
Annoy 近邻算法
Annoy
随机选择两个点,以这两个节点为初始中心节点,执行聚类数为2的kmeans过程,最终产生收敛后两个聚类中心点
二叉树底层是叶子节点记录原始数据节点,其他中间节点记录的是分割超平面的信息


但是上述描述存在两个问题:
(1)查询过程最终落到叶子节点的数据节点数小于 我们需要的Top N相似邻居节点数目怎么办?
(2)两个相近的数据节点划分到二叉树不同分支上怎么办?
针对这个问题可以通过两个方法来解决:
(1)如果分割超平面的两边都很相似,那可以两边都遍历
(2) 建立多棵二叉树树,构成一个森林
(3)所有树返回近邻点都插入到优先队列中,求并集去重, 然后计算和查询点距离, 最终根据距离值从近距离到远距离排序, 返回Top N近邻节点集合
Summary of features
- Euclidean distance, Manhattan distance, cosine distance, Hamming distance, or Dot (Inner) Product distance
- Cosine distance is equivalent to Euclidean distance of normalized vectors = sqrt(2-2*cos(u, v))
- Works better if you don't have too many dimensions (like <100) but seems to perform surprisingly well even up to 1,000 dimensions
- Small memory usage
- Lets you share memory between multiple processes
- Index creation is separate from lookup (in particular you can not add more items once the tree has been created)
- Native Python support, tested with 2.7, 3.6, and 3.7.
- Build index on disk to enable indexing big datasets that won't fit into memory (contributed by Rene Hollander)
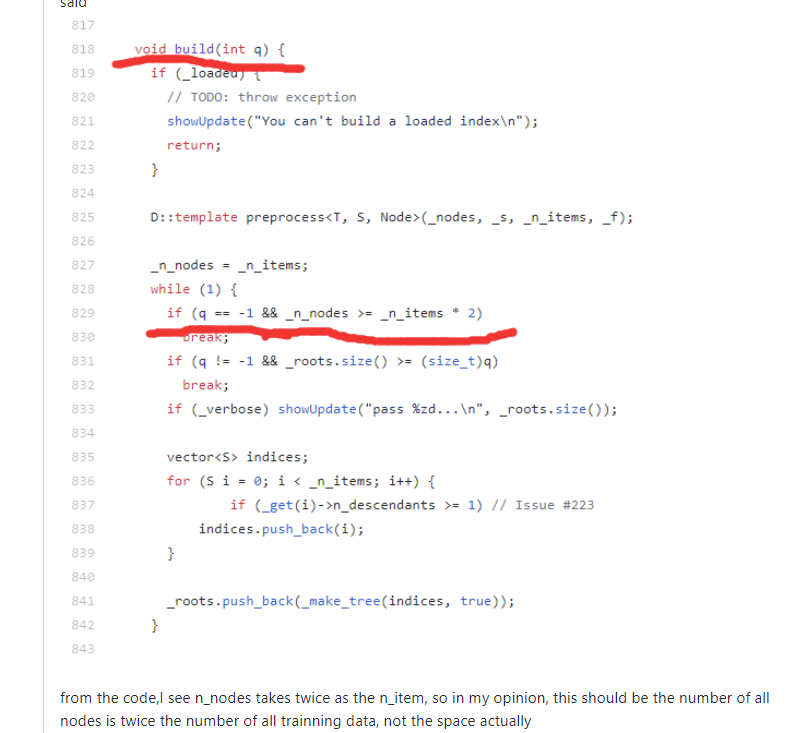
build(-1)的树的颗数问题
:所有节点的个数是trainning data的2倍左右:https://github.com/spotify/annoy/issues/338
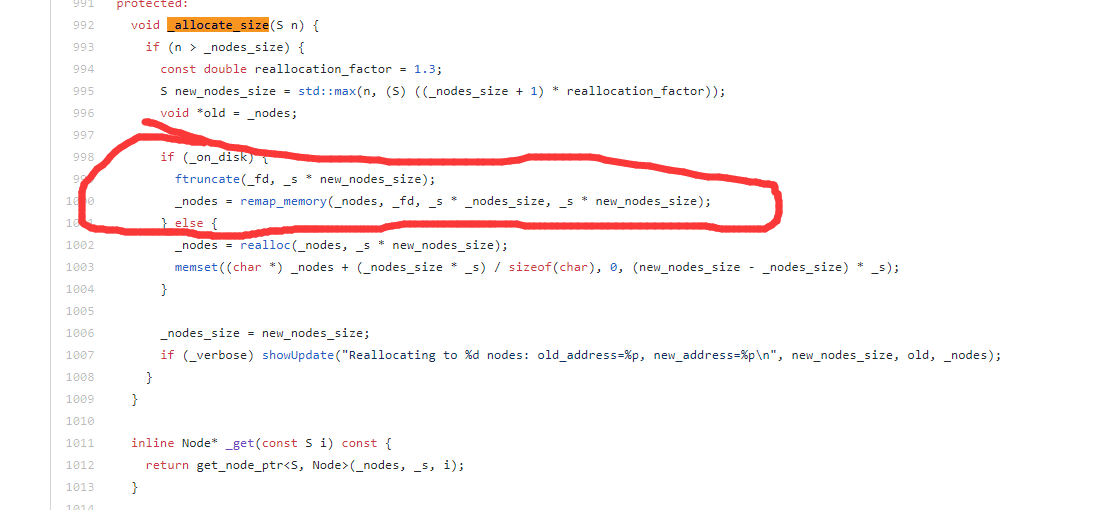
build_on_disk 问题
写文件时候,会向磁盘写

 浙公网安备 33010602011771号
浙公网安备 33010602011771号