shell的正则表达式-grep
环境:centos7、grep
总览
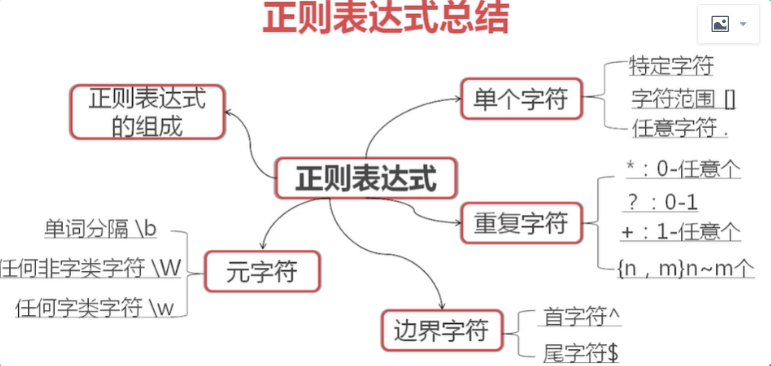
1、范围内字符:单个字符 [ ]
特定字符 ‘X’
范围字符 [ ] [^]
任意字符 .
数字字符:[0-9],[259]
[root@SmartCommunity-Node01 tmp]# more d.txt
1
2
3
4
5
6
7
8
[root@SmartCommunity-Node01 tmp]# grep '[0-3]' d.txt
1
2
3
[root@SmartCommunity-Node01 tmp]# grep '[579]' d.txt
5
7
小写字符:[a-z]
大写字符:[A-Z]
[root@SmartCommunity-Node01 tmp]# more d.txt
a
b
Z
C
[root@SmartCommunity-Node01 tmp]# grep '[a-z]' d.txt
a
b
[root@SmartCommunity-Node01 tmp]# grep '[A-Z]' d.txt
Z
C
[root@SmartCommunity-Node01 tmp]# grep '[a-zA-Z]' d.txt
a
b
Z
C
特殊字符查看[.]
[root@SmartCommunity-Node01 tmp]# cat d.txt
a
b
Z
C
,/
}
.
[root@SmartCommunity-Node01 tmp]# grep '[}/]' d.txt
,/
}
范围内字符:反向字符 ^
取反:[^0-9](取出没带数字的文本),[^0]
[root@SmartCommunity-Node01 tmp]# cat d.txt
a
b
Z
C
,/
}
.
[root@SmartCommunity-Node01 tmp]# grep '[^a-zA-Z]' d.txt
,/
}
.
任意字符(取出所有内容)
代表任意一个字符:'.'
注意
'[.]' #就是代表取含有.的内容
'\.' #\反斜杠作用是表示后面字符代表原意,所以和’[.]‘功能一样
的区别
[root@SmartCommunity-Node01 tmp]# cat d.txt
a
b
Z
C
,/
}
.
[root@SmartCommunity-Node01 tmp]# grep '.' d.txt
a
b
Z
C
,/
}
.
2、正则表达式其他符号
边界字符:头尾字符
^ : ^root 注意与[^]的区别
$ : false$ 表示尾
^$ : 头尾相连表示空行
[root@SmartCommunity-Node01 tmp]# cat d.txt
a
b
234
root,345
rtery-false
[root@SmartCommunity-Node01 tmp]# grep '^root' d.txt
root,345
[root@SmartCommunity-Node01 tmp]# grep 'false$' d.txt
rtery-false
[root@SmartCommunity-Node01 tmp]# grep -v '^$' d.txt
a
b
234
root,345
rtery-false
元字符(代表普通字符或特殊字符)
\w :匹配任何字符类字符,包括下划线 即 ([a-zA_Z0-9_])一个意思
\W:匹配任何非字符类字符:即([^a-zA_Z0-9_])一个意思
\b:代表单词的分割(表示有符号分割开)
[root@SmartCommunity-Node01 tmp]# cat d.txt
a
,
:
\
b
2
_
[root@SmartCommunity-Node01 tmp]# grep '\w' d.txt
a
b
2
_
[root@SmartCommunity-Node01 tmp]# grep '\W' d.txt
,
:
\
#\b 分隔符的使用
[root@SmartCommunity-Node01 tmp]# grep 'x' d.txt
xy
c:x
ib:x:r
1xf
z,x.p
z.x.9
[root@SmartCommunity-Node01 tmp]# grep '\bx\b' d.txt
c:x
ib:x:r
z,x.p
z.x.9
3、正则表达式字符组合
字符串
'root' '1000' 'm..c'(表示以m开始c结束的四位字符串)
'[a-z][A-Z]' 表示以小写字母开始大写字母结束的两个字符串
’[0-9][0-9]‘ 表示两个数字的字符串,如果要找只有两个数字的可以加上分割符'\b[0-9][0-9]\b'
重复:
* :零次或多次匹配前面的字符或子表达示
+ :一次或多次匹配前面的字符或子表达示
? :零次或一次匹配前面的字符或子表达示
[root@tmp]# more d.txt
s
se
e
ses
see
es
[root@tmp]# grep 'e*' d.txt
#表示有e没e都可以
s
se
e
ses
see
es
[root@tmp]# grep 'e\+' d.txt
#表示e有一个或多个都可以
se
e
ses
see
es
[root@tmp]# grep 'e\?' d.txt
#表示没有e和有一个e都可以
s
se
e
ses
see
es
多个字符进行重复
(se)*: 有的情况 无 、se 、sese 、sesesese..
grep '\(se\)*' b.txt
(se)+: 有的情况 se 、sese 、sesesese..
grep '\(se\)\+' b.txt
(se)? :有的情况 无 、se
grep '\(se\)\?' b.txt
重复特定次数:{n,m}
*:{0,}
+:{1,}
?:{0,1}
[root@tmp]# grep '[0-9]\{2,3\}' d.txt
44
444
12
[root@tmp]# more d.txt
1
44
444
12
7
,
./
任意字符串的表示:.*
例如:^r.* 以r开头的任意字符串
m.*c m开头c结尾的字符串
grep '\bm[a-z]*c\b' passwd m前是分隔符 c后是分隔符,中间是任意的字母数
[root@tmp]# grep '^r.*' passwd
root:x:0:0:root:/root:/bin/bash
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
[root@tmp]# grep 'm.*c' passwd
libstoragemgmt:x:998:997:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin
逻辑的表示
| : 逻辑或的表示 例如 ' bin/(false|true)' 注意表达式要加\转意
[root@tmp]# grep 'bin/\(false\|true\)' passwd
syslog:x:996:994::/home/syslog:/bin/false
4、案例
案例:找出4-10位的qq号
[root@SmartCommunity-Node01 tmp]# more d.txt
1
23423444
444234
12234
7234
,
./
1234
[root@SmartCommunity-Node01 tmp]# grep '^[0-9]\{4,10\}$' d.txt
23423444
444234
12234
7234
1234
案例二:匹配15位或18位身份证号(支持带X的)
注意首位不能为0
尾部可以是X (使用逻辑或 |)
[1-9]([0-9]{13}|[0-9]{16})[0-9xX]
表示:第一位 1-9的数字
第二位 0-9数字重复13次或者0-9数字重复16次
第三位 0-9的数字包括xX
注意:实际运算加转义字符和首位字符
[root@tmp]# grep '^[1-9]\([0-9]\{13\}\|[0-9]\{16\}\)[0-9xX]$' d.txt
511023198810056818
125487545454559
12548754545455X
[root@tmp]# cat d.txt
o1235345344433543
444234
511123198810056818
125487545454559
12548754545455X
01254879541233541X
案例三、匹配密码(由数字、26个字母和下划线组成)
直接使用元字符 \w :匹配任何字符类字符,包括下划线 即 ([a-zA_Z0-9_])
直接匹配元字符出现一次或者多次 +
实现 \w+ ,加上转义字符和 首尾符号即可
grep '^\w\+$' d.txt
做一个决定,并不难,难的是付诸行动,并且坚持到底。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号