
《深度学习入门-基于Python的理论与实现》读书笔记-03
ch03
1.读入MNIST的图像数据集
使用mnist.py中的load_mnist()函数,就可以按下述方式轻松读入MNIST数据。
import sys, os sys.path.append(os.pardir) # 为了导入父目录中的文件而进行的设定 from dataset.mnist import load_mnist # 第一次调用会花费几分钟 …… (x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False) # 输出各个数据的形状 print(x_train.shape) # (60000, 784) 3.6 手写数字识别 71 print(t_train.shape) # (60000,) print(x_test.shape) # (10000, 784) print(t_test.shape) # (10000,)
实操:
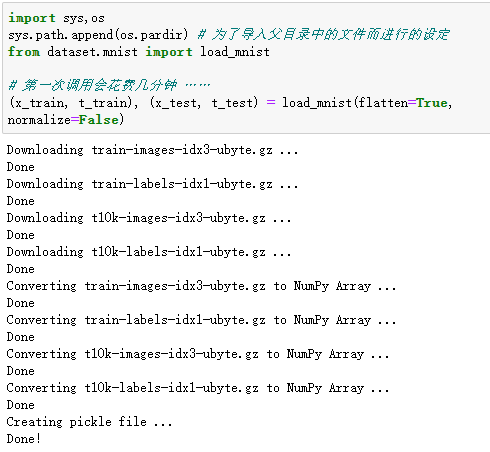

PS:需要在文件夹中导入dataset文件夹
2.显示MNIST图像
图像的显示使用PIL(Python Image Library)模块。显示图像时,需要把它变为原来的28像素 × 28
像素的形状。可以通过reshape()方法的参数指定期望的形状,更改NumPy数组的形状。
import sys, os sys.path.append(os.pardir) import numpy as np from dataset.mnist import load_mnist from PIL import Image def img_show(img): pil_img = Image.fromarray(np.uint8(img)) pil_img.show() (x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False) img = x_train[0] label = t_train[0] print(label) # 5 print(img.shape) # (784,) img = img.reshape(28, 28) # 把图像的形状变成原来的尺寸 print(img.shape) # (28, 28) img_show(img)
实操:
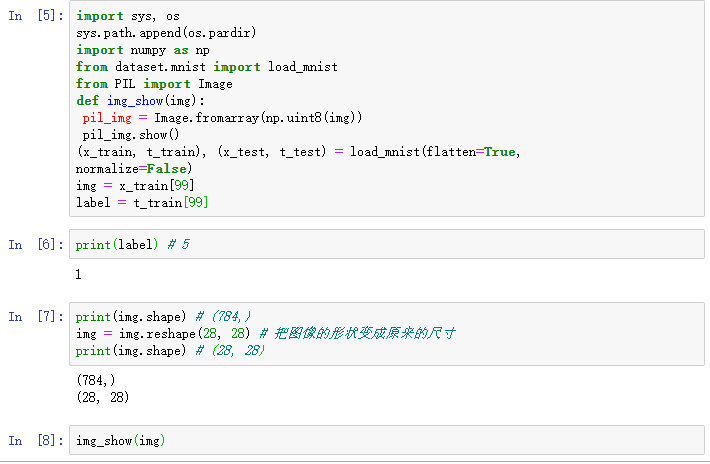

显示训练t_train的结果和训练x_train的图形显示是一致的
3.神经网络的推理处理
输入层的784这个数字来源于图像大小的28 × 28 = 784,输出层的10这个数字来源于10类别分类(数字0到9,共10类别)。
init_network()会读入保存在pickle文件sample_weight.pkl中的学习到的权重参数
predict()函数以NumPy数组的形式输出各个标签对应的概率。比如输出[0.1, 0.3, 0.2, ..., 0.04]的数组
可以用np.argmax(x)函数取出数组中的最大值的索引
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定 import numpy as np import pickle from dataset.mnist import load_mnist from common.functions import sigmoid, softmax def get_data(): (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False) return x_test, t_test def init_network(): with open("sample_weight.pkl", 'rb') as f: network = pickle.load(f) return network def predict(network, x): W1, W2, W3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 z2 = sigmoid(a2) a3 = np.dot(z2, W3) + b3 y = softmax(a3) return y x, t = get_data() network = init_network() accuracy_cnt = 0 for i in range(len(x)): y = predict(network, x[i]) p= np.argmax(y) # 获取概率最高的元素的索引 if p == t[i]: accuracy_cnt += 1 print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
PS:文件夹中没有sample_weight.pkl文件无法运行
4.批处理
批处理对计算机的运算大有利处,可以大幅缩短每张图像的处理时间。
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定 import numpy as np import pickle from dataset.mnist import load_mnist from common.functions import sigmoid, softmax def get_data(): (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False) return x_test, t_test def init_network(): with open("sample_weight.pkl", 'rb') as f: network = pickle.load(f) return network def predict(network, x): w1, w2, w3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] a1 = np.dot(x, w1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, w2) + b2 z2 = sigmoid(a2) a3 = np.dot(z2, w3) + b3 y = softmax(a3) return y x, t = get_data() network = init_network() batch_size = 100 # 批数量 accuracy_cnt = 0 for i in range(0, len(x), batch_size): x_batch = x[i:i+batch_size] y_batch = predict(network, x_batch) p = np.argmax(y_batch, axis=1) accuracy_cnt += np.sum(p == t[i:i+batch_size]) print("Accuracy:" + str(float(accuracy_cnt) / len(x)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号