxPublishDelay(10, TimeUnit.MILLISECONDS) .batchingMaxMessages(1000)//批处理中允许的最大消息数。默认1000 .create();
分块:
当你想要启用分块(chunking) 时,请阅读以下说明。enableChunking(true)
- Batching and chunking cannot be enabled simultaneously. 如果想要启用分块(chunking) ,您必须提前禁用批量处理。
- Chunking is only supported for persisted topics.
- Chunking is only supported for the exclusive and failover subscription modes.
当启用分块(chunking) 时(chunkingEnabled=true) ,如果消息大小大于允许的最大发布有效载荷大小,则 producer 将原始消息分割成分块的消息,并将它们与块状的元数据一起单独和按顺序发布到 broker。 在 broker 中,分块的消息将和普通的消息以相同的方式存储在 Managed Ledger 上。 唯一的区别是,consumer 需要缓冲分块消息,并在收集完所有分块消息后将其合并成真正的消息。 Managed Ledger 上的分块消息可以和普通消息交织在一起。 如果 producer 未能发布消息的所有分块,则当 consumer 未能在过期时间(expire time) 内接收所有分块时,consumer 可以过期未完成的分块。 默认情况下,过期时间设置为1小时。
Consumer 会缓存收到的块状消息,直到收到消息的所有分块为止。 然后 consumer 将分块的消息拼接在一起,并将它们放入接收器队列中。 客户端从接收器队列中消费消息。 一旦 consumer 使用整个大消息并确认,consumer 就会在内部发送与该大消息关联的所有分块消息的确认。 You can set the maxPendingChunkedMessage parameter on the consumer. 当达到阈值时,consumer 通过静默确认未分块的消息或通过将其标记为未确认,要求 broker 稍后重新发送这些消息。
broker 不需要任何更改来支持非共享订阅的分块。broker 只使用chunkedMessageRate来记录主题上的分块消息速率。
处理一个 producer 和一个订阅 consumer 的分块消息
如下图所示,当生产者向主题发送一批大的分块消息和普通的非分块消息时。 假设生产者发送的消息为 M1,M1 有三个分块 M1-C1,M1-C2 和 M1-C3。 这个 broker 在其管理的ledger里面保存所有的三个块消息,然后以相同的顺序分发给消费者(独占/灾备模式)。 消费者将在内存缓存所有的块消息,直到收到所有的消息块。将这些消息合并成为原始的消息M1,发送给处理进程。

多个生产者和一个生产者处理块消息。
当多个生产者发布块消息到单个主题,这个 Broker 在同一个 Ledger 里面保存来自不同生产者的所有块消息。 如下所示,生产者1发布的消息 M1,M1 由 M1-C1, M1-C2 和 M1-C3 三个块组成。 生产者2发布的消息 M2,M2 由 M2-C1, M2-C2 和 M2-C3 三个块组成。 这些特定消息的所有分块是顺序排列的,但是其在 ledger 里面可能不是连续的。 这种方式会给消费者带来一定的内存负担。因为消费者会为每个大消息在内存开辟一块缓冲区,以便将所有的块消息合并为原始的大消息。
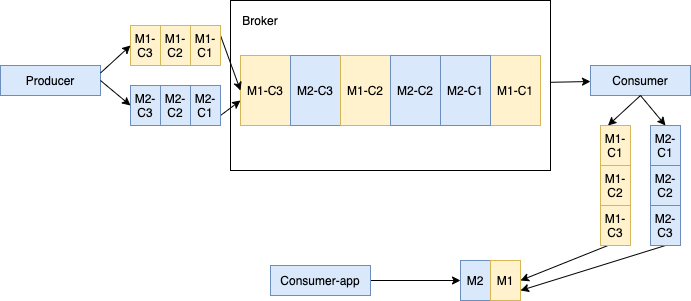
消息确认:
当消费者成功的消费了一条消息,这个消费者会发送一个确认信息给broker。 这个消息时是永久保存的,只有在收到订阅者消费成功的消息确认后才会被删除。 如果希望消息被 Consumer 确认后仍然保留下来,可配置 消息保留策略实现。
当某一批消息的所有索引都被确认时,该批消息将被删除。
消息有两种确认模式:单条确认或者累计确认。 累积确认时,消费者只需要确认最后一条他收到的消息。 所有之前(包含此条)的消息,都不会被再次重发给那个消费者。
消息可以通过以下两种方式被确认:
- 消息是单独确认的。对于单独的确认,使用者需要确认每条消息并向代理发送确认请求。
- 累积确认模式:累积确认时,消费者只需要确认最后一条他收到的消息。 所有之前(包含此条)的消息,都不会被再次发送给那个消费者。
在共享订阅模式,消息都是单条确认模式。
消息取消确认
当消费者在某个时间没有成功的消费某条消息,消费者想重新消费到这条消息,这个消费者可以发送一条取消确认消息到 broker,broker 会将这条消息重新发给消费者。
消息取消确认也有单条取消模式和累积取消模式 ,这依赖于消费者使用的订阅模式。
在独占消费模式和灾备订阅模式中,消费者仅仅只能对收到的最后一条消息进行取消确认。
消息确认超时
如果消息没有被成功消费,你想去让 broker 自动重新交付这个消息, 你可以采用未确认消息自动重新交付机制。 客户端会跟踪 超时 时间范围内所有未确认的消息。 并且在指定超时时间后会发送一个 重发未确认的消息 请求到 broker。
注意:如果启用了批处理,则同一批处理中的其他消息和未确认消息将被重新交付给使用者。
死信主题:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.deadLetterTopic("your-topic-name")
.build())
.subscribe();
Retry letter topic
很多在线的业务系统,由于业务逻辑处理出现异常,消息一般需要被重新消费。 若需要允许延时重新消费失败的消息,你可以配置生产者同时发送消息到业务主题和重试主题,并允许消费者自动重试消费。 配置了允许消费者自动重试。如果消息没有被消费成功,它将被保存到重试主题当中。并在指定延时时间后,自动重新消费重试主题里面的消费失败消息。
缺省情况下,禁用自动重试功能。您可以将enableRetry设置为true,以在使用者上启用自动重试。
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.enableRetry(true)
.receiverQueueSize(100)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.retryLetterTopic("persistent://my-property/my-ns/my-subscription-custom-Retry")
.build())
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.subscribe();
默认的情况下Topic的名称为符合良好结构的URL:
{persistent|non-persistent}://tenant/namespace/topic
命名空间:
命名空间是租户内部逻辑上的命名术语。 可以通过admin API在租户下创建多个命名空间。 例如,包含多个应用程序的租户可以为每个应用程序创建单独的命名空间。 Namespace使得程序可以以层级的方式创建和管理topic Topicmy-tenant/app1 ,它的namespace是app1这个应用,对应的租户是 my-tenant。 你可以在namespace下创建任意数量的topic。
订阅:
订阅是命名好的配置规则,指导消息如何投递给消费者。 Pulsar 中有四种订阅模式: 独占,共享,灾备和key共享 下图展示了这三种模式:
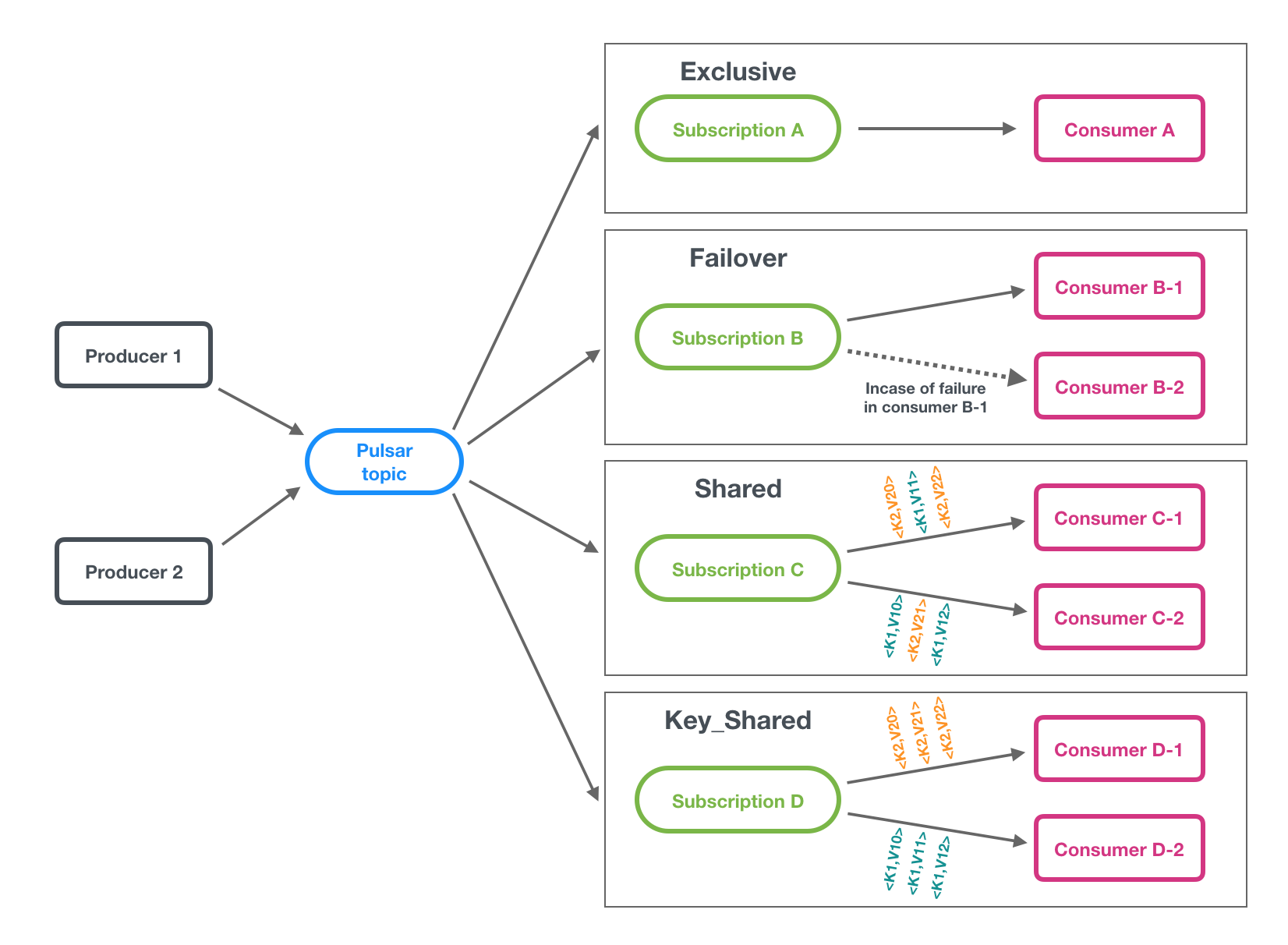
- Exclusive:Exclusive模式为默认订阅模式。
- Failover(灾备):在故障转移模式中,多个使用者可以附加到相同的订阅. 主消费者会消费非分区主题或者分区主题中的每个分区的消息。 当主使用者断开连接时,所有(非确认的和后续的)消息都被传递给下一个使用者。对于分区主题来说,Broker 将按照消费者的优先级和消费者名称的词汇表顺序对消费者进行排序。 然后试图将主题均匀的分配给优先级最高的消费者。对于非分区主题来说,broker 会根据消费者订阅非分区主题的顺序选择消费者。在下面的图中,Consumer-B-0是主消费者,而如果Consumer-B-0断开连接,Consumer-B-1将是下一个接收消息的消费者。
- Shared(共享):In shared or round robin mode, multiple consumers can attach to the same subscription. 消息通过round robin轮询机制分发给不同的消费者,并且每个消息仅会被分发给一个消费者。 当消费者断开连接,所有被发送给他,但没有被确认的消息将被重新安排,分发给其它存活的消费者。
- Key_Shared:在Key_Shared模式下,多个消费者可以附加到同一个订阅。消息以跨使用者的分发方式传递,具有相同键或相同排序键的消息只被传递给一个使用者。无论消息被重新交付多少次,它都被交付给相同的使用者。当使用者连接或断开时会导致服务使用者更改消息的某些键。可以在
broker.config中禁用 Key_Shared 模式。
多主题订阅:
当consumer订阅pulsar的主题时,它默认指定订阅了一个主题,例如:persistent://public/default/my-topic。 从Pulsar的1.23.0-incubating的版本开始,Pulsar消费者可以同时订阅多个topic。
当使用正则匹配订阅多个主题的时候,所有的主题必须是在同一个命名空间里面的。
PulsarClient pulsarClient = // Instantiate Pulsar client object
// Subscribe to all topics in a namespace
Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default/.*");
Consumer<byte[]> allTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(allTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
// Subscribe to a subsets of topics in a namespace, based on regex
Pattern someTopicsInNamespace = Pattern.compile("persistent://public/default/foo.*");
Consumer<byte[]> someTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(someTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
分区 topic:
普通的主题仅仅被保存在单个 broker中,这限制了主题的最大吞吐量。分区主题是由多个 broker 处理的特殊类型的主题,因此允许更高的吞吐量。分区主题实际是通过在底层拥有 N 个内部主题来实现的,这个 N 的数量就是等于分区的数量。 当向分区的topic发送消息,每条消息被路由到其中一个broker。 Pulsar自动处理跨broker的分区分布。下图对此做了阐明:
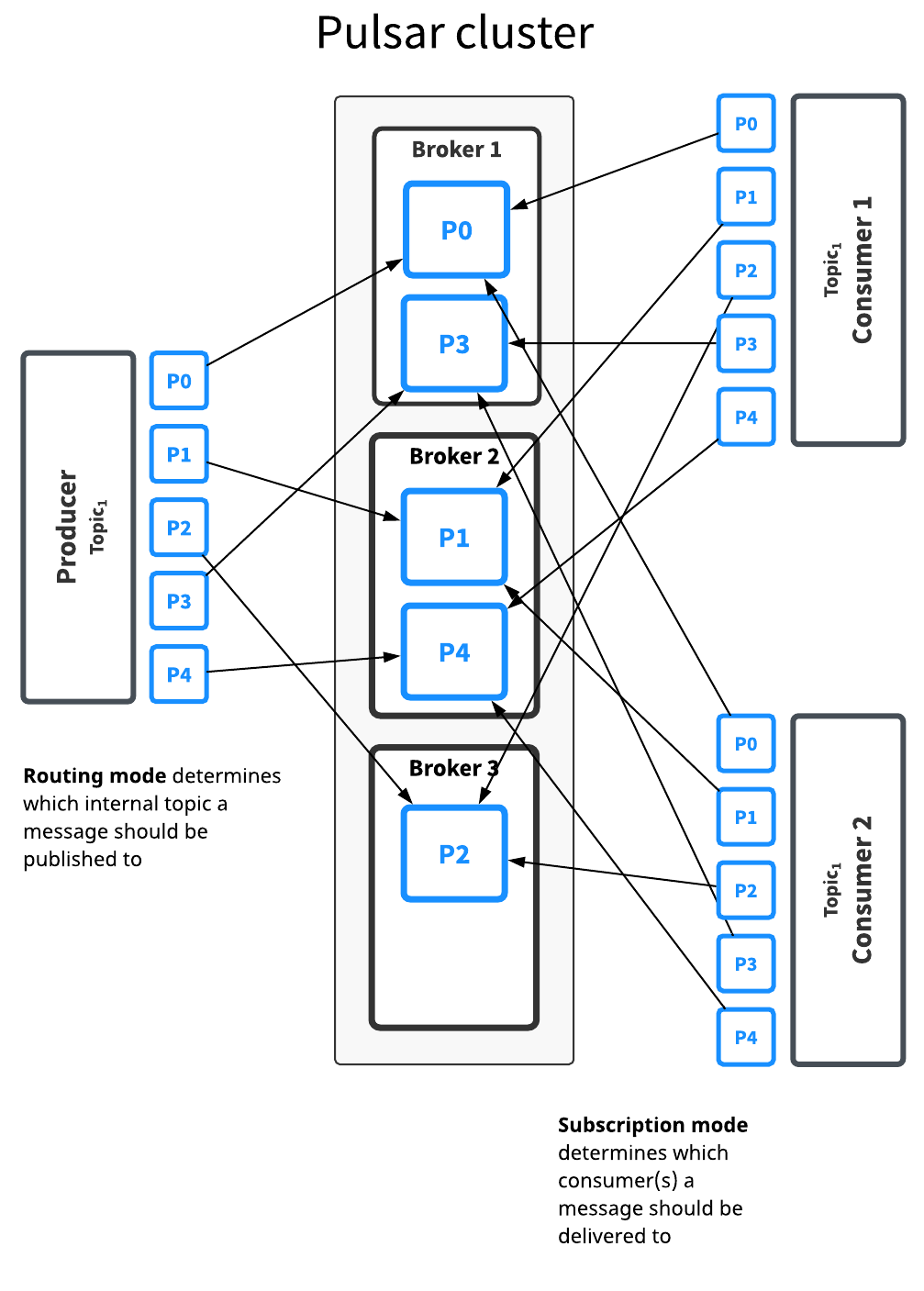
The Topic1 topic has five partitions (P0 through P4) split across three brokers. 因为分区多于broker数量,其中有两个broker要处理两个分区。第三个broker则只处理一个。(再次强调,分区的分布是Pulsar自动处理的)。这个topic的消息被广播给两个consumer。 路由模式确定每条消息该发往哪个分区,而订阅模式确定消息传递给哪个消费者。大多数境况下,路由和订阅模式可以分开制定。 通常来讲,吞吐能力的要求,决定了 分区/路由 的方式。订阅模式则应该由应用的语义来做决定。分区topic和普通topic,对于订阅模式如何工作,没有任何不同。分区只是决定了从生产者生产消息到消费者处理及确认消息过程中发生的事情。
路由模式:
当发布到分区主题时,必须指定路由模式。路由模式决定每条消息应该发布到哪个分区——即哪个内部主题
有三种 MessageRoutingMode 可用:
- RoundRobinPartition:如果消息没有指定 key,为了达到最大吞吐量,生产者会以 round-robin 方式将消息发布到所有分区。 请注意round-robin并不是作用于每条单独的消息,而是作用于延迟处理的批次边界,以确保批处理有效。 如果消息指定了key,分区生产者会根据key的hash值将该消息分配到对应的分区。 这是默认的模式。
- SinglePartition:如果消息没有指定 key,生产者将会随机选择一个分区,并发布所有消息到这个分区。 如果消息指定了key,分区生产者会根据key的hash值将该消息分配到对应的分区。
- CustomPartition:使用自定义消息路由器实现来决定特定消息的分区。 用户可以创建自定义路由模式:使用 Java client 并实现MessageRouter 接口。
顺序保证:
消息的顺序与MessageRoutingMode和Message Key相关。通常,用户希望每个键分区保证的顺序。
当使用 SinglePartition或者RoundRobinPartition模式时,如果消息有key,消息将会被路由到匹配的分区,这是基于ProducerBuilder 中HashingScheme 指定的散列shema。
- 按键分区:所有具有相同 key 的消息将按顺序排列并放置在相同的分区(Partition)中。使用
SinglePartition或RoundRobinPartition模式,每条消息都需要有key。 - 生产者排序:来自同一生产者的所有消息都是有序的路由策略为
SinglePartition, 且每条消息都没有key。
散列scheme:
HashingScheme 是代表一组标准散列函数的枚举。为一个指定消息选择分区时使用。
有两种可用的散列函数: JavaStringHash 和Murmur3_32Hash. The default hashing function for producer is JavaStringHash. 请注意,当producer可能来自于不同语言客户端时,JavaStringHash是不起作用的。建议使用Murmur3_32Hash。
非持久topic:
默认情况下,Pulsar将所有未确认的消息持久地存储在多个BookKeeper bookies (存储节点)上. 因此,持久性主题上的消息数据可以在 broker 重启和订阅者故障转移之后继续存在。不过,Pulsar也支持非持久主题,即消息永远不会持久化到磁盘上,而只存在于内存中. Pulsar也提供了非持久topic。非持久topic的消息不会被保存在硬盘上,只存活于内存中。当使用非持久topic分发时,杀掉Pulsar的broker或者关闭订阅者,此topic( non-persistent))上所有的瞬时消息都会丢失,意味着客户端可能会遇到消息缺失。非持久性主题具有这种形式的名称(注意名称中的 non-persistent):
非持久topic,消息数据仅存活在内存。 如果broker挂掉或者因其他情况不能从内存取到,你的消息数据就可能丢失。
默认非持久topic在broker上是开启的。 你可以通过broker的配置关闭。
消息保留和过期:
Pulsar broker默认如下:
- 立即删除所有已被消费者确认的消息
- 以消息backlog的形式,持久保存所有的未被确认消息
Pulsar有两个特性,让你可以覆盖上面的默认行为。
- 消息保留使您能够存储已被消费者确认的消息
- 消息过期使您能够为尚未得到确认的消息设置生存时间(TTL)
所有消息保留和过期都在名称空间级别进行管理。
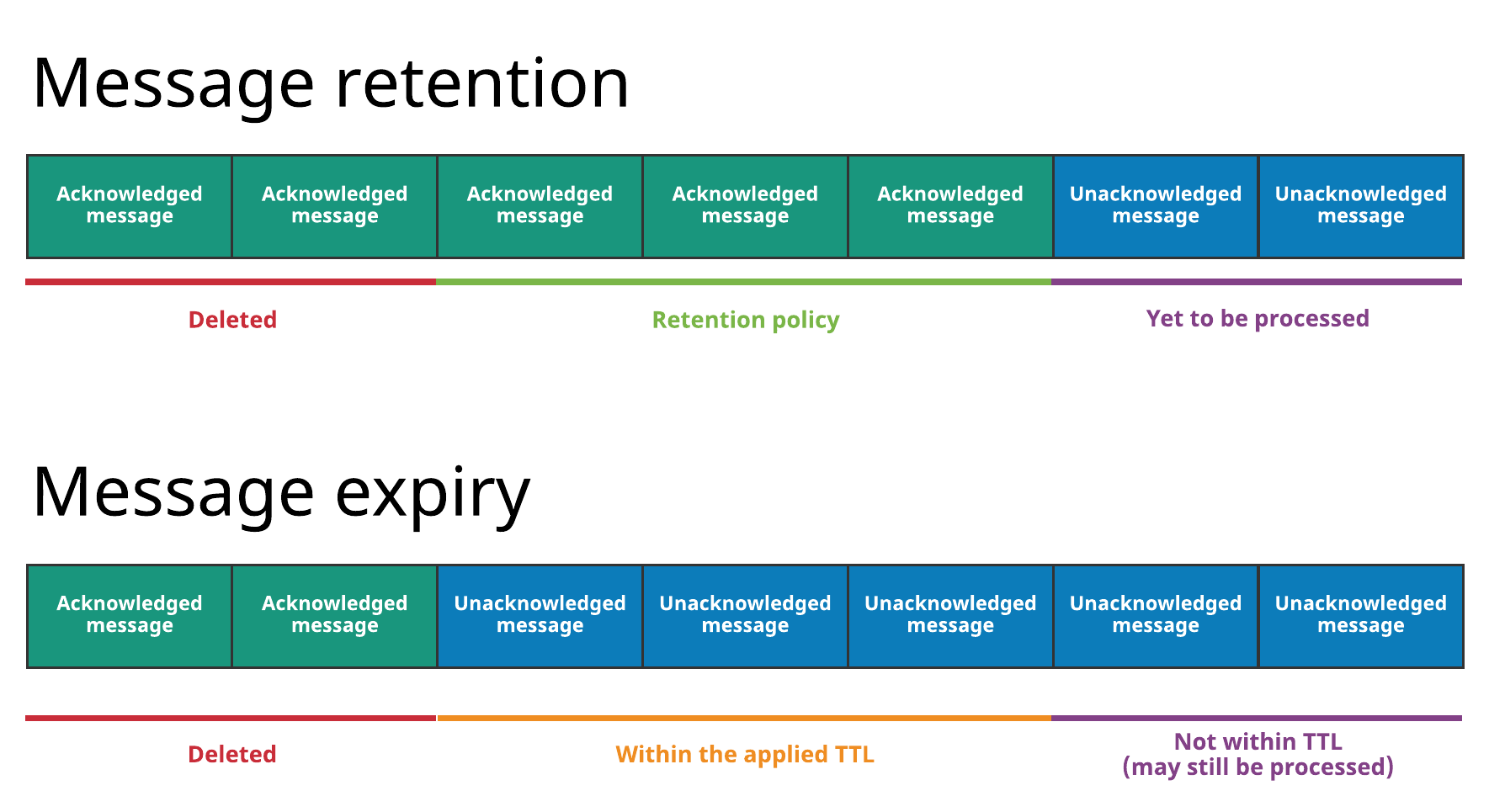
图中上面的是消息存留,存留规则会被用于某namespace下所有的topic,指明哪些消息会被持久存储,即使已经被确认过。 没有被留存规则覆盖的消息将会被删除。 如果没有保留策略,所有已确认的消息将被删除。
图中下面的是消息过期,有些消息即使还没有被确认,也被删除掉了。因为根据设置在namespace上的TTL,他们已经过期了。(例如,TTL为5分钟,过了十分钟消息还没被确认)
消息去重:
参考手册:https://pulsar.apache.org/docs/zh-CN/cookbooks-deduplication/
消息去重保证了一条消息只能在 Pulsar 服务端被持久化一次。 消息去重是一个 Pulsar 可选的特性,它能够阻止不必要的消息重复,它保证了即使消息被消费了多次,也只会被保存一次。
下图展示了开启和关闭消息去重的场景:
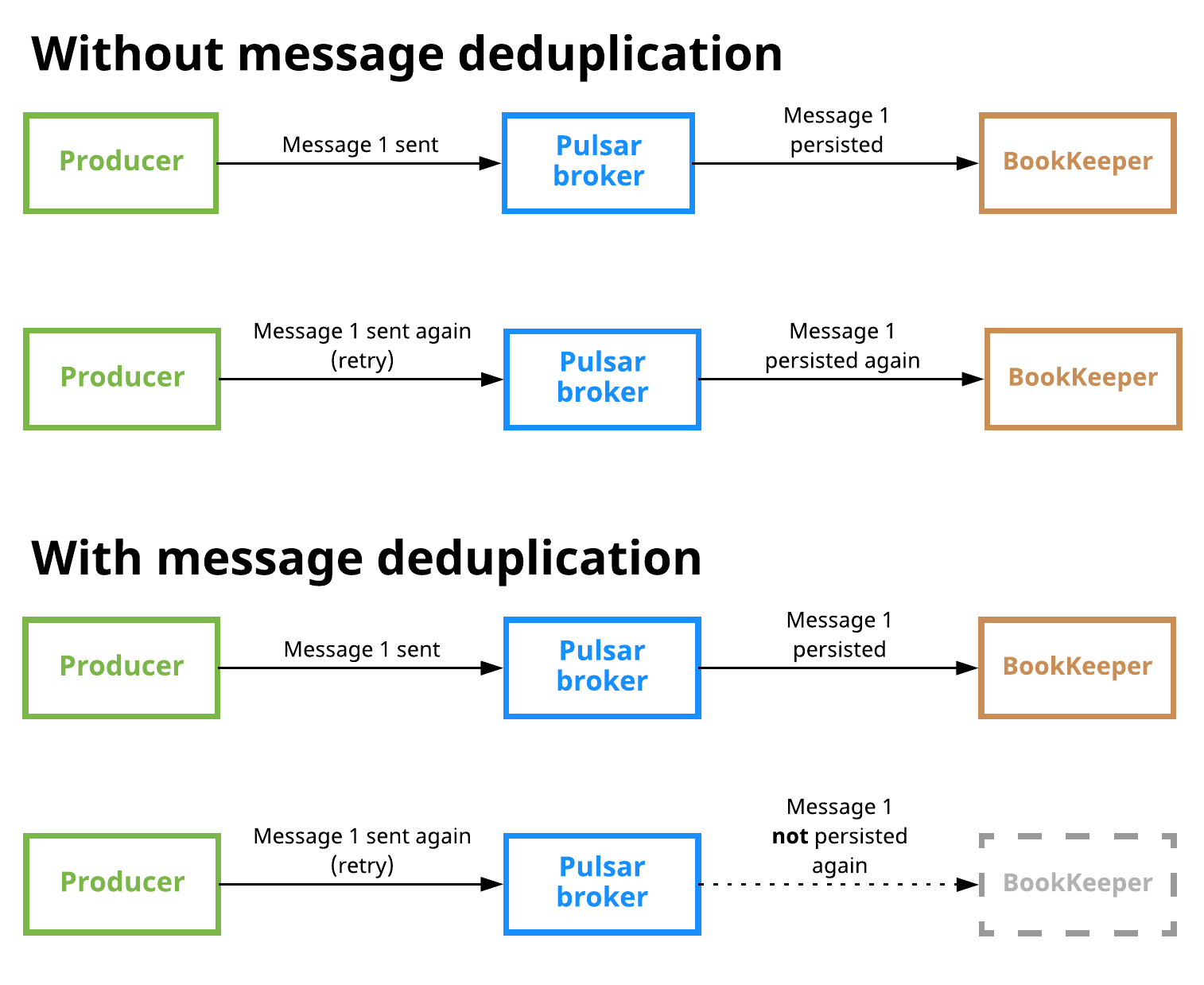
生产者幂等:
The other available approach to message deduplication is to ensure that each message is only produced once. This approach is typically called producer idempotency. 这种方式的缺点是,把消息去重的工作推给了应用去做。 在 Pulsar 中,消息去重是在 broker上处理的,用户不需要去修改客户端的代码。 相反,你只需要通过修改配置就可以实现。
去重和实际一次语义:消息去重,使 Pulsar 成为了流处理引擎(SPE)或者其他寻求 "仅仅一次" 语义的连接系统所需的理想消息系统。 如果消息系统没有提供自动去重能力,那么 SPE (流处理引擎) 或者其他连接系统就必须自己实现去重语义,这意味着需要应用去承担这部分的去重工作。 使用Pulsar,严格的顺序保证不会带来任何应用层面的代价。
消息延迟传递:
延时消息功能允许你能够过一段时间才能消费到这条消息,而不是消息发布后,就马上可以消费到。 在这种机制中,消息存储在BookKeeper中,DelayedDeliveryTracker在发布到broker之后维护内存中的时间索引(time -> messageId),一旦经过了特定的延迟时间,它就被传递给消费者。
延迟消息传递仅在共享订阅模式下有效。在Exclusive和Failover订阅模式中,将立即分发延迟的消息。
如下图所示,说明了延时消息的实现机制:
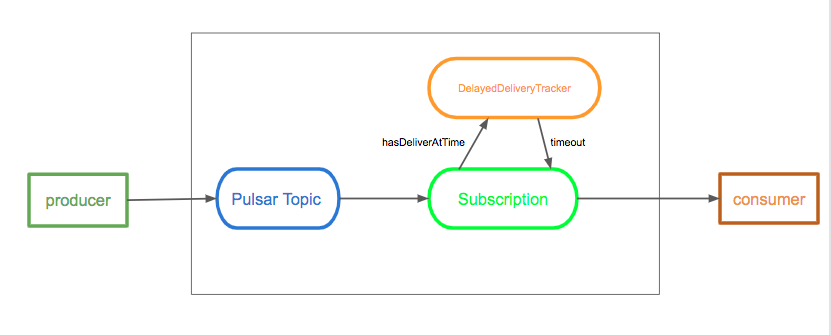
Broker 保存消息是不经过任何检查的。 当消费者消费一条消息时,如果这条消息是延时消息,那么这条消息会被加入到DelayedDeliveryTracker当中。 订阅检查机制会从DelayedDeliveryTracker获取到超时的消息,并交付给消费者。
默认情况下启用延迟消息传递。你可以在代理配置文件中修改它,如下所示:
# Whether to enable the delayed delivery for messages.
# If disabled, messages are immediately delivered and there is no tracking overhead.
delayedDeliveryEnabled=true
# Control the ticking time for the retry of delayed message delivery,
# affecting the accuracy of the delivery time compared to the scheduled time.
# Default is 1 second.
delayedDeliveryTickTimeMillis=1000
下面是 Java 当中生产延时消息一个例子:
producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();
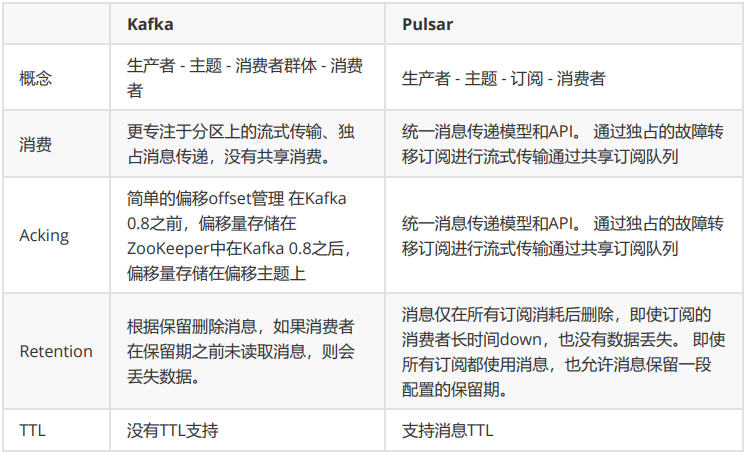
kafka 和 Pulsar 的区别:
Kafka架构由broker和zookeeper组成(Kafka2.8版本可以不依赖Zookeeper独立运行了),如下图:

Pulsar的架构如下(Pulsar Broker会在本地缓存消息,并且支持TTL):
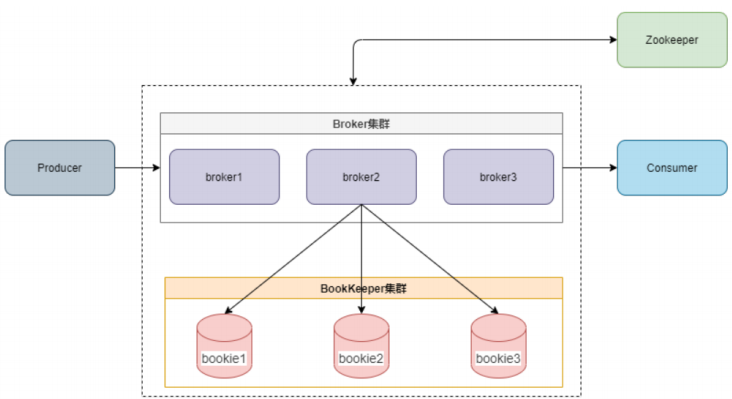
从上面的2个架构我们看到,Kafka和Pulsar有3点不同:
- Pulsar采用分层架构,将计算和存储相分离,存储使用BookKeeper集群,计算使用Broker集群, Broker需要内置BookKeeper客户端。
- Pulsar的部署和架构更加复杂,但是也更具有伸缩性。
- Pulsar在最新版本中依然不能脱离Zookeeper独立运行。
消息存储模型:
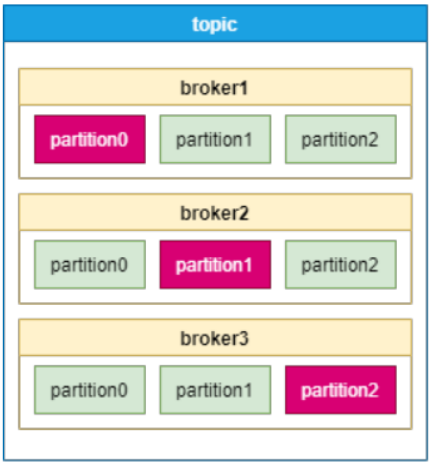
Kafka采用分区(Partition)的方式来保存topic,每个topic都会在不同的broker保存多个分区副本,其中只有一个副本的分区是leader分区,供消费者使 用。如果某个broker宕机了,这个broker上的leader分区失效,需要在其他broker上重新进行选举。模型图如下:
Pulsar 跟Kafka不同的是,Pulsar的消息存储模型采用了分层的方式,Bookkeeper中,数据的最小操作单位是Segment.如下图:
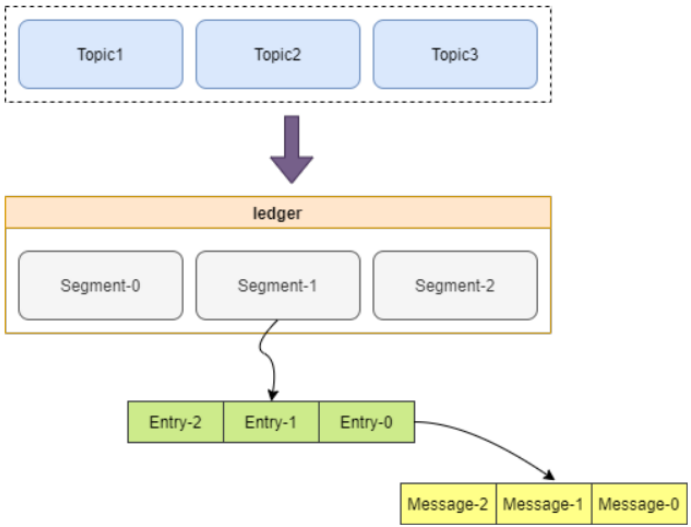
第一层是Topic,用来存储Producer追加的messages,Topic下面是ledger层,保存了分片(Segment), 分片里面保存更小粒度的ertries,entries存储一条条的Message。Ledger中的最后一个分片是最新写入的分片,如上图Segment-2。Segment-2之前的所有分片已完成封 装,这些分片的数据是不会再发生变化的。这样增加或删除一个BookKeeper节点,或者迁移长期存储 节点,都不会发生一致性问题。
消息消费模型:
Kafka的消费模型是采用消费者组的模式,每一个分区只能给消费者组中的一个消费者消费。如下图
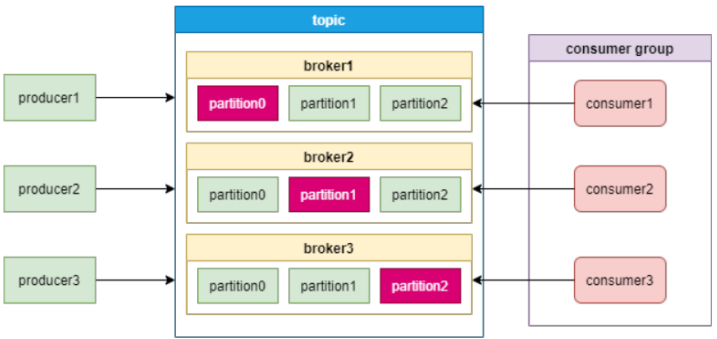
Pulsar的消费模型如下图:

Pulsar的topic是一种partitioned topic,可以被保存到多个broker,提高了topic的吞吐量。 Consumer通过Subscription获取消息,同一Topic的Subscription可以获取到Topic数据的完整拷贝,这 样Subscription为每一个Consumer分配一个Cursor,Consumer之间互不影响。如下图:
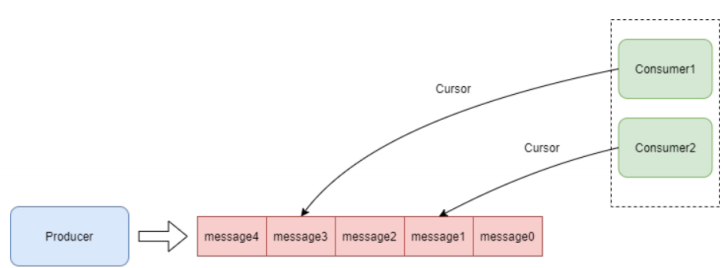
Pulsar的消费模型有4种 ,上文已经提到。不再赘述。
集群部署:
Kafka去除Zookeeper以后,部署是非常简单的。而Pulsar目前还没有去除Zookeeper的详细计划,而且需要使用到BookKeeper集群,部署复杂不少。
扩容:
Pulsar支持自动负载均衡,这对于增加broker节点和增加存储节点都非常方便。
云原生支持:
Pulsar 计算和存储节点分离,对云原生支持很好。 Kafka 多数组件也支持云原生。
替换broker:
Pulsar的broker节点是无状态的,替换时不用考虑数据丢失。
Apache Pulsar将高性能流式处理(Apache Kafka所追求的)和灵活的传统队列(RabbitMQ所追求的) 结合到一个统一的消息传递模型和API中,Pulsar使用统一的API提供一个流式处理和队列系统,具有相 同的高性能。
Pulsar作为新型的云原生分布式消息流平台,确实有很多优秀的设计理念。 在Yahoo内部支持应用服务平台中 140 万个topic,日处理消息超过 1000 亿条。腾讯的分布式交易引擎 TDXA也使用了Pulsar,应用于腾讯的计费平台。kafka目前的使用场景最多的还是日志大数据处理,对金融场景的应用比较少。 但这并不能说明Pulsar可以取代Kafka,Kafka用户群体庞大,社区和资源完善,而且在2.8版本中去除了 Zookeeper,部署非常容易。毕竟不是每家公司都需要Yahoo和腾讯这样的集群体量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号