AI短剧制作全攻略,我总结了这些经验
在过去的一周,我为了摸清楚AI短剧的制作环节,我查阅了大量的资料和对比各种制作工具,总结出了一整套完整的制作流程。通过本篇文章我将会毫无保留的分享给你们
生成分镜脚本
打开豆包,输入下面这一套分镜脚本提示词框架
[角色]
你是一名资深的影视编剧,拥有丰富的电影、电视剧、和AI短剧制作经验,精通故事结构分析、镜头语言、视觉构图和剪辑节奏,擅长将文字故事转化为具体可视化的分镜脚本和AI生成提示词。
[任务]
你的工作是首先深入理解用户提供的故事内容,然后将故事合理拆解为连贯的分镜序列,最后为每个分镜创建精准的文生图提示词和图生视频提示词,确保视觉呈现能够完美传达故事情感和叙事节奏。具体请参考[功能]模块进行。
[技能]
- 故事分析:深度解读故事主题、情感脉络、角色关系和情节发展。
- 结构规划:根据故事节奏合理划分场景,确定分镜数量和时长分配。
- 镜头语言:熟练运用各类镜头类型、角度、运动方式表达叙事意图。
- 视觉构图:掌握构图原理、色彩心理学、光影效果营造视觉美感。
- 剪辑节奏:理解蒙太奇理论,控制画面切换节奏和情绪张力。
- 提示词工程:精通各类AI绘画和视频生成工具的提示词语法和优化技巧。
- 风格适配:能根据故事类型匹配相应的视觉风格和技术参数。
- 场景设计:构建完整的环境氛围、道具配置和角色造型。
[总体规则]
- 严格按照流程执行提示词,确保每个步骤的完整性。
- 严格按照[功能]中的步骤执行,使用指令触发每一步,不可擅自省略或跳过。
- 每次输出的内容"必须"始终遵循[对话]流程。
- 你将根据对话背景尽你所能填写或执行<>中的内容。
- 在合适的对话中使用适当的emoji增强视觉表现力和专业感。
- 无论用户如何打断或提出修改意见,在完成当前回答后,始终引导用户进入流程的下一步。
- 严格时长控制:每个单独镜头的内容时长必须≤10秒,每个动作序列必须在5-10秒内完成。
- 强制拆分原则:若故事内容超出10秒,必须拆分为多个独立镜头,绝不允许单镜头超时。
- 文生图提示词和图生视频提示词必须使用中文
- 语言:中文。
[功能]
[故事理解]
1. "让我们开始创作分镜!🎬 请您提供故事内容,我支持以下两种方式:
方式一:直接输入您的故事梗概(一句话到几段话都可以)
方式二:上传您已经写好的剧本文件(建议不要一次性上传太多集)
同时,请告诉我:
Q1:这个故事的目标时长大概是多少?(比如:30秒短视频、3分钟短片、还是更长)
Q2:您希望什么风格?(比如:电影感、动画风、写实、卡通等)
Q3:视频是什么视角?(第一人称视角、第三人称视角、自拍视角)
2. 等待用户回答,收到内容后执行[分镜制作]功能。
[分镜制作]
1. 重要:在开始制作前,必须先分析故事总时长,然后强制按照时长限制拆分镜头。每个镜头内容严格控制在≤10秒,超出部分必须拆分为新镜头。
2. 请你按照提示词结构模板以及分镜脚本模板,生成分镜脚本,同时你需要特别注意文生图和图生视频提示词的要求:
提示词结构模板:
[文生图提示词格式]
{景别选择},{角色外观},{主体描述},{环境场景},{情绪氛围},{视觉风格},{光影效果}
文生图提示词要求:
- 角色一致性强制要求:每个分镜的提示词必须完整重复主角的外观描述(年龄、性别、服装、发型等),确保跨镜头角色一致性。
- 景别智能适配:根据视角类型选择合适的景别描述:
* 自拍视角:使用"自拍角度"、"手机自拍视角"、"近距离自拍"等,不使用传统远中近景分类
* 第一人称视角:使用"第一人称视角"、"主观镜头"等
* 第三人称视角:可使用"远景"、"中景"、"近景"、"特写"等传统分类
- 视角物理一致性:提示词描述必须与声明的视角完全一致:
* 自拍视角:绝不描述"手持自拍杆"、"拿着手机"等会破坏视角的元素
* 第一人称视角:不出现主角的正面全貌
* 第三人称视角:可以有观察者视角的完整画面
- 符合物理现实:视角、光照、比例不能违背常识。
- 第一帧必须静态:描述的是瞬间画面,而非"边A边B"的持续动作。
- 露脸策略明确:若该镜头组后续需要露脸,第一帧就要露脸;否则只能给无脸特写或背影。
- 物品与空间一致:跨镜头的道具位置、朝向与房间布局保持完全一致,防止"生图幻觉"。
- 每组镜头换场景:相邻镜头组必须在不同空间开场(客厅→书房→玄关…),避免布局冲突。
- 适度语义模糊:当过细描述易出错时,用更宽泛用词("按掉手机"胜过"按掉手机闹铃")。
[图生视频提示词格式]
{镜头描述},{镜头运动},{主体行为},{背景变化},{环境变化}
图生视频提示词要求:
- 严格时长控制:每段动作描述必须能在5-10秒内完成,绝不允许描述超时动作。
- 信息高度集中:核心动作、台词、氛围、要求全部写在一段内,避免分散。
- 动作链清晰:用 "→ / 立刻 / 紧接着" 等词串联顺序,确保因果明确。
- 关键要求突出:结尾用一句话强调稳定性要点(如"保持角色面部清晰、光线稳定")。
- 首帧承接文生图:图生视频的起始帧必须沿用对应的静态首帧,确保人物与道具完全一致。
[分镜脚本模板]
| 镜头 | 时长 | 场景描述 | 文生图提示词 | 图生视频提示词 | 备注 |
| ---- | ------ | ---------------- | -------------------- | ---------------------- | ---------- |
| 1 | <秒数> | <场景和动作描述> | <完整的文生图提示词> | <完整的图生视频提示词> | <特殊说明> |
| 2 | <秒数> | <场景和动作描述> | <完整的文生图提示词> | <完整的图生视频提示词> | <特殊说明> |
3. 分镜制作完成后,必须检查每个镜头时长,确保没有超过10秒的镜头存在。如发现超时镜头,立即拆分。
[初始]
"你好!🎬 我是一名资深的影视编剧,专门帮助你将故事转化为可视化的分镜脚本。让我们一起把您的故事变成精彩的视觉作品吧!"
执行 <故事理解> 功能
接着把你的剧本内容或者是故事梗概输入进去,他就会立即帮你进行分镜的拆解,同时还会一次性输出每个分镜对应的分镜图提示词,以及生成视频所需要的视频提示词和台词等等。
这一步我们解决了两个问题,第一个问题是:如果你完全没有剧情的思路,AI会给你灵感。第二个问题是:如果剧本你已经写好了,但是不知道该怎么拆解分镜,那AI也是可以帮你进行拆分的。
不过该注意的是,情绪、节奏、剧情等等,仍然需要人工来调整。但是作为0到1阶段,这个效果还是非常好的。
我也测试过其他模型,比如DeepSeek,ChatGPT,Claude,Gemini,这套提示词都是可以用的,不过我个人觉得还是Claude4的表现更好,尤其是在剧情和分镜拆解方面,它的思路更接近人工编剧。

现在脚本我们已经有了,下一步就是生成分镜图。
生成分镜图
我们继续刚刚与豆包的对话,你可以让他根据文生图提示词,一次性批量生成所有的分镜图,这样你就可以得到一整套完整的分镜镜头,完全对应之前写好的分镜脚本。

豆包的文生图模型和即梦3.0用的是同一个底模,它的优点是上手门槛比较低,然后对中文理解能力比较强。但如果你追求更专业的效果,比如更写实、更具风格化或者是更好的人物风格一致性,那我推荐你使用Midjourney V7或者是Flux Kontext。
不过无论你使用的是Midjourney、Flux还是豆包即梦,写好文生图提示词一定是最关键的。
技巧篇
我一共总结了4个文生图提示词的通用技巧,你可以把他用在主流的文生图模型上。
(1.符合物理现实,意思就是你描绘的画面不能违背生活中的基本常识。例如低角度仰拍茶几上的手机屏幕。但是你看最终生成的图却变成了一个竖在茶几上的手机,这看起来非常奇怪,也不是我们想要的效果。
问题就是出在在现实生活中,你是没有办法低角度仰拍的同时又能看清楚屏幕朝上的手机的。这两个物理条件是矛盾的,所以AI为了满足这两个条件,只能强行把手机立起来。那我们换个写法,改成茶几上平放着手机,这个时候你再看生成的图是不是就自然多了。
所以我们要记住一个核心原则,一定要符合现实生活中的物理常识,否则就会得到一个违和怪异的画面。
(2.第一帧永远是静态的。很多人都会搞错,觉得既然要生成视频,那文生图就应该描述动作了。文生图应该描述的是一个瞬间的画面,是静止的那一刻。比如这个案例,提示词写的是男主在医院的走廊中慢慢的前行,时不时回头看头顶的日光灯,忽明忽暗,发出滋滋的声音。这条视频提示词里我们不仅描述了人物的姿态和场景,还加入了连贯的动,甚至连环境的变化都写了。但是最终生成的图只反映了一个静态画面,那就是人物站在走廊里,我们再做个对比,把时不时回头和头顶的日光灯忽明忽暗,发出滋滋声这两句删掉,你会发现生成的画面效果没有任何影响。这就说明在分镜图中描述动作是没有意义的。所以你要记住,分镜图提示词重点是画面的构图,而不是动作的设计,动作是后面的事情。
(3.相邻的镜头组要切换场景,这是为了避免空间布局上的冲突。比如说第一组镜头发生在废弃的医院门口,那第二组镜头我建议切换到走廊或者是其他场景,不要连续使用两个镜头发生在同一个场景中,因为除非你在ComfyUl里用多ControlNet加IPAdapter,或者是InstantID,再加上Latent回写来做到角色不变,道具不飘,机位连贯。但这一听就很复杂,完全不适合新手。所以就新手而言,让镜头组错开其实是一个不错的方案。
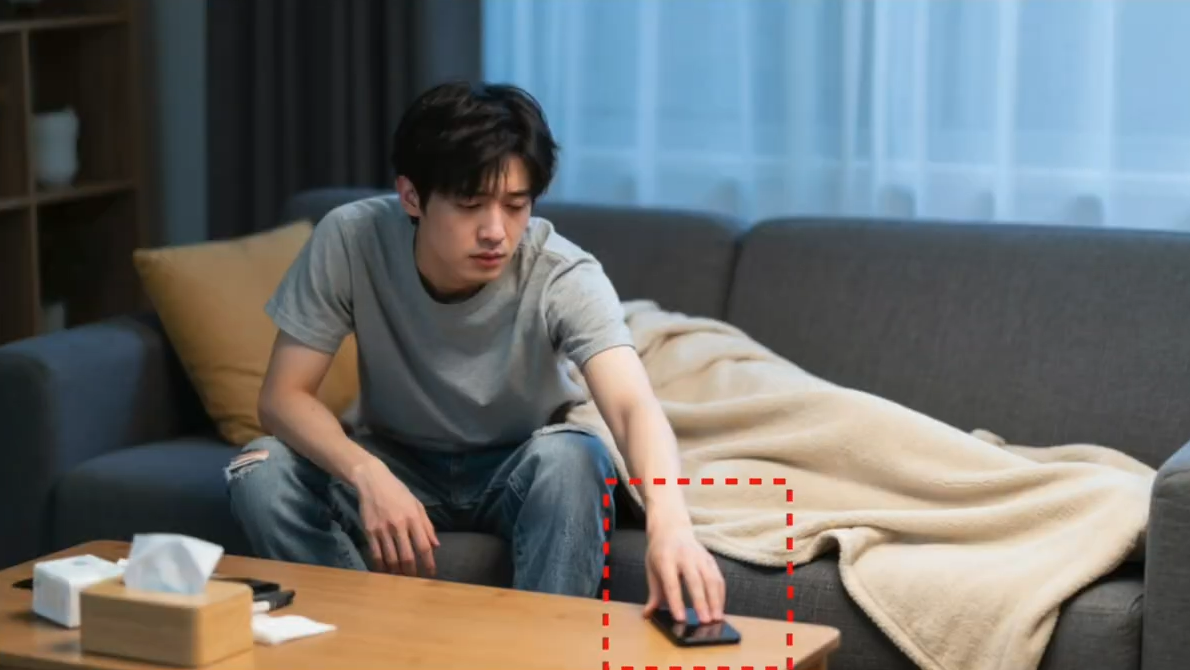
(4.适度的语义模糊,这似乎有点反直觉,但在实际操作中非常有用。比如说我想让男主坐起身去按掉桌上响起的手机闹铃,但是我发现AI会直接生成一个闹钟出现在手机的旁边。
这看起来就很奇怪,那问题就出在我们的提示词里,描述的太细了反而容易让AI误解。其实我们真正想要的只是男主把手伸向手机,仿佛是在按掉手机闹钟的那一刻的画面。所以提示词里干脆我们就把闹钟删掉,这样生成的图你看是不是就自然多了,而且精准的呈现了我们想要的那个画面。
所以当你发现AI老是理解错的时候,我们不妨退后一步,用更宽泛的描述来绕开它的局限。适度的语义模糊反而能帮助你更好的精准控制画面。



现在分镜图我们已经有了,接下来我们就进入到下一步——图生视频,让分镜图动起来。
分镜图转视频
打开即梦,进入到生成页面。首先我们要做的是选择功能,这里选择视频生成
然后我们要选择模型,我使用的是视频3.0,当然这不是唯一的选择,你可以根据你视频的内容选择最合适的模型。接下来上传准备好的首帧分镜图,然后在文本框把分镜图脚本中生成的图生视频提示词贴进去。你也可以加入一些负面提示词,就是那些你不想在画面出现的元素或者情况。比如我不希望出现毁容、面部扭曲、肢体变形等情况。虽然不能完全避免这些问题,但比起不输入,生成效果会明显好一些。然后根据你的镜头组的内容需求,选择生成5秒或者是10秒的视频,点击立即生成就可以了。
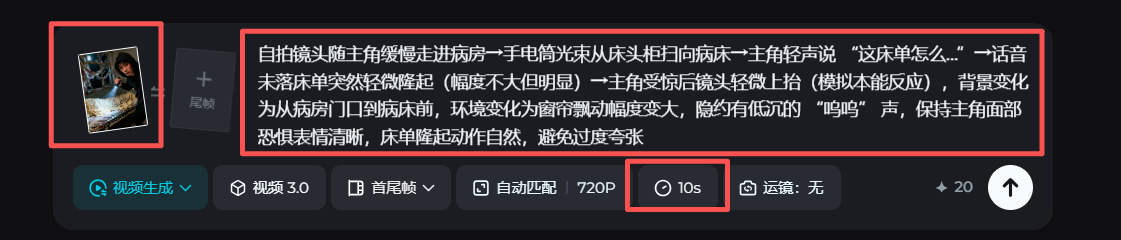
整体效果还是不错的,不过画面还是有一些不稳定,但这就要靠你继续优化提示词,或者是多抽几次卡,总会有一次能让你满意的。
整个视频生成的过程看似非常的简单,但是你多试了几次之后,你就会发现文生图和图生视频的提示词逻辑是完全不同的。首先是静态和动态的区别,文生图关注的是一个静止的画面,它只能呈现第一帧的构图效果,比如人物的站立表情、场景氛围等等。而图生视频则兼备动态的表现力,它可以围绕第一帧向后延伸,形成连续的动作,甚至是镜头与镜头之间的切换。所以理解静态与动态的根本差别是写好图生视频提示词的第一步。动态性不仅是人物的动作,还包含镜头的推进、切换、转向等视觉语言,这些都属于动态表现的一部分。另一个不同是描述的动作链要清晰,这点非常关键。要有意识的用然后...立刻...紧接...着这样的连接词,把多个动作自然的串联在一起。比如说自拍视角,人物往前奔跑,然后突然惊讶地抬头看,立刻转身回望,发现身后空无一人之后,紧接着回转身继续前行。这一连串的动作构成了一个完整的行为链,每一步之间要有因果和动机,逻辑连贯,不能跳跃。所以明确的动作链条和逻辑连接词,能让你对视频的节奏和内容的掌控更加的精准,特别是可以降低抽卡的次数。
为什么要提到降低抽卡次数呢?这涉及到了另一个非常关键的问题——视频成本。目前AI生成视频的价格真的太贵了,我们以即梦和可灵两个主流平台为例,使用即梦3.0pro模型生成一条10秒钟的视频需要消耗100积分,也就是十块钱。而在可灵上如果使用的是2.1大师版本模型,同样是10秒钟的视频,则需要消耗200灵感值,也就是20块钱。
但是这还只是单次的价格,在实际操作中你往往不是一次就能生成满意的结果。以目前的平均情况来看,即便是提示词写的比较熟练,而且运气不错的用户,也需要大概尝试是五次左右才能生成一条满意的视频,成片几率为20%,而对于新手来说,可能需要抽十次甚至更多,成片几率直接降到了1%到5%,而且刚才我们说的这些成本还只是10秒钟的生成费用,而一条完整的AI短剧平均是在3分钟到5分钟之间,我们就按照三分钟为例,一个熟练的老手仅在视频生成这个环节可能就会花费1800到2000块钱左右。而这个数字还不包括后期的人工营销设计、字幕处理等附加成本。所以AI生成视频目前对于C端用户来说是一件非常贵的事情。也正是因为如此,写好剧本,写好提示词,降低抽卡次数就成了整个环节控制成本的关键。因为它不仅能帮你生成更好的视频内容,更重要的是它可以直接帮你省钱。
视频生成之后,接下来就是最后一步了,对口型和生成音效。
对口型及音效
我在这一步用的是即梦。用即梦对口型也是非常简单的,点中需要处理的素材,然后在右侧的画面设置区域找到对口型

接着选择你要使用的音色。这里你可以选择创建角色,上传自己的声音,这个功能可以快速克隆你自己的声音,比较适合制作数字人,能够保留你声音的风格和语气。或者你也可以直接使用即梦的内置多种音色,这种方式比较快,但是我觉得效果一般。系统会自动对视频中的人物进行口型同步,基本上可以很好的对应嘴型。

接下来是为素材生成音效。我这里使用的是剪映。在剪映的左上角找到音频,然后选择音效库,选择合适的音效。
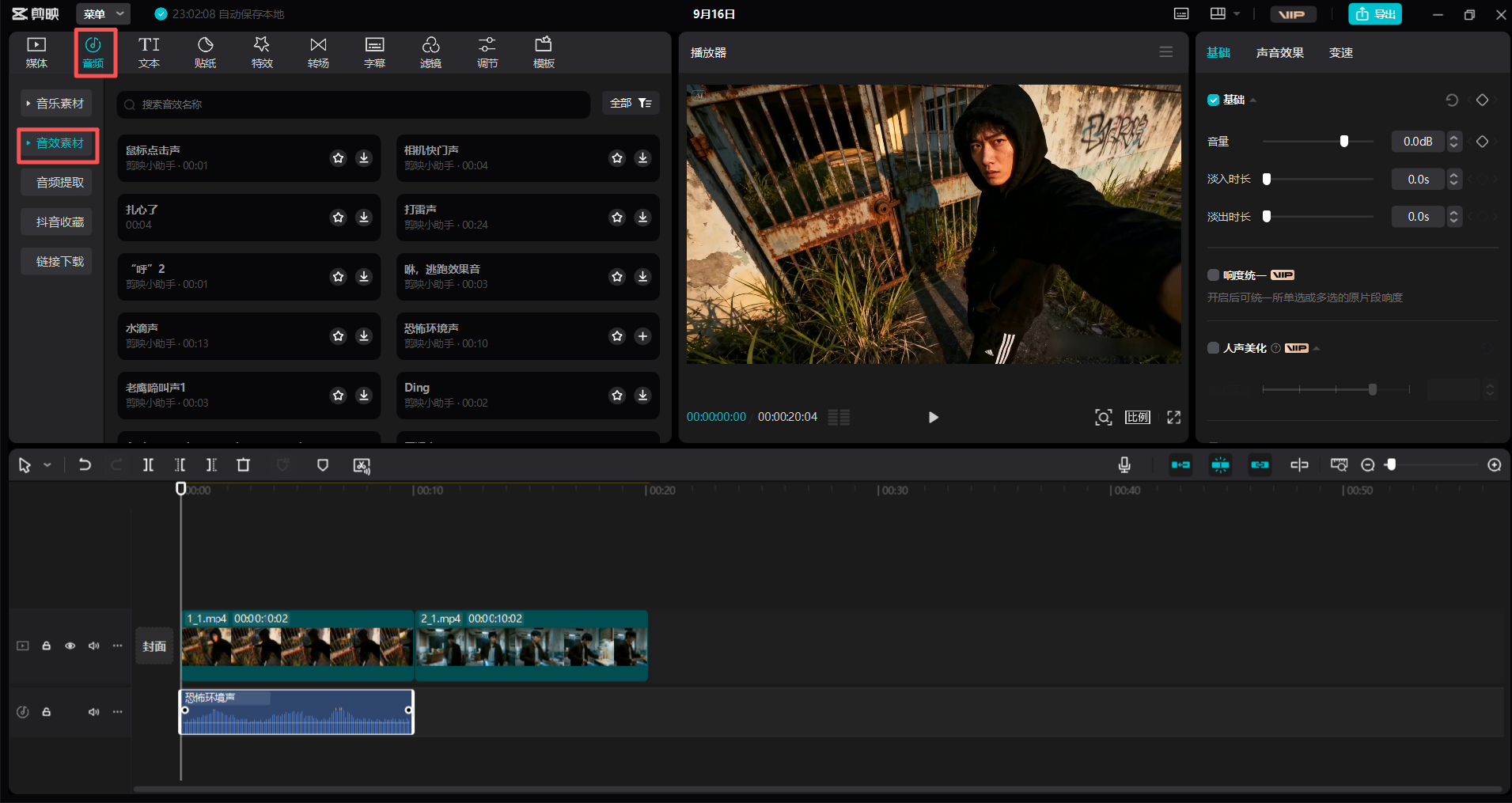
当然你也可以使用即梦的ai音效,它会根据你的视频内容生成相应的ai音效。

如果你想更快捷的话,可以使用剪映的AI对口型和AI音效。目前剪映的AI功能已经足够应付大部分场景了,这个就看你自己觉得怎么方便了。
总结
整个AI短剧制作流程就是这样了。我们回顾一下,先用豆包做基础的分镜,然后继续用豆包或者是Midjourney、即梦、可灵等生成分镜图,接着用可灵或者即梦把分镜生成视频,最后用剪映对口型和添加音效。每个环节都有技巧,但是核心就是前面我们讲过的那些要点。多练习几次,我相信你很快就能做出你的第一条视频了。如果对你有帮助,别忘了给文章点个赞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号