监督学习&无监督学习&半监督学习&自监督学习
1、监督学习
监督学习利用大量的标注数据来训练模型,模型的预测和数据的真实标签产生损失(把标签数值化?)后进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。
2、无监督学习
无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。
无监督学习中被广泛采用的方式是自动编码器(autoencoder)。例如,MNIST的60000张0-9的图片,把label摘掉,就是无监督学习的数据,AE生成的伪标签就是x自身。

编码器将输入的样本映射到隐层向量,解码器将这个隐层向量映射回样本空间。我们期待网络的输入和输出可以保持一致(理想情况,无损重构),同时隐层向量的维度远远小于输入样本的维度,以此达到了降维的目的,利用学习到的隐层向量(代替原始的输入样本)再进行聚类等任务时将更加的简单高效。对于如何学习隐层向量的研究,可以称之为表征/表示学习(Representation Learning)。但这种简单的编码-解码结构仍然存在很多问题,基于像素的重构损失通常假设每个像素之间都是独立的,从而降低了它们对相关性或复杂结构进行建模的能力。尤其使用 L1 或 L2 损失来衡量输入和输出之间的差距其实是不存在语义信息的,而过分的关注像素级别的细节而忽略了更为重要的语义特征。对于自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。
参考2作者认为:真正的无监督学习应该不需要任何标注信息,通过挖掘数据本身蕴含的结构或特征,开完成相关任务,大体可以包含三类:1)聚类(k-means,谱聚类等) 2)降维(线性降维:PCA、ICA、LDA、CCA等;非线性降维:ISOMAP、KernelPCA等;2D降维:2D-PCA)3)离散点检测(比如基于高斯分布或多元高斯分布的异常检测算法)。
3、半监督学习
无监督学习只利用未标记的样本集进行学习;
监督学习则只利用标记的样本集进行进行学习。
3.1、半监督的理论概述
半监督有两个样本集,一个有标记,一个没有标记:Labled={(xi,yi)};Unlabled={xj},并且数量上L<<U。
- 单独使用有标记样本,我们能够生产有监督分类算法
- 单独使用无标记样本,我们能够生产无监督聚类算法
- 两者使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样,我们希望在2中加入有标记样本,增强无监督聚类的效果
一般而言,半监督侧重于在有监督的分类算法中加入无标记样本来实现半监督分类,也就是在1中加入无标记样本,增强分类效果。
3.2、motivation
- 有标记样本难以获取:需要专门的人员,特别的设备,额外的开销......
- 无标记的样本相对而言是很廉价的
3.3、半监督学习与直推式学习的区别
3.4、半监督学习算法分类
1、self-training(自训练算法)
2、generative models生成模型
3、SVMs半监督支持向量机
4、graph-based methods图论方法
5、multiview learning 多视角算法
........
1、self-training(自训练算法):
两个样本集合:Labled={(xi,yi)};Unlabled={xj},并且数量上L<<U。
Repeat:
- 用L生成分类策略F;
- 用F分类U,计算误差
- 选取U的子集u,即误差小的,加入标记。L=L+u;
重复上述步骤,直到U为空集。
上面的算法中,L通过不断在U中,选择表现良好的样本加入,并且不断更新子集的算法F,最后得到一个最优的F。
Self-training的一个具体实例:最近邻算法
记d(x1,x2)为两个样本的欧式距离,执行如下算法:
Repeat:
- 用L生成分类策略F;
- 选择x = argmin d(x,x0)。 其中x∈U,min x0∈L。也就是选择离标记样本最近的无标记样本。
- 用F给x定一个类别F(x).
- 把(x,F(x))加入L中
重复上述步骤,直到U为空集.
上面算法中,也就是定义了self-training的”误差最小”,也就是用欧式距离来定义”表现最好的无标记样本”,再用F给个标记,加入L中,并且也动态更新F。
4、自监督学习
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。(也就是说自监督学习的监督信息不是人工标注的,而是算法在大规模无监督数据中自动构造监督信息,来进行监督学习或训练。因此,大多数时候,我们称之为无监督预训练方法或无监督学习方法,严格上讲,他应该叫自监督学习)。
原文作者:自编码器个人认为可以算作无监督学习,也可以算作自监督学习,个人更倾向于后者。不过原文作者把自编码器看作是无监督学习方法,并将其与自监督学习方法相区分,具体区别如上文所示:自编码器,可能仅仅是做了维度的降低而已,我们希望学习的目的不仅仅是维度更低,还可以包含更多的语义特征,让模型懂的输入究竟是什么,从而帮助下游任务。而自监督学习最主要的目的就是学习到更丰富的语义表征。
对于自监督学习来说,存在三个挑战:
- 对于大量的无标签数据,如何进行表征/表示学习?
- 从数据的本身出发,如何设计有效的辅助任务 pretext?
- 对于自监督学习到的表征,如何来评测它的有效性?
对于第三点,评测自监督学习的能力,主要是通过 Pretrain-Fintune 的模式。我们首先回顾下监督学习中的 Pretrain - Finetune 流程:我们首先从大量的有标签数据上进行训练,得到预训练的模型,然后对于新的下游任务(Downstream task),我们将学习到的参数(比如输出层之前的层的参数)进行迁移,在新的有标签任务上进行「微调」,从而得到一个能适应新任务的网络。
自监督的 Pretrain - Finetune 流程:首先从大量的无标签数据中通过 pretext 来训练网络(自动在数据中构造监督信息),得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
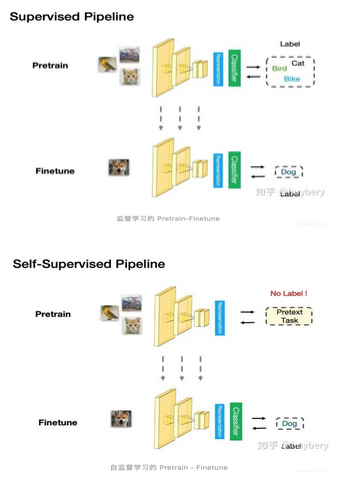
4.1、自监督学习的主要方法
自监督学习的方法主要可以分为 3 类:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
补充1:Pretext task(surrogate task),前置任务,代理任务、辅助任务
Pretext可以理解为是一种为达到特定训练任务而设计的间接任务。比如,我们要训练一个网络来对ImageNet分类,可以表达为 ,我们的目的其实是获得具有语义特征提取/推理能力的
。我们假设有另外一个任务(也就是pretext),它可以近似获得这样的
,比如,Auto-encoder(AE),表示为:
。为什么AE可以近似
呢?因为AE要重建
就必须学习
中的内在关系,而这种内在关系的学习又是有利于我们学习
的。这种方式也叫做预训练,为了在目标任务上获得更好的泛化能力,一般还需要进行fine-tuning等操作。
Pretext任务可以进一步理解为:对目标任务有帮助的辅助任务。而这种任务目前更多的用于所谓的Self-Supervised learning,即一种更加宽泛的无监督学习。这里面涉及到一个很强的动机:训练深度学习需要大量的人工标注的样本,这是费时耗力的。而自监督的提出就是为了打破这种人工标注样本的限制,目的是在没有人工标注的条件下也能高效的训练网络,自监督的核心问题是如何产生伪标签(Pseudo label),而这种伪标签的产生是不涉及人工的,比如上述的AE的伪标签就是 自身。这里举几个在视觉任务里常用的pretext task几种伪标签的产生方式:

1.2 Colorization(图片上色)

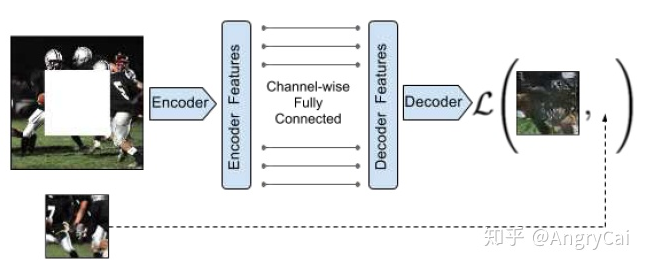
1.4 Jigsaw Puzzle/Context Prediction(关系预测/上下文预测)

补充2:预训练模型
- 预训练模型就意味着把人类的语言知识,先学了一个东西,然后再代入到某个具体任务,就顺手了,就是这么一个简单的道理。
- 预训练的意思就是提前已经给你一些初始化的参数,这个参数不是随机的,而是通过其他类似数据集上面学得的,然后再用你的数据集进行学习,得到适合你数据集的参数,随机初始化的话,的确不容易得到结果,但是这个结果是因为速度太慢,而不是最终的结果不一样。
- 预训练模型就是一些人用某个较大的数据集训练好的模型(这种模型往往比较大,训练需要大量的内存资源),你可以用这些预训练模型用到类似的数据集上进行模型微调。就比如自然语言处理中的bert。
- 已经使用公开数据集训练过的checkpoints,往往这些数据集比较大可以有效的提取特征。
补充3:
参考1:半监督学习(一)
参考2:自监督学习 | (1) Self-supervised Learning入门

 浙公网安备 33010602011771号
浙公网安备 33010602011771号