【大数据实验】使用hadoop实现倒排索引
零碎记事
自上次写博客,已经过了半年了。
这半年时间里,我退出了ACM,转入了计算机视觉的研究中,ACM的价值观与自己的价值观还是有所不符,感觉自己并不是那么适合一条路走到黑的竞赛,被束缚住了,还是诗与歌的生活更适合自己,能力低点又何妨,还是生活重要,所以转向压力稍低点(?)的科研项目里。
退出ACM后,也停止了刷OJ题,以写题解为主的博客,理所当然地失去了写作源泉,一停,就是半年。
说起来,当初转入计算机视觉研究的时候,还想着以后博客更新与这个领域相关的东西呢,可惜至今为止并没学到多少东西,仍然属于半吊子状态,实在是没内容拿得出手。
那,为什么现在又更博客了呢?看标题,还是大数据领域的。
这要跟本人目前就读的大数据专业说起,这个专业是学校新开的,而我们又是其第一届学生,学校对课程难度拿捏不太准,于是自开学后,发生了一系列离谱的事情,这里不吐不快。
开学后,第一件事是考上学期遗留下来必须得线下考的试,我们专业在这场考试中,挂掉了60%以上的人。。。这只是个开端,之后学校排错了课程。大数据的实验课,需要java和Linux作为前置课程,而这两个课程又是我们这个学期的二选一选修课(没错,java跟Linux,本来我们这学期只学其中一个,个人也很疑惑java为什么会是选修。。。),怎么考虑本都是下学期才上的,但是不知怎么的排到了这个学期。然后教务处还发现java跟Linux是选修,就在第二周把这两门课紧急调整成了必修,课表课程喜加二(大数据实验 + 原本没选的java或Linux两者其一),于是这个学期12门课程,加上一个数据结构课设,做个游戏出来的那种。。。学校也是很厉害,这么多个课,居然也不冲突,可能我们专业就两个班,专业课都是两个班一起上,一个教室就能装得下,课表哪有空直接把课放哪就行了,好排。冲突是不冲突了,反人类的安排自然还是有的,就拿Java说事,Java有实验课,上这个实验课我们得跨校区去上,一般来讲,如果有两节连上的情况,那应该是放在同一个时间段比较合适,不用跑来跑去嘛。现实情况呢,一学期12门课的专业,有那么多选择的余地么,幺蛾子就这么来的,星期三有个连堂的java实验课,虽然连堂,连接的是上午跟下午,一节排在上午最后一节课,一节排在下午第一节课,就连Java老师都吐槽“我怎么看不懂你们专业的排课?”,大家笑而不语。提一下,我们星期三是全天满课从早上8点上到晚上9点多的,当天我们这专业的学生活动路线基本如下:宿舍早上起床->去宿舍校区的教室上课->骑羊跨校区上实验课->骑羊跨校区回宿舍校区吃饭睡午觉->起床又骑羊跨校区上实验课->骑羊跨校区会宿舍校区的教室上课->吃个晚饭,太累了,宿舍里歇会->去宿舍校区的教室上课->回宿舍。一天跨n次校区还不带休息,大家表示都很淦。还有其他操作,什么周一到周六早上第一节课天天有课,大数据实验课为什么不干脆跟java实验课排在一起,等等等等,都是我们大数据专业与其他专业的饭后谈资。
听说学弟学妹们就好很多了,大一取消了数电课(好像我们一半的挂科率由这个科贡献的),另外大数据实验课正确地排到大二下学期,但是舒服都是学弟学妹们的,与我们无关。
一学期12门课,当然很难顶,尤其是这个大数据实验课,一堆坑,是吃时间的大户,这学期时间本来就少,再来这么一手,连我这个有相当计算机基础的学生都感到了很大压力,预计这学期挂科率比上学期还高。
但是眼睁睁看着自己专业挂科率一路攀升还是于心不忍,力所能及地做些自己能做到的事吧。。。
这次开的大数据实验篇,主要面向自己专业的学生,让他们百度的时候至少可以百度出好点的参考材料。。。
题目:倒排索引
输入:多个文件,文件里都是一些单词
输出:要求使用MapReduce编程,统计文件单词,以N、M字母为界限进行分区,最终输出格式如下:
word1 inputfile1.txt->count1,inputfile2.txt->count2,... word2 inputfile1.txt->count1,inputfile2.txt->count2,... word3 inputfile1.txt->count1,inputfile2.txt->count2,... ...
思路:使用两次MapReduce,第一次MapReduce产生的文件是第二次MapReduce的输入
第一次MapReduce:使用WordCount,统计文件单词,outputKey是word->file.txt,outputValue是count
第二次MapReduce:
Map思路:k1 是Object, v1是每行数据word->file.txt \t count,k2是word,v2是file.txt->count
Reduce思路:k1,v1与Mapper的output一致,k2是word,v2是file1.txt->count1,file2.txt->count2,......
代码:
第一次MapReduce(WordCount)的代码:
MainClass
1 package WordCount; 2 3 import java.io.IOException; 4 import java.net.URI; 5 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.IntWritable; 10 import org.apache.hadoop.io.Text; 11 import org.apache.hadoop.mapreduce.Job; 12 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 13 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 14 15 public class MainClass { 16 public static void main(String[] args) throws IOException, Exception { 17 Configuration conf = new Configuration(); 18 Job job = Job.getInstance(conf, "Word Count"); 19 20 if(args.length != 2) { 21 System.err.println("两个参数 <input> <output>"); 22 System.exit(2); 23 } 24 25 final FileSystem fileSystem = FileSystem.get(new URI(args[0]), conf); 26 if(fileSystem.exists(new Path(args[1]))) 27 fileSystem.delete(new Path(args[1]), true); 28 29 job.setJarByClass(MainClass.class); 30 31 job.setMapperClass(WCMapper.class); 32 job.setMapOutputKeyClass(Text.class); 33 job.setMapOutputValueClass(IntWritable.class); 34 35 job.setCombinerClass(WCReducer.class); 36 37 job.setPartitionerClass(WCPartitioner.class); 38 job.setNumReduceTasks(3); 39 40 job.setReducerClass(WCReducer.class); 41 job.setOutputKeyClass(Text.class); 42 job.setOutputValueClass(IntWritable.class); 43 44 FileInputFormat.setInputPaths(job, new Path(args[0])); 45 FileOutputFormat.setOutputPath(job, new Path(args[1])); 46 47 job.waitForCompletion(true); 48 } 49 }
Mapper
1 package WordCount; 2 3 import org.apache.hadoop.mapreduce.Mapper; 4 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 5 import org.apache.hadoop.io.Text; 6 7 import java.io.IOException; 8 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.IntWritable; 11 12 public class WCMapper extends Mapper<Object, Text, Text, IntWritable> { 13 14 @Override 15 protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) 16 throws IOException, InterruptedException { 17 String line = value.toString().trim(); 18 String[] words = line.split(" "); 19 FileSplit inputSplit = (FileSplit)context.getInputSplit(); 20 Path path = inputSplit.getPath(); 21 String filename = path.getName(); 22 for(String word : words) 23 context.write(new Text(word + "->" + filename), new IntWritable(1)); 24 } 25 26 }
Partitioner
1 package WordCount; 2 3 import org.apache.hadoop.mapreduce.Partitioner; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.io.IntWritable; 6 public class WCPartitioner extends Partitioner<Text, IntWritable> { 7 8 @Override 9 public int getPartition(Text key, IntWritable value, int numPartitions) { 10 char firstCharacter = Character.toUpperCase(key.toString().charAt(0)); 11 12 if(firstCharacter >= 'A' && firstCharacter <= 'M') return 1; 13 if(firstCharacter >= 'N' && firstCharacter <= 'Z') return 2; 14 return 0; 15 } 16 17 }
Reducer
1 package WordCount; 2 3 import org.apache.hadoop.mapreduce.Reducer; 4 import org.apache.hadoop.io.Text; 5 6 import java.io.IOException; 7 8 import org.apache.hadoop.io.IntWritable; 9 public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> { 10 11 @Override 12 protected void reduce(Text key, Iterable<IntWritable> value, 13 Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { 14 int sum = 0; 15 for(IntWritable i : value) 16 sum += i.get(); 17 18 context.write(key, new IntWritable(sum)); 19 } 20 21 }
第二次MapReduce的代码
MainClass
package Sort; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class SortMain { public static void main(String[] args) throws IOException, Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "Sort Index"); if(args.length != 2) { System.err.println("两个参数 <input> <output>"); System.exit(2); } final FileSystem fileSystem = FileSystem.get(new URI(args[0]), conf); if(fileSystem.exists(new Path(args[1]))) fileSystem.delete(new Path(args[1]), true); job.setJarByClass(SortMain.class); job.setMapperClass(SortMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setPartitionerClass(SortPartitioner.class); job.setNumReduceTasks(3); job.setReducerClass(SortReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
Mapper
1 package Sort; 2 3 import org.apache.hadoop.mapreduce.Mapper; 4 5 import java.io.IOException; 6 7 import org.apache.hadoop.io.Text; 8 9 public class SortMapper extends Mapper<Object, Text, Text, Text> { 10 11 @Override 12 protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context) 13 throws IOException, InterruptedException { 14 String line = value.toString().trim(); 15 if(line.length() == 0) return; 16 String[] str1 = line.split("\t"); 17 String[] str2 = str1[0].split("->"); 18 String word = str2[0]; 19 String file = str2[1]; 20 String num = str1[1]; 21 22 context.write(new Text(word), new Text(file + "->" + num)); 23 } 24 25 }
Partitioner
1 package Sort; 2 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Partitioner; 5 6 public class SortPartitioner extends Partitioner<Text, Text> { 7 8 @Override 9 public int getPartition(Text key, Text value, int numPartitions) { 10 char firstCharacter = Character.toUpperCase(key.toString().charAt(0)); 11 12 if(firstCharacter >= 'A' && firstCharacter <= 'M') return 1; 13 if(firstCharacter >= 'N' && firstCharacter <= 'Z') return 2; 14 return 0; 15 } 16 17 }
Reducer
1 package Sort; 2 3 import org.apache.hadoop.mapreduce.Reducer; 4 5 import java.io.IOException; 6 7 import org.apache.hadoop.io.Text; 8 9 public class SortReducer extends Reducer<Text, Text, Text, Text> { 10 11 @Override 12 protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, Text>.Context context) 13 throws IOException, InterruptedException { 14 String v2 = ""; 15 for(Text v1 : value) 16 v2 += v1.toString() + ","; 17 v2 = v2.substring(0, v2.length()-1); 18 19 context.write(key, new Text(v2)); 20 } 21 22 }
实验过程
输入文件有3个

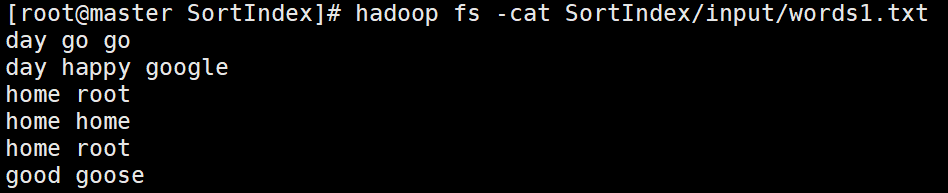
words1.txt
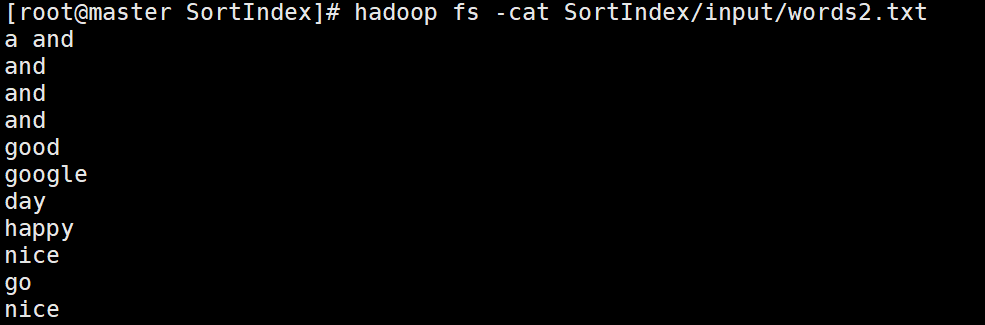
words2.txt
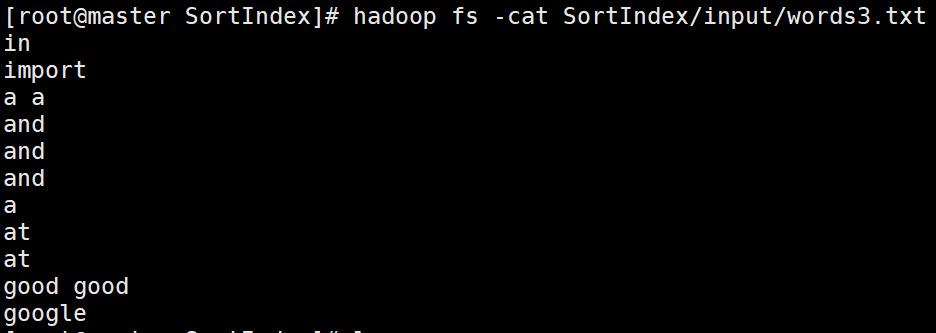
words3.txt
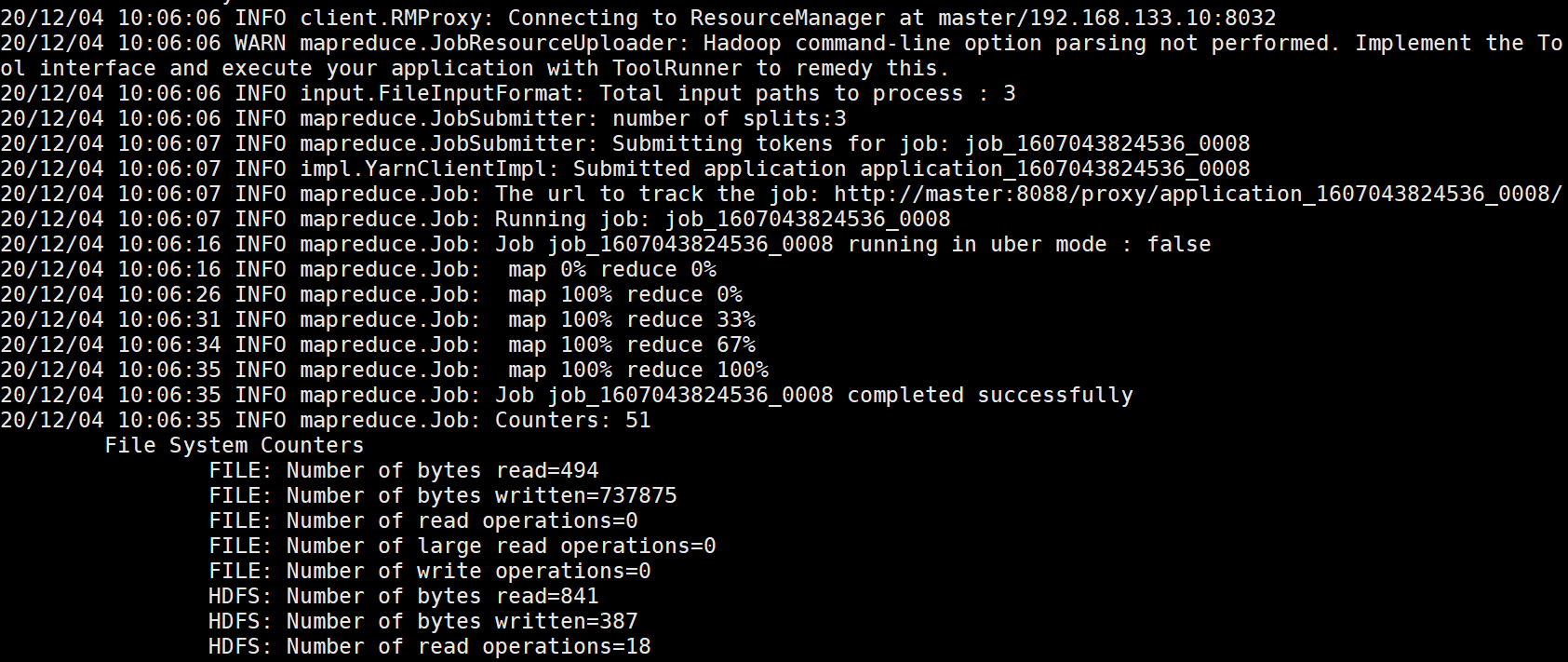
接下来要进行两次MapReduce操作,为执行方便,我写了个shell脚本,shell会按照脚本内容逐条运行指令,调试起来就很方便

运行脚本(实际上就是按顺序运行上面两条红线的指令)

整个过程非常顺利
看看输出路径下的文件,确实没问题
先看看第一次MapReduce的结果



是WordCount没错了,我们看看这基础之上第二次MapReduce的结果

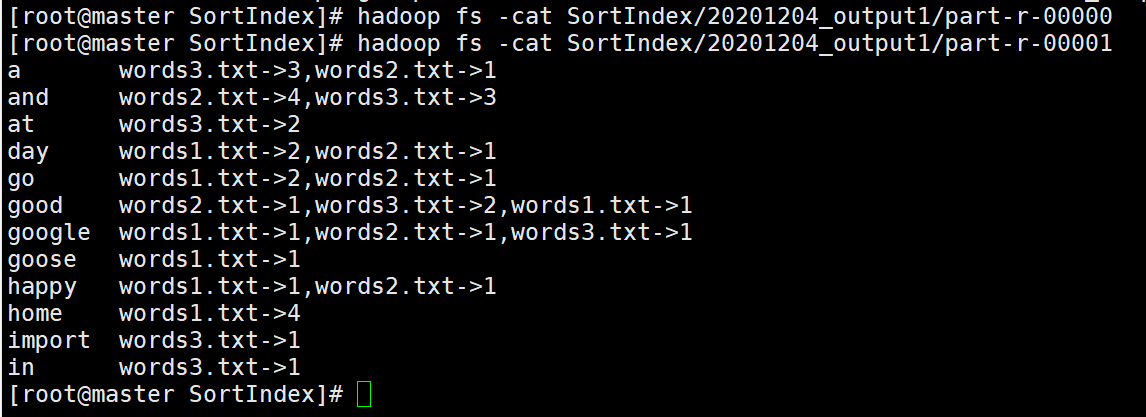

可以看到并没有什么问题,这就是倒排索引的整个实验过程了。
写程序不一定一次就能成功的,大家可以看到前边有很多其他的output文件,都是有问题的= =,后来慢慢调试到成功能展示出来罢了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号