

论文阅读|Focal loss
原文标题:Focal Loss for Dense Object Detection
概要
目标检测主要有两种主流框架,一级检测器(one-stage)和二级检测器(two-stage),一级检测器,结构简单,速度快,但是准确率却远远比不上二级检测器。作者发现主要原因在于前景和背景这两个类别在样本数量上存在很大的不平衡。作者提出了解决这种不平衡的方法,改进了交叉熵损失,使其对容易分类的样本产生抑制作用,使得损失集中在数量较少的难分类样本上。同时,作者提出了著名的RetinaNet,这个网络不仅速度快,而且精度不比二级检测器低,是个一出色的目标检测网络。
focal loss
一般来讲,如果对一个样本进行分类,这个样本分类很容易,比如说概率为98%,它的损失相应来讲也会很小。但是有一种情况,如果样本中存在极大的不平衡,这个容易分类的样本数量占很大的比例,那么它所产生的损失也会占大部分比例,就会使得难分类的样本占的损失比例较少,使得模型难以训练。
作者由此提出了focal loss,来解决样本不平衡的问题。
$ FL(p_t)=-(1-p_t)^rlog(p_t) $
RetinaNet 网络结构
retinaNet 是一个简单,一致的网络,它有一个主干网络(backbone)以及两个具有特殊任务的子网络。主干网络用来提取特征,有好多现成的,可以直接用。第一个子网络执行分类任务,第二个字网络执行回顾任务。
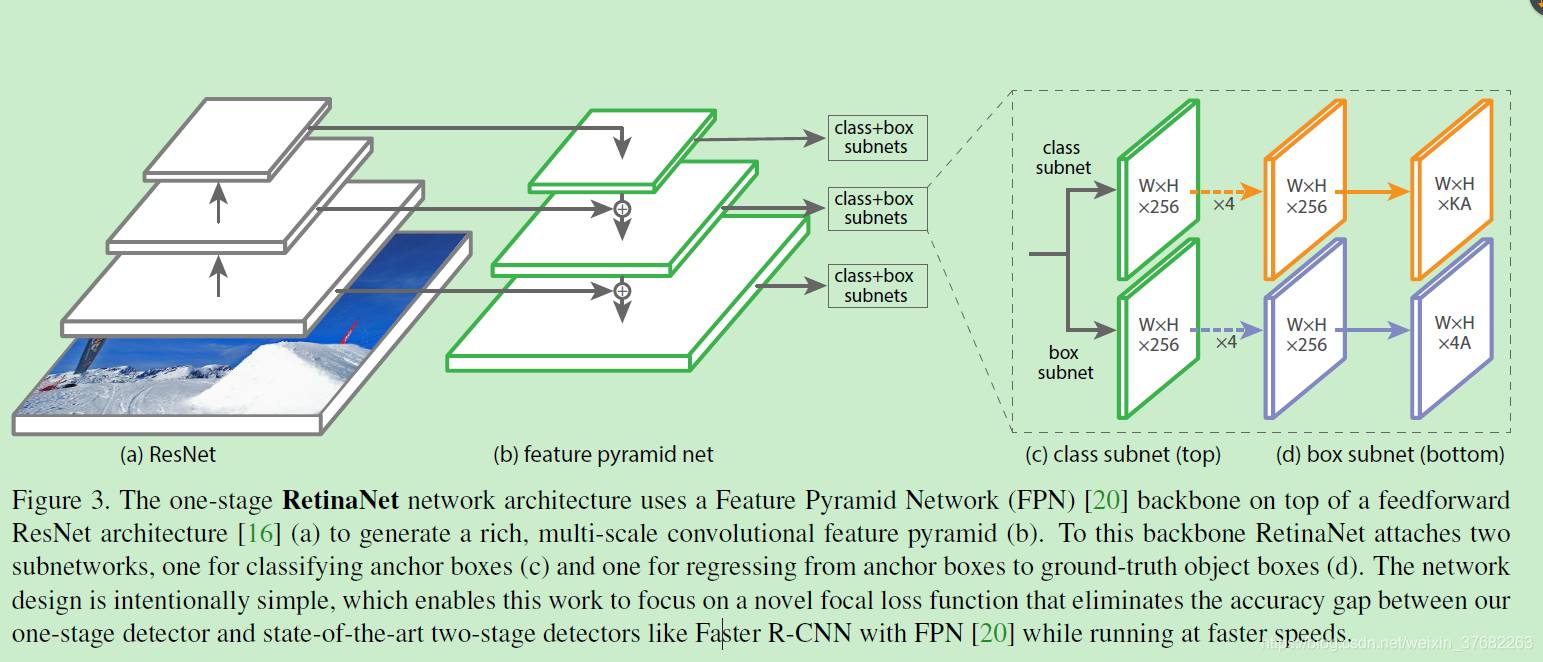
1.backbone
使用了特征金字塔(FPN)作为backbone,它可以提取不同尺度的特征。金字塔的每一层都可以用来检测物体,小特征可以检测大物体,大特征可以检测小物体。
将FPN建立在resnet的基础上,构成了从P3到P7的金字塔,(\(P_l\)比输入的图片尺寸小\(2^l\)倍)。所有的金字塔层,都有256个通道。
2.Anchors
- 使用具有平移不变特性的Anchors。它们的大小从\(32^2\)到\(512^2\),对应P3到P7。Anchors使用3种长宽比,{1:2,1:1,2:1},使用3种大小比例{\(2^0,2^{1/3},2^{2/3}\)}.这样的设置可以提高AP。每个位置中anchor 的个数A= 3X3=9。
- 每个Anchor都会分配一个长度为K的one-hot编码,K是类别的数量,包含背景类。并且分配一个长度为4的向量,代表框子的大小和定位。
- 设置前景是IoU大于0.5的框,背景是IoU小于0.4的框,其他的忽略掉。每个Anchor都有一个one-hot编码,对应类别为1,其他为0.
3.分类子网络
这是一个小的全卷积神经网络,每个空间位置都会产生KA个预测,K是类别数,A是Anchor个数(9)。
注意:只有一个分类子网络,金字塔的所有层都共享这一个网络中的参数。步骤如下:从金字塔中提取出C(256)通道的特征,然后子网络有4个卷积层,每个卷积层都使用3X3的卷积核.最后在跟着一个(KA)通道的卷积层。
4.回归子网络
这也是一个全卷积神经网络,与分类子网络并行存在着,它的任务是对预测框与距离最近的标注框(真实值,如果有的话)进行回归。它在每个空间位置有4A个预测。与其他方式不同,这种回归方式对于分类,是独立的,不可知的。这使用了更少的参数,但是同样有效。
推断与训练
推断
为了提高速度,把阈值设置为0.05,最多使用前1000个最高分的回归框预测。最后融合所有层级的预测结果,使用非极大值抑制,阈值为0.5.
focal loss
r=2的时候效果好,focal loss 将用在每张图片的10万个anchors上,也就是说,focal loss是这10 万个anchor(经过归一化)产生的损失的和。参数a也有一个稳定的范围。这两个参数成反比关系。
初始化
除了最后一个卷积层,所有的卷积层都用b=0,高斯权重0.01.对于最后一个卷积层,b的设置有所不同,这是为了避免在训练开始的时候,出现不稳定现象
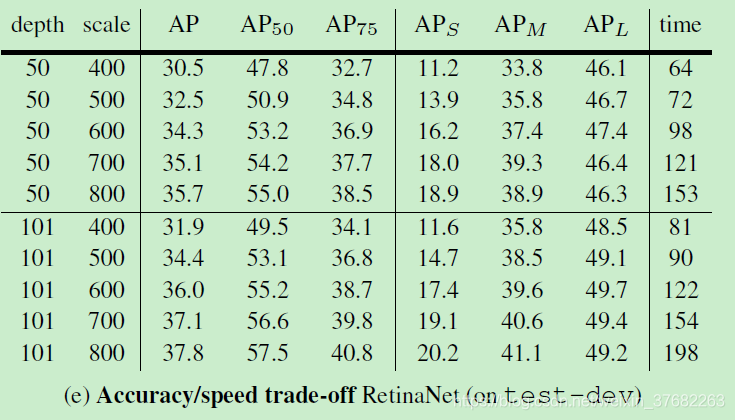
实验结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号