迅雷面经汇总
一、Java
Java四大特征
-
抽象:提取现实世界中某事物的关键特性,为该事物构建模型的过程。对同一事物在不同的需求下,需要提取的特性可能不一样。得到的抽象模型中一般包含:属性(数据)和操作(行为)。这个抽象模型我们称之为类。对类进行实例化得到对象。
-
封装:封装可以使类具有独立性和隔离性;保证类的高内聚。只暴露给类外部或者子类必须的属性和操作。类封装的实现依赖类的修饰符(public、protected和private等)
-
继承:对现有类的一种复用机制。一个类如果继承现有的类,则这个类将拥有被继承类的所有非私有特性(属性和操作)。这里指的继承包含:类的继承和接口的实现。
-
多态:多态是在继承的基础上实现的。多态的三个要素:继承、重写和父类引用指向子类对象。父类引用指向不同的子类对象时,调用相同的方法,呈现出不同的行为;就是类多态特性。多态可以分成编译时多态和运行时多态。
多态的原理
实现多态的技术称为 :动态绑定,是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
类引用调用:Java编译器将Java源代码编译成class文件,在编译过程中,会根据静态类型将调用的符号引用写到class文件中。在执行时,JVM根据class文件找到调用方法的符号引用,然后在静态类型的方法表中找到偏移量,然后根据this指针确定对象的实际类型,使用实际类型的方法表,偏移量跟静态类型中方法表的偏移量一样,如果在实际类型的方法表中找到该方法,则直接调用,否则,认为没有重写父类该方法。按照继承关系从下往上搜索。
接口引用调用:Java 对于接口方法的调用是采用搜索方法表的方式。
ArrayList与LinkedList的区别
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
Java线程间怎么实现同步,notify()与notifyAll()的区别
Java提供了很多同步操作,比如synchronized关键字、wait/notifyAll、ReentrantLock、Condition、一些并发包下的工具类、Semaphore,ThreadLocal、AbstractQueuedSynchronizer等。
notify():
唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。
notifyAll():
唤醒在此对象监视器上等待的所有线程。线程通过调用其中一个 wait 方法,在对象的监视器上等待。
什么是函数重载,原理是什么?
写生产者消费者模型
java里面的final关键字,JDK有什么类是final的吗
- 数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
对于基本类型,final 使数值不变;
对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
- 方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
- 类
声明类不允许被继承。
jdk的所有包装类都是funal修饰的。
Java里面的多线程讲一下
二、JVM
JVM框架
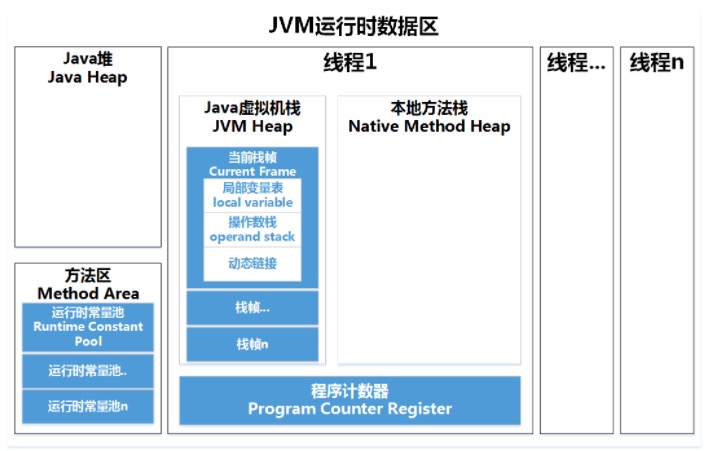
程序计数器:记录正在执行的虚拟机字节码指令的地址(如果正在执行的是本地方法则为空)。
Java虚拟机栈:每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
本地方法栈:与 Java 虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
Java堆:几乎所有对象实例都在这里分配内存。是垃圾收集的主要区域("GC 堆"),虚拟机把 Java 堆分成以下三块:
- 新生代
- 老年代
- 永久代
新生代又可细分为Eden空间、From Survivor空间、To Survivor空间,默认比例为8:1:1。
方法区:方法区(Method Area)与Java堆一样,是各个线程共享的内存区域。Object Class Data(类定义数据)是存储在方法区的,此外,常量、静态变量、JIT编译后的代码也存储在方法区。
运行时常量池:运行时常量池是方法区的一部分。Class 文件中的常量池(编译器生成的各种字面量和符号引用)会在类加载后被放入这个区域。除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern()。这部分常量也会被放入运行时常量池。
直接内存:直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError 异常出现。避免在Java堆和Native堆中来回复制数据。
JVM类加载
类加载的过程主要分为三个部分:
- 加载:指的是把class字节码文件从各个来源通过类加载器装载入内存中。
- 链接
- 初始化:对类变量初始化,是执行类构造器的过程。
链接又可以细分为
- 验证:为了保证加载进来的字节流符合虚拟机规范,不会造成安全错误。
- 准备:为类变量(注意,不是实例变量)分配内存,并且赋予初值。
- 解析:将常量池内的符号引用替换为直接引用的过程。
JVM垃圾回收算法
垃圾回收算法包括:标记-清除算法,复制算法,标记-整理算法,分代收集算法。
标记—清除算法:
标记/清除算法,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
标记阶段:标记的过程其实就是前面介绍的可达性分析算法的过程,遍历所有的GC Roots对象,对从GC Roots对象可达的对象都打上一个标识,一般是在对象的header中,将其记录为可达对象;
清除阶段:清除的过程是对堆内存进行遍历,如果发现某个对象没有被标记为可达对象,则将其回收。

复制算法:
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
将内存分为一块较大的 Eden 空间和两块较小的 Survior 空间,每次使用 Eden 空间和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象一次性复制到另一块 Survivor 空间上,最后清理 Eden 和 使用过的那一块 Survivor。HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1,保证了内存的利用率达到 90 %。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 空间就不够用了,此时需要依赖于老年代进行分配担保,也就是借用老年代的空间。

标记—整理算法:
标记—整理算法和标记—清除算法一样,但是标记—整理算法不是把存活对象复制到另一块内存,而是把存活对象往内存的一端移动,然后直接回收边界以外的内存,因此其不会产生内存碎片。标记—整理算法提高了内存的利用率,并且它适合在收集对象存活时间较长的老年代。

分代收集算法:
分代回收算法实际上是把复制算法和标记整理法的结合,并不是真正一个新的算法,一般分为:老年代和新生代,老年代就是很少垃圾需要进行回收的,新生代就是有很多的内存空间需要回收,所以不同代就采用不同的回收算法,以此来达到高效的回收算法。
新生代:由于新生代产生很多临时对象,大量对象需要进行回收,所以采用复制算法是最高效的。
老年代:回收的对象很少,都是经过几次标记后都不是可回收的状态转移到老年代的,所以仅有少量对象需要回收,故采用标记清除或者标记整理算法。
三、数据结构与算法
堆和栈
手写二分查找
public boolean Find(int target, int[][] array) {
if (array == null || array.length == 0 || (array.length == 1 && array[0].length == 0)) return false;
for (int i = 0; i < array.length; i++) {
int begin = 0;
int end = array[0].length - 1;
while (begin <= end) {
int mid = (begin + end) / 2;
if (target > array[i][mid]) {
begin = mid + 1;
} else if (target < array[i][mid]) {
end = mid - 1;
} else {
return true;
}
}
}
return false;
}
二分法查找次数,100个数最多查找多少次?
20G大小的数据,但是内存也就10G,如何对20G数据排序?
手写冒泡
/**
* 冒泡排序
*
* @param array
*/
private static void bubbleSort(int[] array) {
if (array == null || array.length == 0 || array.length == 1)
return;
for (int i = 0; i < array.length - 1; i++) {
for (int j = 0; j < array.length - 1 - i; j++) {//注意数组边界
if (array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
private static void bubbleSort(int[] array) {
if (array == null || array.length == 0 || array.length == 1)
return;
boolean flag = true;//发生了交换就为true, 没发生就为false,第一次判断时必须标志位true
int k = array.length - 1;
int pos = 0;//pos变量用来标记循环里最后一次交换的位置
for (int i = 0; i < array.length - 1; i++) {
flag = false;//每次开始排序前,都设置flag为未排序过
for (int j = 0; j < k; j++) {//注意数组边界
if (array[j] > array[j + 1]) {
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
flag = true;//表示交换过数据;
pos = j;
}
}
k = pos;
//判断标志位是否为false,如果为false,说明后面的元素已经有序,就直接return
if (flag == false)
return;
}
}
写一个后序遍历
四、操作系统
死锁,如何避免死锁
如果一个进程集合里面的每个进程都在等待只能由这个集合中的其他一个进程(包括他自身)才能引发的事件,这种情况就是死锁。
避免死锁:
- 安全状态
- 单个资源的银行家算法
- 多个资源的银行家算法
线程与进程的区别
进程:进程是操作系统资源分配的基本单位。每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1–n个线程。
线程:线程是CPU独立调度的基本单位。同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。
线程和进程的生命周期:新建、就绪、运行、阻塞、死亡
进程间通信
- 消息传递
- 管道
- 消息队列
- 套接字
- 共享内存
进程状态的切换图

五、网络
osi七层模型

| OSI七层网络模型 | 对应网络协议 |
|---|---|
| 应用层 | HTTP、TFTP、FTP、NFS、WAIS、SMTP |
| 表示层 | Telnet、Rlogin、SNMP、Gopher |
| 会话层 | SMTP、DNS |
| 传输层 | TCP、UDP |
| 网络层 | IP、ICMP、ARP、RARP、AKP、UUCP |
| 数据链路层 | FDDI、Ethernet、Arpanet、PDN、SLIP、PPP |
| 物理层 | IEEE 802.1A、IEEE 802.2到IEEE 802.11 |
传输层有哪些协议
tcp、udp
断网的时候,tcp和udp能检测到吗?
tcp 三次握手
所谓三次握手(Three-Way Handshake)即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。整个流程如下图所示:

- 第一次握手:Client将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给Server,Client进入SYN_SENT状态,等待Server确认。
- 第二次握手:Server收到数据包后由标志位SYN=1知道Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,并将该数据包发送给Client以确认连接请求,Server进入SYN_RCVD状态。
- 第三次握手:Client收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给Server,Server检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client与Server之间可以开始传输数据了。
三次握手中accept函数处于第几次
三次握手完成后,客户端和服务器就建立了tcp连接。这时可以调用accept函数获得此连接。
http 的工作原理
HTTP协议 :Hyper Text Transfer Protocol(超文本传输协议),是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
TCP与UDP的区别
TCP:面向连接,提供可靠的服务,有流量控制,拥塞控制,无重复、无丢失、无差错,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),只能是点对点,首部 20 字节,全双工。
UDP:无连接,尽最大努力交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对多,首部 8 字节。
TCP拥塞机制
TCP滑动窗口
GET,POST和PUT的区别
http1.0、http1.1、http2
HTTP/1.0:
- 请求与响应支持头域
- 响应对象以一个响应状态行开始
- 响应对象不只限于超文本
- 开始支持客户端通过POST方法向Web服务器提交数据,支持GET、HEAD、POST方法
- 支持长连接(但默认还是使用短连接),缓存机制,以及身份认证
HTTP/1.1:
- 默认为长连接
- 提供了范围请求功能(宽带优化)
- 提供了虚拟主机的功能(HOST域)
- 多了一些缓存处理字段
- 错误通知的管理
HTTP/2.0:
- 二进制分帧
- 多路复用
- 头部压缩
- 请求优先级
- 服务端推送
http1.1中的keep-alive是怎么理解的?
HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成 之后立即断开连接(HTTP协议为无连接的协议);当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
输入了一个URL之后发生了什么
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
六、设计模式
手写单例
public class Singleton {
private volatile static Singleton instance = null;
private Singleton() {
}
/**
* 当第一次调用getInstance()方法时,instance为空,同步操作,保证多线程实例唯一
* 当第一次后调用getInstance()方法时,instance不为空,不进入同步代码块,减少了不必要的同步
*/
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号