

第三章学习小结
总结一下第三章学到的知识:
栈
栈作为一种数据结构,是一种只能在一端进行插入和删除操作的特殊线性表。它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。栈具有记忆作用,对栈的插入与删除操作中,不需要改变栈底指针。

栈是一种线性表,所以栈也有线性表的两种存储结构(顺序存储结构和链式存储结构)。
栈的顺序存储结构称为链栈,链式存储结构称为链栈。
顺序栈
利用一组地址连续的存储单元依次存放栈底到栈顶的数据元素,栈底位置固定不变,栈顶位置随着入栈和出栈操作而变化。
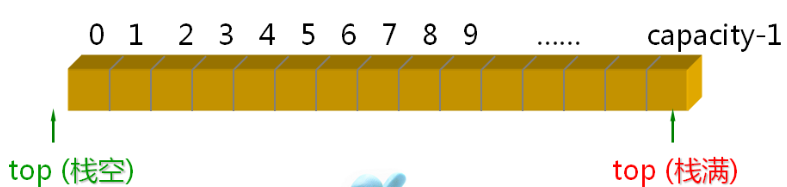
我先定义一个顺序栈:
typedef struct
{
STACK_ELEMENT_TYPE elem[STACK_SIZE];//定义一个数组来存放栈中元素
int top;//用来存放栈顶元素的下标
} SeqStack;
再来看一下顺序栈的几种基本操作:
void InitStack(SeqStack *L)//初始化栈
{
L->top = 0;
}
bool IsEmpty(SeqStack *L)//判断栈空
{
if(L->top == 0)
return true;
else
return false;
}
bool IsFull(SeqStack *L)//判断栈满
{
if(L->top == STACK_SIZE)
return true;
else
return false;
}
void Push(SeqStack *L, ELEMENT_TYPE elem value)//入栈
{
if (IsFull(L) )
{// 栈已满
return;//退出函数
}
// 记得修改栈顶元素下标
L->elem[L->top++] = value;
}
//先判断是否已经满栈,然后移动栈顶元素下标,再将数据放入栈中。
void Pop(SeqStack *L, STACK_ELEMENT_TYPE *value)//出栈
{
if(IsEmpty(L) )
{// 栈为空
return;
}
*value = L->elem[L->top--];// 记得修改栈顶元素下标
}
//先判断栈是否为空,然后将栈顶元素下标对应的数据取出来,移动栈顶元素下标。
STACK_ELEMENT_TYPE GetTop(SeqStack *L)
{
if(IsEmpty(L))
{// 栈为空
return;
}
return L->elem[L->top];
}
//先判断是否栈空,栈非空再返回栈顶元素
emmm...其实上面判断栈空栈满时我只是简单得将其退出函数,并没有做任何其他处理,有谁没事也可以试着改一改,哈哈。
链栈
链栈是一种特殊的线性链表,和所有链表一样,是动态存储结构,无需预先分配存储空间。
链栈的定义:
typedef struct StackNode
{
ElemType data;
struct StackNode *next;
}StackNode, *LinkStack;
emmm...链栈的几种基本操作其实我自我感觉除了语句的不同,思路是跟顺序栈差不多的,我就说一下思路吧。
①初始化时使之栈顶置空(NULL);
②入栈则先生成一个新结点,然后利用第二章学到的链式存储的插入知识就OK了;
③出栈则需记得先判断栈空与否,然后将栈顶元素付给一个变量,用一个临时结点p保存栈顶元素,修改栈顶指针,最后记得释放原栈顶的空间(delete p);
④取栈顶元素同样先判断栈空与否,非空即可返回栈顶元素。
队列
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。
因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO)的线性表。
下面来看一下队列的两种存储结构(顺序存储结构和链式存储结构)。
顺序队列
(1)队头不动,出队列时队头后的所有元素向前移动
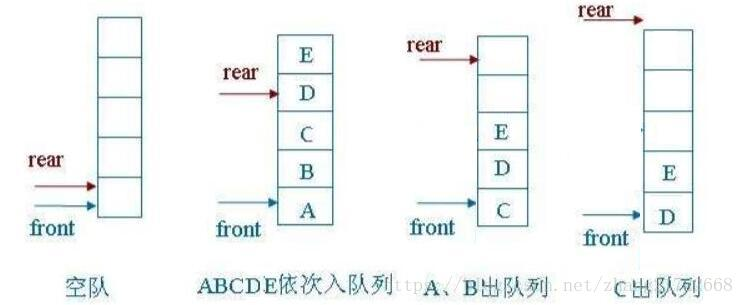
缺陷:操作是如果出队列比较多,要搬移大量元素。
(2)队头移动,出队列时队头向后移动一个位置

如果还有新元素进行入队列容易造成假溢出。
参考链接:https://blog.csdn.net/will130/article/details/49306523
扩充知识:
假溢出:顺序队列因多次入队列和出队列操作后出现的尚有存储空间但不能进行入队列操作的溢出。
真溢出:顺序队列的最大存储空间已经存满二又要求进行入队列操作所引起的溢出。
为了解决假溢出的问题,我们引入了循环队列的概念。
循环队列
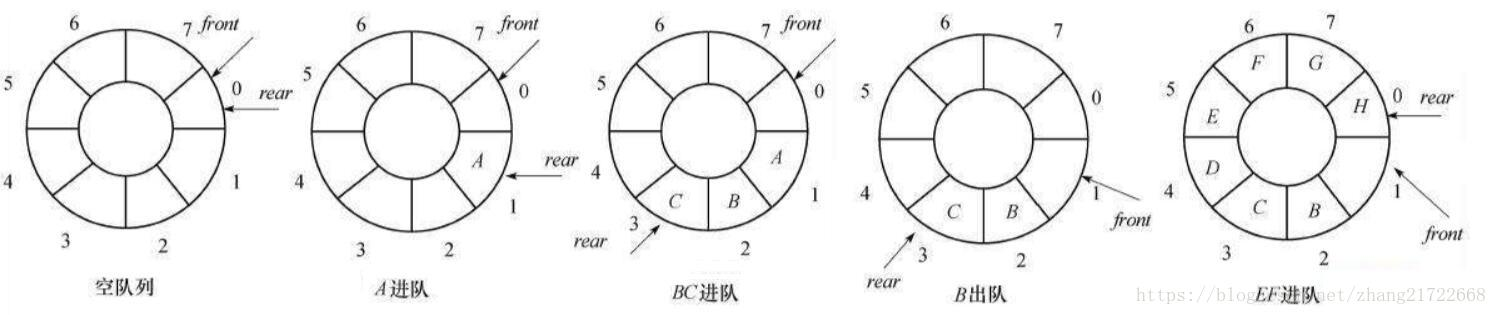
对于循环队列不能以头、尾指针的值是否相同来判别队列空间是“满”还是“空”。在这种情况下,通常有以下两种处理方法:
①少用一个元素空间,即队列空间大小为m时,有m-1个元素就认为是队满。这样判断队空的条件不变,即当头、尾指针的值相同是,则认为队空;而当尾指针在循环意义上加1后是等于头指针,则认为队满。因此,在循环队列中对空和队满的条件是:
队空的条件:Q.front == Q.rear;
队满的条件:(Q.rear+1)%MAXSIZE == Q.front;
②另设一个标志位以区别队列是“空”还是“满”。
如设置一个标记flag;
初始值 flag = 0;入队列:flag = 1; 出队列:flag = 0;
队列为空时:(front == rear && flag == 0)
队列为满时:(front == rear && flag == 1)
链式队列
特殊的单链表,只在单链表上进行头删尾插的操作。
定义一个链式队列时,由于是链式队列,所以先定义一个存放数据域和指针域的结构体;队列结构体中定义一个队头指针和队尾指针;
typedef struct QNode
{
QElemType data;
struct QNode *_pNext;
}QNode;
typedef struct LQueue
{
QNode *pFront;
QNode *pRear;
}LQueue;
emmm....至于相关的基本操作,CSDN挺多的哈哈,想看的查一查就有了。(其实是我怕写得不好哈哈)
目标&想法:
多看书,多逛博客,多打题;
感觉自己不懂某样知识时,不断实践是最蠢但也是最直接有用的方法。
(每次写心得都挤不出几句话。。。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号