

pyinstaller打包python源程序访问hive
1.需求
使用hvie server一段时间后,业务部门需要自己不定时的查询业务数据,之前这一块都是他们提需求我们来做,后来发现这样重复一样的工作放在我们这边做是在没有效率,遂提出给他们工具或者web UI自助查询,当然hive有自己的hwi可以通过网页UI进行自助查询,但是这对不懂sql的业务人员有点不太友好,目前有没时间去修改hwi的UI,所以还是给他们提供查询工具吧。我这边主要使用python thrift访问集群的hive,所以自然要将python源码打包成.exe,业务人员在windows环境下双击该应用程序,输入参数回车后即可查询hive数据。
2.python thrift访问hive示例代码如下(connectHive.py):
#-*-encoding: utf-8-*- ''' Created on 2014年2月19日 @author: jxw ''' import sys from hive_service import ThriftHive from hive_service.ttypes import HiveServerException from thrift import Thrift from thrift.transport import TSocket from thrift.transport import TTransport from thrift.protocol import TBinaryProtocol def hiveExe(sql): try: transport = TSocket.TSocket('192.168.243.128', 10000) transport = TTransport.TBufferedTransport(transport) protocol = TBinaryProtocol.TBinaryProtocol(transport) client = ThriftHive.Client(protocol) transport.open() client.execute(sql) print "The return value is : " #print client.fetchAll() for r in client.fetchAll(): #for w in r.strip().split('\t'): #print w print r print "............" transport.close() except Thrift.TException, tx: print '%s' % (tx.message) if __name__ == '__main__': num = int(raw_input("input top N:")) #print num sql_ctx = "select * from game_log.tab_char_create limit %d" %num #print sql_ctx hiveExe(sql_ctx) s = raw_input("Enter any key to exit.") print s
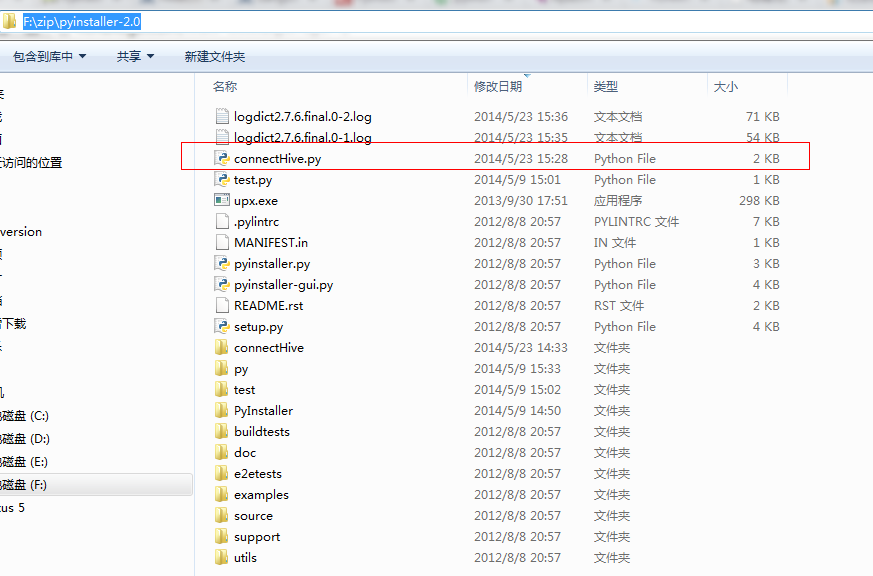
3.从http://www.pyinstaller.org/下载pyinstaller,放在F:\zip目录下并解压,将以上代码copy到该目录下,如下图:
4.打开命令行进入上面的目录,输入以下代码

其中-F表示生成单一的一个可执行文件.exe(会将各种.dll等文件集成一个exe文件);-p代表需要import的包的目录,这里是python使用thrift服务访问hive的包py。
执行完成后会在当前目录下生成一个connectHive的目录,见上图。
5.执行
在connectHive目录下的dist下面有个connectHive.exe,即为需要的执行文件,双击如下:

输入参数后回车,执行结果见下:
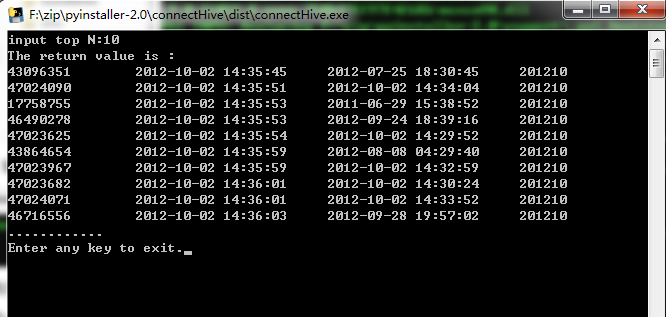
按任意键即可退出。
6.待优化
(1) 将结果序列化进文件,方便业务人员自由处理;
(2) 设置hive query的执行频度,这可以在代码中设置hadoop用户和mapreduce使用的作业队列mapred.job.queue.name,防止集群资源被该业务频繁大规模占用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号