

作业要求 20180918-1 词频统计
词频统计
此作业的要求参见https://edu.cnblogs.com/campus/nenu/2018fall/
编写一个名为wf的程序,统计英文作品的单词量并给出每个单词出现的次数,以及统计出文章中不重复的单词个数。
一、要求:
1:小文件输入;
2:支持命令行输入英文作品的文件名;
3:支持命令行输入存储有英文作品文件的目录名,批量统计;
4:从控制台读入英文单篇作品,输入重定向。
二、功能重、难点分析及运行结果:
(1)功能一:
统计小文件中的单词数量,设置了每个单词及词频的结构体,并分配空间。
代码片段:
1 //设置结构体 2 typedef struct word{ 3 int fre; 4 char w[50]; 5 }wordnode; 6 7 //分配空间 8 wordnode *words=(wordnode*)malloc(500*p*sizeof(wordnode)); 9 10 //打开文件 11 FILE *fp = fopen(fname,"r");
运行结果图:
(先运行type程序进行写文件,后运行wf程序对文件进行单词数的统计以及排序后的输出)
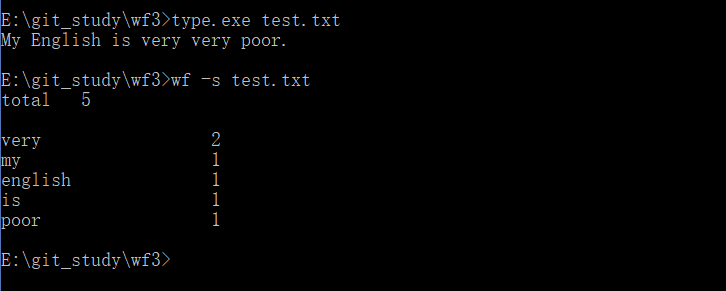
(2)功能二:
读取大文件,重点在于对于字符串中的单词的分割。我的思路是:从文件开头逐个读取字符,判断是否是字母,若为字母,存入到临时设定的tmp数组中,这中间还考虑到两个特殊情况,就是连字符“-”以及表示所有格的“ \’ ”也要一起加入到tmp数组中。
代码片段:
//判断是否是单词 while(!feof(fp)) { if(isalpha(ch)||(isdigit(ch))) { flag = 1; tmp[i++]=ch; } else { if(flag) { if((ch=='-')||(ch=='\'')) { tmp[i++]=ch; flag = 1; } else { flag=0; tmp[i]='\0'; i=0; for(j=0;j<num;j++) { if(strcmp((words+j)->w,tmp)==0) { (words+j)->fre++; break; } } if(j==num) { (words+num)->fre=1; strcpy((words+num)->w,tmp); num++; } if(num==500*p) { p++; words=(wordnode*)realloc(words,500*p*sizeof(wordnode)); for(k=num;k<500*p;k++) { (words+k)->fre=0; } } } } } ch = tolower(fgetc(fp)); }
运行结果图:
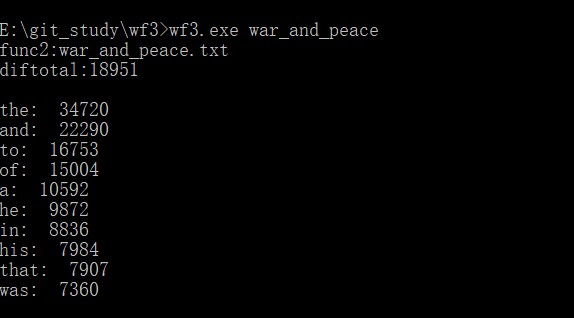
注:根据老师以word查找单词的个数为准的要求,这里统计的是文档中含有不同单词的个数(重复词计数为1)。
(3)功能三:
重点在于判断输入的字符串是否是文件夹,并对文件夹中的文件进行批量统计。
代码片段:
1 //判断读入的字符串是文件夹还是文件 2 3 strcpy(tmp,argv[1]); 4 p = strcat(argv[1],s); 5 result = _stat( p, &buf ); 6 if(_S_IFDIR & buf.st_mode) 7 { 8 printf("func3\n\n"); 9 p1=strcat(tmp,t); 10 if((Handle=_findfirst(p1,&FileInfo))==-1L) 11 { 12 printf("文件不存在\n"); 13 } 14 else 15 { 16 printf("%s\n",FileInfo.name); 17 fun1(FileInfo.name); 18 printf("---------------------------------------\n"); 19 while(_findnext(Handle,&FileInfo)==0) 20 { 21 printf("%s\n",FileInfo.name); 22 fun1(FileInfo.name); 23 printf("---------------------------------------\n"); 24 } 25 _findclose(Handle); 26 } 27 } 28 else if(_S_IFREG & buf.st_mode) 29 { 30 fun1(p); 31 }
运行结果图:
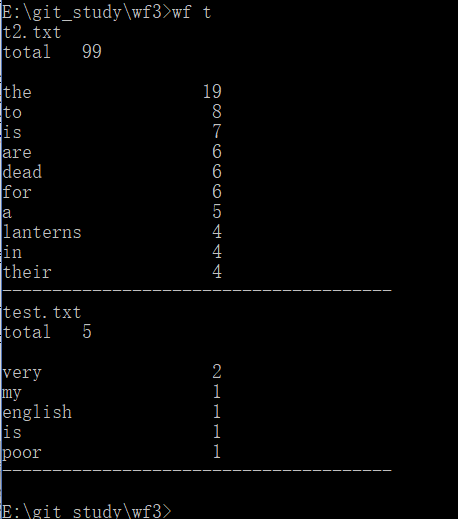
(4)功能四:
从控制台读入英文单篇作品,输入重定向。这里对重定向的概念查找了很多资料。重定向有两种方式,在c语言中可以通过调用函数freopen()将指定的文件作为输入。第二种方法是在控制台利用符号'<',后面跟随的文件即为重定向输入的文件。
同时也可以直接在控制台输入文件,并进行统计单词数量。
运行结果图:
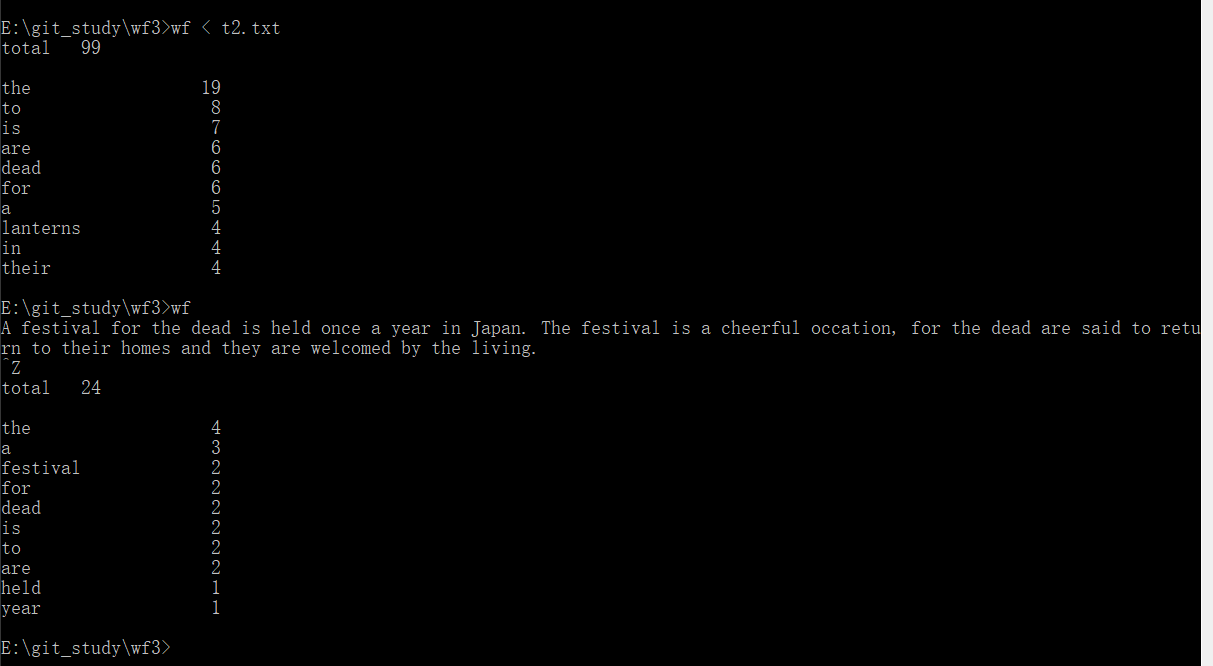
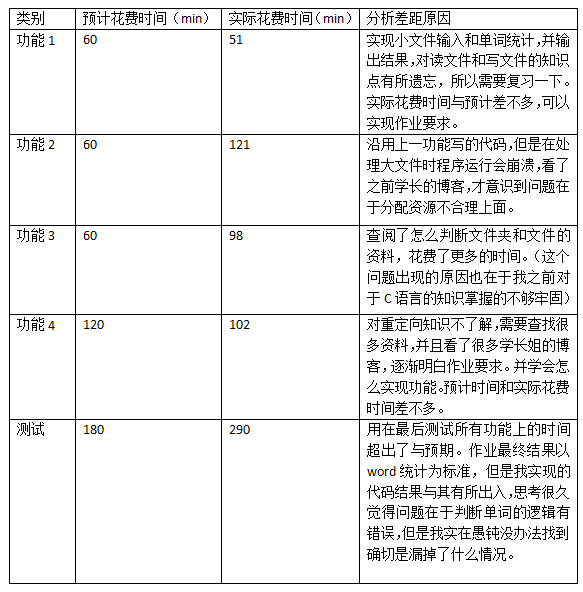
三、PSP:
四、代码及版本控制:
代码地址:https://git.coding.net/wuyy694/wf.git
五、总结:
老师在这次作业的要求上有说可以使用自己熟悉的语言,编程能力弱的我选择用唯一会使用的c语言来完成作业。但是在实际做作业实现功能的过程中,我逐渐发现,单纯的用c语言貌似不能得到老师所要求的与word统计数相同。焦灼的寻找愿意,我发现一些英文作品中会存在一些无法判断的字符,以《战争与和平》为例,在这本书中的人名或地名中会存在一些或许名为意大利字母的字符,在我的判断规则中,这种字符会将一个地名分割成两个,而我没办法得到他们的ascll码,也就不能排除这些分割的情况。如果反过来想,以空格和换行符作为分割单词的标志,在文章中也会经常出现一种破折号,而这种字符也依然没有ascll编码,虽然可以用投机取巧的方法输出它代表的数字,但是我无法得知是否还存在其他的情况,除非通读56万字的英文名著。
所以,我选择放弃得到这种精准的计数结果(虽然我很不想)。同时我也在这段找错误的焦灼中,得到一些教训。上星期读《构建之法》时,看到已经工作的人花费了非常多的时间在前期的计划上,虽然我能想到这中间的一些道理,但是也依然在自己的实践中吃到了苦头。也许在动手实现之前多和同学讨论一下,我不会选择用C语言实现,也或者我能够有一个更好的判断方法。在最后几天也不会因为想要推翻重写而觉得沮丧灰心,甚至因为完不成作业而更加焦灼。
同时的同时,这次经历告诉我,我必须尽快掌握新的一门编程语言,并且计划用新学的语言来完成这次作业。。(也许会得到正确的答案)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号