

利用yacc和lex制作一个小的计算器
买了本《自制编程语言》,这本书有点难,目前只是看前两章,估计后面的章节,最近一段时间是不会看了,真的是好难啊!!
由于本人是身处弱校,学校的课程没有编译原理这一门课,所以就想看这两章,了解一下编译原理,增加一下自己的软实力。免得被别人鄙视。
一、安装yacc和lex
我是在Windows下使用这两个软件的。所以使用bison代替yacc,用flex代替lex。两者的下载地址是http://sourceforge.net/projects/winflexbison/ 我的gcc环境是使用以前用过的mingw。我们吧解压后的flex和bison放到mingw的bin目录下。这一步就完成了。
二、编译代码
先编译代码,看一下结果,然后在分析。在这本书中提供的一个网址有书中代码下载。下载地址 http://avnpc.com/pages/devlang 下载后找到mycalc这个文件夹。然后执行下面进行编译
1 bison --yacc -dv mycalc.y -o y.tab.c 2 flex mycalc.l 3 gcc -o mycalc y.tab.c lex.yy.c
三、yacc/lex是什么
一般编程语言的语法处理,都会有以下的过程。
1.词法分析
将源代码分割成若干个记号的处理。
2.语法分析
即从记号构建分析树的处理。分析树也叫作语法树或抽象语法树。
3.语义分析
经过语法分析生成的分析树,并不包含数据类型等语义信息。因此在语义分析阶段,会检查程序中是否含有语法正确但是存在逻辑问题的错误。
4.生成代码
如果是C语言等生成机器码的编译器或Java这样生成字节码的编译器,在分析树构建完毕后会进入代码生成阶段。
例如有下面源代码
1 if(a==10) 2 { 3 printf("hoge\n"); 4 } 5 else 6 { 7 printf("piyo\n"); 8 }
执行词法分析后,将被分割为如下的记号(每一块就是一个记号)
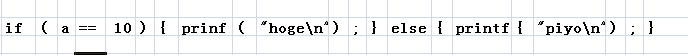
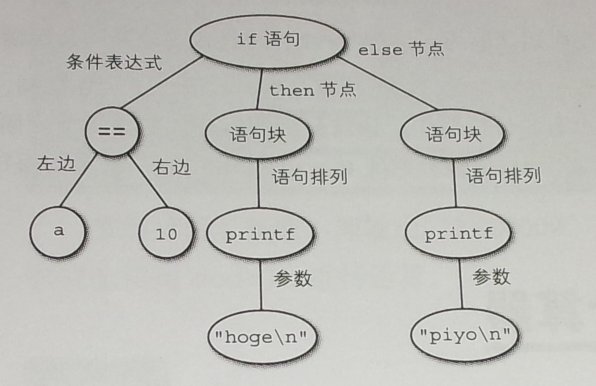
对此进行语法分析后构建的分析树,如下图所示
执行词法分析的程序称为词法分析器。lex的工作就是根据词法规则自动生成词法分析器。
执行语法分析的程序则称为解析器。yacc就是根据语法规则自动生成解析器的程序。
四、分析计算器代码
1.mycalc.l源代码
1 %{ 2 #include <stdio.h> 3 #include "y.tab.h" 4 5 int 6 yywrap(void) 7 { 8 return 1; 9 } 10 %} 11 %% 12 "+" return ADD; 13 "-" return SUB; 14 "*" return MUL; 15 "/" return DIV; 16 "\n" return CR; 17 ([1-9][0-9]*)|0|([0-9]+\.[0-9]*) { 18 double temp; 19 sscanf(yytext, "%lf", &temp); 20 yylval.double_value = temp; 21 return DOUBLE_LITERAL; 22 } 23 [ \t] ; 24 . { 25 fprintf(stderr, "lexical error.\n"); 26 exit(1); 27 } 28 %%
第一行到第十行是一个定义区块,lex中用 %{...}%定义,这里面代码将原样输出。
第11行到第28行是一个规则区块。语法大概就是前面一部分是使用正则表达式后面一部分是返回匹配到后这一部分是类型标记。大括号里面是动作。例如 ([1-9][0-9]*)|0|([0-9]+\.[0-9]*)是匹配小数,然后对这个小数进行sscanf处理后返回一个DOUBLE_LITERAL类型。
2.mycalc.y 源代码
1 %{ 2 #include <stdio.h> 3 #include <stdlib.h> 4 #define YYDEBUG 1 5 %} 6 %union { 7 int int_value; 8 double double_value; 9 } 10 %token <double_value> DOUBLE_LITERAL 11 %token ADD SUB MUL DIV CR 12 %type <double_value> expression term primary_expression 13 %% 14 line_list 15 : line 16 | line_list line 17 ; 18 line 19 : expression CR 20 { 21 printf(">>%lf\n", $1); 22 } 23 expression 24 : term 25 | expression ADD term 26 { 27 $$ = $1 + $3; 28 } 29 | expression SUB term 30 { 31 $$ = $1 - $3; 32 } 33 ; 34 term 35 : primary_expression 36 | term MUL primary_expression 37 { 38 $$ = $1 * $3; 39 } 40 | term DIV primary_expression 41 { 42 $$ = $1 / $3; 43 } 44 ; 45 primary_expression 46 : DOUBLE_LITERAL 47 ; 48 %% 49 int 50 yyerror(char const *str) 51 { 52 extern char *yytext; 53 fprintf(stderr, "parser error near %s\n", yytext); 54 return 0; 55 } 56 57 int main(void) 58 { 59 extern int yyparse(void); 60 extern FILE *yyin; 61 62 yyin = stdin; 63 if (yyparse()) { 64 fprintf(stderr, "Error ! Error ! Error !\n"); 65 exit(1); 66 } 67 }
上面第13行到第48行,语法规则简化为下面格式
A : B C | D ;
即A的定义是B与C的组合,或者为D。
上面的过程可以用一个游戏的方式解释。就是一个数字是定位为DOUBLE_LITERAL类型,通过第45行的规则可以将DOUBLE_LITERAL升级成primary_expression类型,然后通过34行规则可以升级为term类型。又term类型可以升级为expression类型。所以 “2+4” 符合的规则是数字2升级到expression类型,而当数字4升级到term类型时,此时的状态是 expression ADD term 通过第25行的规则可以得到两者的结合,得到一个term类型。(PS:这个时候让我想起了一个动漫,就是数码宝贝,类型可以进行进化,进化,超进化,究极进化,还可以合体进化。<笑>)上面一个专业的叫法是叫做归约。
由于归约情况比较复杂和不好讲,我就截书本上的原图进行讲解吧。



至于左结合或右结合是由写的词法分析器来决定的。例如给出的代码,为什么是右结合呢,是因为用到了递归,所以会首先和低级的类型进行结合,这就是为什么MUL,DIV是term类型,ADD,SUB是expression类型,就是处理优先级的问题。
对于C或Java有这样的一个问题
a+++++b;
我们可以分析为a++ + ++b 为什么编译器还会报错呢?是因为我们如果定义优先级的话,++优先级大于+。那么在代码中就是实现为尽量使++在一起,而不是+优先,如果是+优先的话,那么每次都不会结合为++。所以代码在词法分析器阶段代码就会被分割成a ++ ++ + b ;这样几段。从而错误的。由于词法分析器和解析器是各自独立的。又因为词法分析器先于语法分析器运行。
上面的过程就是这样进行语法分析的。上面的过程虽然简单,但是如果用代码实现就有点困难了。我们使用yacc生成的执行文件就是对上面模拟的执行代码,使用yacc自动生成的。如果我们要自制编程语言的话,那么这个过程就要自己写了。因为有很多细节问题。不过不多说了,我们先了解这个就行。生成后的代码文件是y.tab.c y.tab.h 。生成的代码有几十K呢,我们要了解这个过程还是比较难的。
五、用代码实现词法分析器
该代码在calc/llparser目录下
lexicalanalyzer.c


1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <ctype.h> 4 #include "token.h" 5 6 static char *st_line; 7 static int st_line_pos; 8 9 typedef enum { 10 INITIAL_STATUS, 11 IN_INT_PART_STATUS, 12 DOT_STATUS, 13 IN_FRAC_PART_STATUS 14 } LexerStatus; 15 16 void 17 get_token(Token *token) 18 { 19 int out_pos = 0; 20 LexerStatus status = INITIAL_STATUS; 21 char current_char; 22 23 token->kind = BAD_TOKEN; 24 while (st_line[st_line_pos] != '\0') { 25 current_char = st_line[st_line_pos]; 26 if ((status == IN_INT_PART_STATUS || status == IN_FRAC_PART_STATUS) 27 && !isdigit(current_char) && current_char != '.') { 28 token->kind = NUMBER_TOKEN; 29 sscanf(token->str, "%lf", &token->value); 30 return; 31 } 32 if (isspace(current_char)) { 33 if (current_char == '\n') { 34 token->kind = END_OF_LINE_TOKEN; 35 return; 36 } 37 st_line_pos++; 38 continue; 39 } 40 41 if (out_pos >= MAX_TOKEN_SIZE-1) { 42 fprintf(stderr, "token too long.\n"); 43 exit(1); 44 } 45 token->str[out_pos] = st_line[st_line_pos]; 46 st_line_pos++; 47 out_pos++; 48 token->str[out_pos] = '\0'; 49 50 if (current_char == '+') { 51 token->kind = ADD_OPERATOR_TOKEN; 52 return; 53 } else if (current_char == '-') { 54 token->kind = SUB_OPERATOR_TOKEN; 55 return; 56 } else if (current_char == '*') { 57 token->kind = MUL_OPERATOR_TOKEN; 58 return; 59 } else if (current_char == '/') { 60 token->kind = DIV_OPERATOR_TOKEN; 61 return; 62 } else if (isdigit(current_char)) { 63 if (status == INITIAL_STATUS) { 64 status = IN_INT_PART_STATUS; 65 } else if (status == DOT_STATUS) { 66 status = IN_FRAC_PART_STATUS; 67 } 68 } else if (current_char == '.') { 69 if (status == IN_INT_PART_STATUS) { 70 status = DOT_STATUS; 71 } else { 72 fprintf(stderr, "syntax error.\n"); 73 exit(1); 74 } 75 } else { 76 fprintf(stderr, "bad character(%c)\n", current_char); 77 exit(1); 78 } 79 } 80 } 81 82 void 83 set_line(char *line) 84 { 85 st_line = line; 86 st_line_pos = 0; 87 } 88 89 #if 1 90 void 91 parse_line(char *buf) 92 { 93 Token token; 94 95 set_line(buf); 96 97 for (;;) { 98 get_token(&token); 99 if (token.kind == END_OF_LINE_TOKEN) { 100 break; 101 } else { 102 printf("kind..%d, str..%s\n", token.kind, token.str); 103 } 104 } 105 } 106 107 int 108 main(int argc, char **argv) 109 { 110 char buf[1024]; 111 112 while (fgets(buf, 1024, stdin) != NULL) { 113 parse_line(buf); 114 } 115 116 return 0; 117 } 118 #endif
token.h
1 #ifndef TOKEN_H_INCLUDED 2 #define TOKEN_H_INCLUDED 3 4 typedef enum { 5 BAD_TOKEN, 6 NUMBER_TOKEN, 7 ADD_OPERATOR_TOKEN, 8 SUB_OPERATOR_TOKEN, 9 MUL_OPERATOR_TOKEN, 10 DIV_OPERATOR_TOKEN, 11 END_OF_LINE_TOKEN 12 } TokenKind; 13 14 #define MAX_TOKEN_SIZE (100) 15 16 typedef struct { 17 TokenKind kind; 18 double value; 19 char str[MAX_TOKEN_SIZE]; 20 } Token; 21 22 void set_line(char *line); 23 void get_token(Token *token); 24 25 #endif /* TOKEN_H_INCLUDED */
上面使用的方法是DFA(确定有限状态自动机)
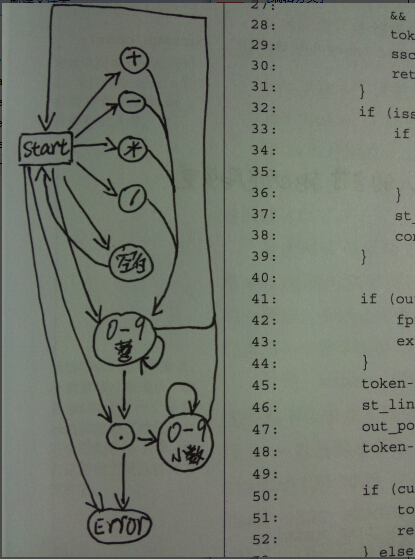
上面的图有些指向error的箭头没有标出,不过这个图就大概描述了这个过程。可以自己baidu一些状态机的知识。
有了这两章的基础就可以自己写个分析器了(作用:以后写应用程序时,要给程序一个配置文件时,可以自己写个脚本进行解析,方便用户书写配置文件。不过现在都使用xml语法了,都还有解析的库呢。都不知道学了以后还有没有机会用到实际中呢)。不过循环和判断就还不能实现。书中后面有讲到,不过看到后面一些内容就有一些力不从心了。感觉难难哒!
|
作者:无脑仔的小明 出处:http://www.cnblogs.com/wunaozai/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 如果文中有什么错误,欢迎指出。以免更多的人被误导。有需要沟通的,可以站内私信,文章留言,或者关注“无脑仔的小明”公众号私信我。一定尽力回答。 |
