
关于最近遇到的坑 - if queryset
背景
在python语法中,if obj是一种很简洁优雅的语法糖,可以用来判断字符串是否为空,某个参数是否为None,列表是否为空。所以,在面对queryset对象时便毫不犹豫的用if queryset来做判断,导致了性能问题。
class PageNumberPaginator(PageNumberPagination): .....省略无关代码 def paginate_queryset(self, queryset, request, ModelClass, view=None): self.total = None if queryset else get_total(queryset, ModelClass) return PageNumberPagination.paginate_queryset(self, queryset=queryset, request=request) def get_paginated_response(self, data, total=None): query_count = self.page.paginator.count return Response(OrderedDict([ ('result', 'ok'), ('paging', OrderedDict([ ('draw', self.draw), ('page', self.page_param), ('page_size', self.page_size), ('count', query_count), ('total', total if total else self.total or query_count), ])), ('data', data) ]))
现在就来具体拆分并分析为什么不能用if queryset来判断queryset是否为空。
技术拆解-关于if判断
关于if判断的问题其实就是bool类型的判断。默认情况下
1.if会尝试bool(obj)
2.调用obj.__bool__()
3.调用obj.__len__()
具体解析,在判断布尔类型时,if会调用内置的bool(obj),此函数只能返回True或False。bool(obj)的背后会先尝试调用obj.__bool__()方法,存在则返回obj.__bool__()方法的结果,如果不存在,bool(obj)会尝试调用x.__len__()。若返回0,则bool返回0,否则True。
所以我们可以自己扩展并撰写一个自定义满足布尔类型判断的对象。
class LenFunc: def __len__(self): print('len step >>>>>>>') return 1 def __repr__(self): return 'LenFunc for __len__ test' class BoolFunc: def __bool__(self): print('bool step >>>>>>>') return True def __repr__(self): return 'BoolFunc for __bool__ test' class MixFunc: def __len__(self): print('len step >>>>>>>') return 1 def __bool__(self): print('bool step >>>>>>>') return True def __repr__(self): return 'MixFunc for __len__&__bool__ test' func_list = [LenFunc(), BoolFunc(), MixFunc()] for obj in func_list: print(obj) if obj: print(obj, 'is True \r\n')
运行结果如下:
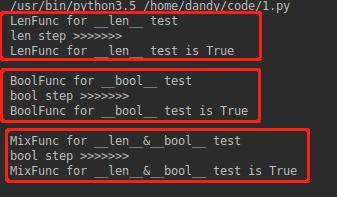
特殊方法的调用是隐式的,一般情况下,我们是不需要关注这些内容的,除非对于我们自定义的类型进行扩展,想尝试python的内置语法糖,才需要满足协议。
另外如果是python内置的类型,比如list, str, bytearray那么CPython会抄近路,__len__实际上会直接返回PyVarObject里的ob_size属性。PyVarObject是表示内存中长度可变的内置对象的C语言结构体。直接读取这个值比调用一个方法快多了。
技术拆解-queryset
queryset实际上是Django的内置的Queryset的实例。具体由来这边就不做阐述了,有兴趣的可以翻阅源码。下面贴上QuerySet的定义
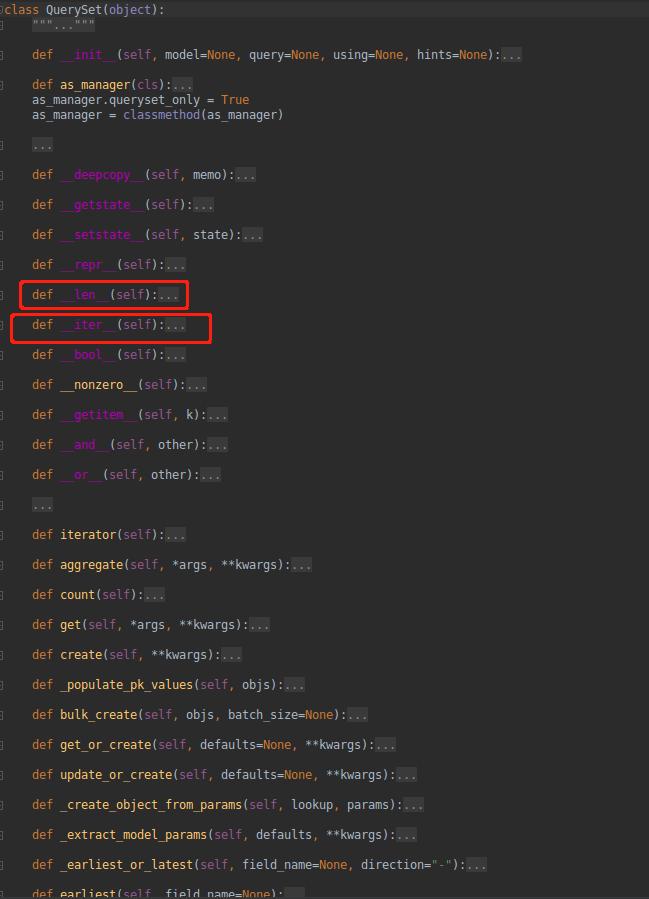
相信对django熟悉的都知道queryset对数据库的查询结果是懒加载的。其实,真正的加载查询数据库数据的步骤,在__len__和__iter__都可以发现。
在__len__中会有两步调用
class QuerySet(object): ..... def __len__(self): self._fetch_all() return len(self._result_cache) def _fetch_all(self): if self._result_cache is None: self._result_cache = list(self._iterable_class(self)) if self._prefetch_related_lookups and not self._prefetch_done: self._prefetch_related_objects()
第一步self._fetch_all()会查询可迭代对象内所有结果,即进行数据库查询操作,赋值数据库查询的结果列表给当前实例queryset的_result_cache属性,把查询结果加载内存中。
第二步返回查询数据结果列表的长度
综上分析原因
当在分页查询内进行if queryset判断时,默认先寻找__bool__方法,当前对象没有,便会调用__len__方法。此时queryset作为一个懒加载对象,本身是在分页完聚焦在分页的那几条数据(10, 20 ,50, 100 whatever)进行数据库查询,却因为在if调用了__len__方法而提前被触发数据库查询。
当面临查询结果特别大的时候,如需要被分页的结果有4w条,数据便会被加载在内存中,导致内存占用过高,特别是在大并发的线上环境,尤其会影响性能,造成内存占用,内存紧张,影响服务整体性能,造成卡顿,甚至服务直接down掉
建议使用queryset.exists()来替代
def exists(self): if self._result_cache is None: return self.query.has_results(using=self.db) return bool(self._result_cache)
django版本1.11.2
如果有兴趣,大家可以翻阅下源码,具体了解内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号