


14.ES整合项目
1.创建新模块
只选web不选SpringData的es

导入依赖
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency> <dependency> <groupId>com.wuyimin.gulimall</groupId> <artifactId>gulimall-common</artifactId> <version>0.0.1-SNAPSHOT</version> </dependency>
排除数据源操作
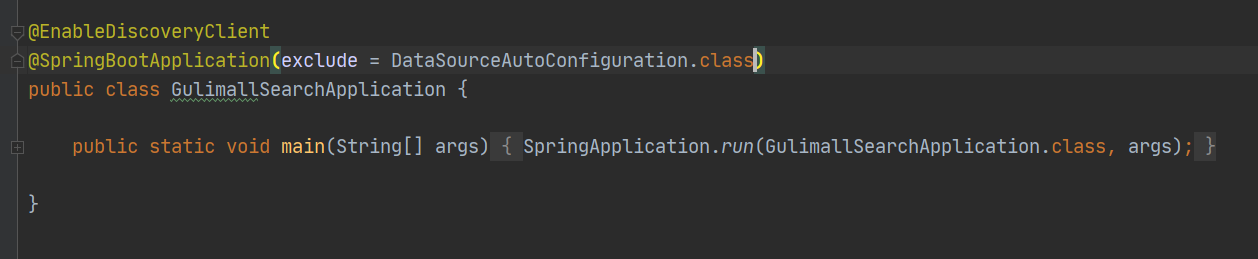
更改springboot链接的版本
<properties> <java.version>1.8</java.version> <elasticsearch.version>7.4.2</elasticsearch.version> </properties>
增肌配置文件

@Configuration public class ESConfig { public static final RequestOptions COMMON_OPTIONS; //默认规则 static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient() { RestClientBuilder builder = null; // 可以指定多个es builder = RestClient.builder(new HttpHost("192.168.116.128", 9200, "http")); RestHighLevelClient client = new RestHighLevelClient(builder); return client; } }
2.测试增删改查操作
遇到错误 Found interface org.elasticsearch.common.bytes.BytesReference, but class was expected
是因为同时导入了两个类型的es导致的

改这个版本没有生效导致导入了两个es版本
既然改不了就加入吧,目前还没有兼容问题
测试数据的插入,更新也可以使用该方式
@SpringBootTest class GulimallSearchApplicationTests { @Autowired private RestHighLevelClient client; @Test void contextLoads() throws IOException { //测试存储数据 IndexRequest users = new IndexRequest("users");//索引名为user users.id("1");//id全部都是字符串的形式 users.source("userName","张三","age",18,"gender","男");//第一种方案 User user = new User(); user.setAge(10); user.setGender("女"); user.setUserName("小小吴"); String s = JSON.toJSONString(user);//需要导入FastJson users.source(s, XContentType.JSON);//同时也需要传入数据的类型 //调用es执行保存操作 IndexResponse index = client.index(users, ESConfig.COMMON_OPTIONS); //提取响应数据 System.out.println(index); } @Data class User{ private String userName; private String gender; private Integer age; } }
测试成功

3.测试复杂检索
hits的结构

聚合的结构

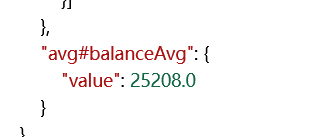
@SpringBootTest class GulimallSearchApplicationTests { @Autowired private RestHighLevelClient client; @Test void contextLoads() throws IOException { //测试存储数据 IndexRequest users = new IndexRequest("users");//索引名为user users.id("1");//id全部都是字符串的形式 users.source("userName","张三","age",18,"gender","男");//第一种方案 User user = new User(); user.setAge(10); user.setGender("女"); user.setUserName("小小吴"); String s = JSON.toJSONString(user);//需要导入FastJson users.source(s, XContentType.JSON);//同时也需要传入数据的类型 //调用es执行保存操作 IndexResponse index = client.index(users, ESConfig.COMMON_OPTIONS); //提取响应数据 System.out.println(index); } @Test void test() throws IOException { //1.创建检索请求 SearchRequest searchRequest=new SearchRequest(); //2.指定索引 searchRequest.indices("bank"); //3.DSL,检索条件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //构造年龄值分布 searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//address值必须为mill TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);//名字为ageAgg,年龄进行聚合分组,只显示10种可能 searchSourceBuilder.aggregation(ageAgg); //同级聚合,计算平均薪资 AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");//求平均值 searchSourceBuilder.aggregation(balanceAvg); System.out.println(searchSourceBuilder.toString()); searchRequest.source(searchSourceBuilder); //4.执行检索 SearchResponse searchResponse = client.search(searchRequest, ESConfig.COMMON_OPTIONS); //5.分析结果 //获取所有查到的数据 SearchHit[] hits=searchResponse.getHits().getHits();//获得我们里面的hits for(SearchHit searchHit:hits){ String string = searchHit.getSourceAsString(); Account account = JSON.parseObject(string, Account.class); System.out.println(account); } //获取分析信息 Aggregations aggregations = searchResponse.getAggregations(); Terms agg = aggregations.get("ageAgg"); for (Terms.Bucket bucket : agg.getBuckets()) { String key = bucket.getKeyAsString(); System.out.println("年龄: "+key+"==>"+bucket.getDocCount());//key为xx的人有xx个 } Avg balanceAvg1 = aggregations.get("balanceAvg"); System.out.println("平均薪资:"+balanceAvg1.getValue()); } @Data class User{ private String userName; private String gender; private Integer age; }
//必须是static才能被fastjson parse @Data @ToString static class Account{ private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state; } }

4.product建立索引
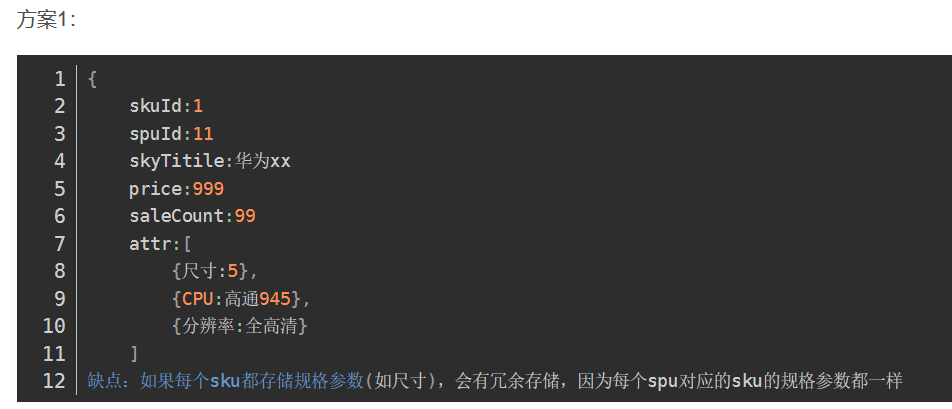
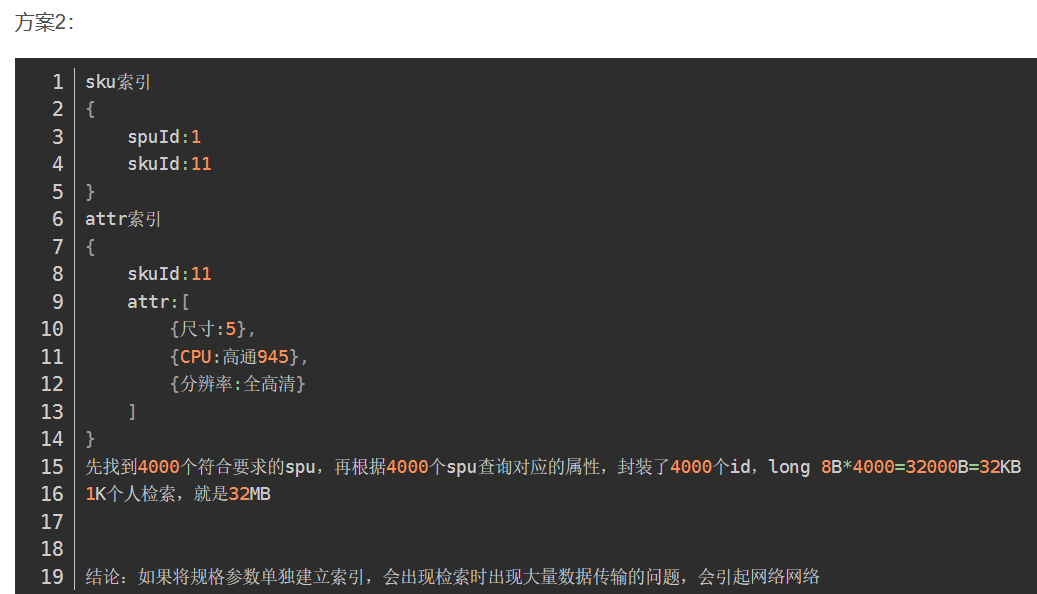
最终建立的模型
PUT product { "mappings":{ "properties": { "skuId":{ "type": "long" }, "spuId":{ "type": "keyword" }, # 不可分词 "skuTitle": { "type": "text", "analyzer": "ik_smart" # 中文分词器 }, "skuPrice": { "type": "keyword" }, # 保证精度问题 "skuImg" : { "type": "keyword" }, # 视频中有false "saleCount":{ "type":"long" }, "hasStock": { "type": "boolean" }, "hotScore": { "type": "long" }, "brandId": { "type": "long" }, "catalogId": { "type": "long" }, "brandName": {"type": "keyword"}, # 视频中有false "brandImg":{ "type": "keyword", "index": false, # 不可被检索,不生成index,只用做页面使用 "doc_values": false # 不可被聚合,默认为true }, "catalogName": {"type": "keyword" }, # 视频里有false "attrs": { "type": "nested", #嵌入式 "properties": { "attrId": {"type": "long" }, "attrName": { "type": "keyword", "index": false, "doc_values": false }, "attrValue": {"type": "keyword" } } } } } }
对nested嵌入式做出解释:

数组的扁平化处理会使检索能检索到本身不存在的,为了解决这个问题,就采用了嵌入式属性,数组里是对象时用嵌入式属性(不是对象无需用嵌入式属性)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号