Deep Structured Generative Models
深度结构化生成模型
摘要
深度生成模型在生成真实图像方面已经显示出了良好的效果,但生成具有复杂结构的图像仍然不是一件容易的事情。主要原因是现有的生成模型大多没有对图像中的结构进行探究,包括空间布局和物体之间的语义关系。为了解决这一问题,我们提出了一种新的深度结构化生成模型,利用结构信息来增强生成对抗网络(GANs)。具体来说,场景的布局或结构采用随机与或图(sAOG)进行编码,其中终端节点表示单个对象,边缘表示对象之间的关系。通过适当地利用sAOG,我们的模型能够成功地捕获场景的内在结构,并相应地生成复杂场景的图像。此外,还引入了一种检测网络来从图像中推断场景结构。实验结果表明,该方法在建模内在结构和生成真实图像方面都是有效的。
1、介绍
深度生成模型(DGMs) (Kingma &威林,2013;Goodfellow等人,2014;Li et al., 2015)在图像生成方面取得了很大的进展。然而,真实的图像具有复杂的内在结构,大多数DGMs通过简单地将随机噪声向量映射到图像空间而不能考虑这些结构。通过明确地结合有效的结构,可以在这些复杂的结构上有条件地生成具有复杂关系的图像。此外,有了这些高度可解释的结构,可以更好地理解场景生成,并可能进行一系列的操作,如移动物体、改变位置等。的确,Mirza & Osindero(2014)和Li等人(2017)在生成模型中引入条件变量作为输入,并有条件地合成图像。但是,使用独热码条件变量远不能在一个复杂的现实图像中建模关系。
图像语法模型(Zhu et al., 2007)为图像结构建模提供了一种有原则的方法,已广泛应用于图像层次场景结构的建模和解析(Zhao &朱,2011)。该模型明确地定义了整个场景的层次结构,从而方便了对象关系的显式建模和特定配置的人类知识的嵌入。通常,一个语法模型从一个代表复杂场景的节点开始,以节点结束,每个节点代表一个单独的对象。生成规则用于定义可视化元素的分层组合,对象之间的关系通过节点之间的边来引入。通过在图上定义概率,语法模型能够成功地捕获复杂场景的结构信息以及不确定性。
然而,语法模型与表达能力相矛盾,也就是说,它很难为每个对象的复杂外观建模。这种无能主要是由于语法模型使用非常低级的视觉原语,如线条(Liu et al., 2014),来呈现复杂的图像。近年来,DGMs技术的巨大进步为桥梁结构模型和真实图像之间的鸿沟提供了一种选择。特别是随着生成对抗网络(GANs)的出现(Goodfellow等人,2014),可以成功生成高分辨率的图像(例如1024 1024)(Karras等人,2017)。
2、背景
在本节中,我们首先简要介绍了随机和或图,然后介绍了深度生成模型和像素到像素的平移。
2.1、随机图像语法
2.2、深度生成模型
近年来,深度生成模型在图像生成方面取得了巨大的进步,其中生成对抗网络(GANs) (Goodfellow等人,2014)显示出强大的能力,可以隐式建模图像数据的分布,并生成真实的图像。在GANs中,发生器(G)将输入噪声传输到数据流形中,试图欺骗鉴别器,鉴别器(D)试图区分样本是否来自数据分布,从而为发生器提供训练信号。因此,目标函数可在极大极小博弈框架下表述为:
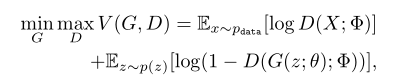
其中,p(z)作为噪声输入一般为标准正态分布,G和D分别为θ和φ参数化的神经网络。G和D都可以用反向传播来训练。在此框架下,生成器可以在达到全局均衡时恢复数据分布。
为了生成复杂的图像,提出了一种基于gan的图像-图像转换方法来有条件地生成图像。在S2-GAN (Wang & Gupta, 2016)中,图像对图像对抗网络以表面法线贴图作为条件,输出另一幅真实图像,其中法线贴图由另一个香草GAN生成,以表示场景的结构。通过使用U-net生成器和卷积鉴别器,pix2pix模型(Isola等人,2017)在更广泛的图像对图像任务中表现良好,包括样式转移和从标签地图或边缘地图重建图像。Pix2pixHD (Wang et al., 2017)在pix2pix中引入了多尺度识别器和实例编码器,从而在实例分割地图的条件下生成高分辨率的真实感图像。除此之外,pix2pixHD还允许用户通过操纵实例地图来编辑图像结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号