



SparkStreaming动态读取配置文件
标签: SparkStreaming HDFS 配置文件 MySql
需求
- 要实现SparkStreaming在流处理过程中能动态的获取到配置文件的改变
- 并且能在不重启应用的情况下更新配置
- 配置文件大概一个月改动一次,所以不能太耗性能
为什么需要动态读取配置文件?
在之前的项目中一直使用的读配置文件的模式是在应用启动阶段一次性读取配置文件并获取到其中的全部配置内容。并且,在程序运行过程中这些配置不能被改变,如果需要改变,则需要重新打包发布应用。
在代码测试阶段这种方式会很麻烦也很费时,所以需要一种能让应用动态更新配置的方法。
Spark程序的运行过程
1、Spark运行的基本流程
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
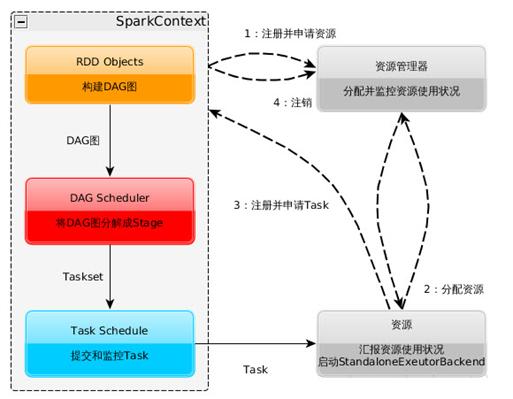
2、一个Spark程序的执行过程
一个用户编写的提交给Spark集群执行的application包含两个部分:
- 驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
- 计算逻辑:当计算任务在Worker执行时,执行计算逻辑完成application的计算任务。
那么哪些作为"驱动代码"在Driver进程中执行,哪些"任务逻辑代码”被包装到任务中,然后分发到计算节点进行计算?
- Spark application首先在Driver上开始运行main函数。执行过程中,计算逻辑的开始是从读取数据源(比如HDFS中的文件)创建RDD开始,RDD分为transform和action两种操作,transform使用的是懒执行,而action操作将会触发Job的提交。
- Application在Driver上执行,遇到RDD的action动作后,开始提交作业,当作业执行完成后,后面的作业陆续提交。
- action操作会进行回溯,把懒执行的操作一起打包发送到各个计算节点。简单来说,发送到计算节点的对RDD的操作就是计算逻辑,其余的都在Driver中执行。
思考
了解了Spark的执行流程之后,不难发现,尽管Spark的开发者很努力的让Spark编程模式尽可能的靠近普通的顺序执行的编程模式。但是作为一个分布式执行过程,还是跟普通编程模式有很大区别,不注意的话很容易踩到坑。
我也想过了许多解决方案,但是大部分都卡在了这个分布式的坑上边。
比如:
- 一开始我考虑过是不是把读取配置文件的代码写到SparkContext初始化的代码之后,并以文件流的形式读取配置文件想要实现让Streaming每个批次都读。了解了上面的运行过程之后就会发现这是行不通的。
- 之后又思考能否利用检查点机制在程序从检查点读取数据时加载配置文件。但是有一个问题,程序发生改变之后检查点的数据会被丢弃。
- 然后又调研了市面上存在且常用的几个第三方配置管理平台,比如百度disconf,奇虎qconf,淘宝Diamond。调查结果则是现有的这些配置管理平台都是针对web项目做配置管理,不能很好的支持大数据的这种分布式架构。
在这些方向都走不通之后,我又重新回到Spark本身的执行流程上思考。Spark的action操作会发布到各个计算节点进行执行,如果把读取配置文件的操作写在action操作里带到各个节点进行执行,应该可以实现让每个节点都读取到配置文件,且可以实时改变。测试的结果也证明了这种方式是可行的。
详细设计
有了思路接下来就是代码测试。上面的三种失败方案也都进行了代码测试证明是不可行的。
首先是从HDFS中读取配置文件,在这里我写了个工具类:
object HDFSUtil {
val conf: Configuration = new Configuration
var fs: FileSystem = null
var hdfsInStream: FSDataInputStream = null
val prop = new Properties()
//获取文件输入流
def getFSDataInputStream(path: String): FSDataInputStream = {
try {
fs = FileSystem.get(URI.create(path), conf)
hdfsInStream = fs.open(new Path(path))
} catch {
case e: IOException => {
e.printStackTrace
}
}
return hdfsInStream
}
//读取配置文件
def getProperties(path:String,key:String): String = {
prop.load(this.getFSDataInputStream(path))
prop.getProperty(key)
}
然后是SparkStreaming初始化以及处理TCP流数据:
val conf = new SparkConf().setAppName("write data to mysql")
val ssc = new StreamingContext(conf,Seconds(10))
val streamData = ssc.socketTextStream("T002",9999)
val wordCount = streamData.map(line =>(line.split(",")(0),1)).reduceByKey(_+_)
val hottestWord = wordCount.transform(itemRDD => {
val top3 = itemRDD.map(pair => (pair._2, pair._1))
.sortByKey(false).map(pair => (pair._2, pair._1)).take(3)
ssc.sparkContext.makeRDD(top3)
})
hottestWord.foreachRDD( rdd =>{
rdd.foreachPartition(partitionOfRecords =>{
val path = "hdfs:///home/wuyue/property/test.properties"
val MD5Value = HDFSUtil.getHdfsFileMd5(path)
val sql=HDFSUtil.getProperties(path,"sql")
HDFSUtil.close
测试读取的数据是一条sql语句,如果能读取到就可以把数据正确的存入MySql中,如果读取不到配置,程序就会报错。连接数据库的代码如下:
val connect = scalaConnectPool.getConnection
connect.setAutoCommit(false)
val ps = connect.prepareStatement(sql)
partitionOfRecords.foreach(record =>{
val word = record._1
val count = record._2
ps.setString(1,word)
ps.setInt(2,count)
ps.addBatch()
})
ps.executeBatch()
connect.commit()
scalaConnectPool.closeConnection(ps,connect)
我写了一个数据库连接池方便进行数据库连接,因为获取数据库的连接并不是很耗性能,sql语句的执行最耗性能,所以出于性能角度考虑,存入MySql的操作我使用的是批处理模式。
经过测试,数据能够正确的存入数据库中,并且手动更改配置文件之后程序出错停止,说明程序能够读到配置文件中的变化并进行更新。
设计的不足之处
因为Spark读取数据的操作是分布在各个计算节点执行的,如果使用传统的文件资源管理器就必须在每个节点机器的目录下都存放一份配置文件,并且在改动时要同时进行,这是很不方便的。所以在测试中使用HDFS(分布式文件系统)存储配置文件。
但是HDFS主要用来做大数据量批量读写操作的,对单个文件的随机读写会很慢。
所以我在要读取配置文件之前增加了一个对文件是否改动进行的判断,如果配置文件发生变化则重新读取文件,如果没有变化则不读取。
具体实现方式为获取文件的MD5值,如果MD5值发生变化说明文件有改动,如果不变说明文件没有改动。
但即使是这样,在HDFS上进行随机读写依然很耗性能。因为是测试阶段,主要为了证明这种方式是可行的,在进一步的测试中可以考虑使用MySql或者Redis替换掉HDFS来存储配置文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号