
华为昇腾AI芯片:重构设计,转向CUDA生态
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
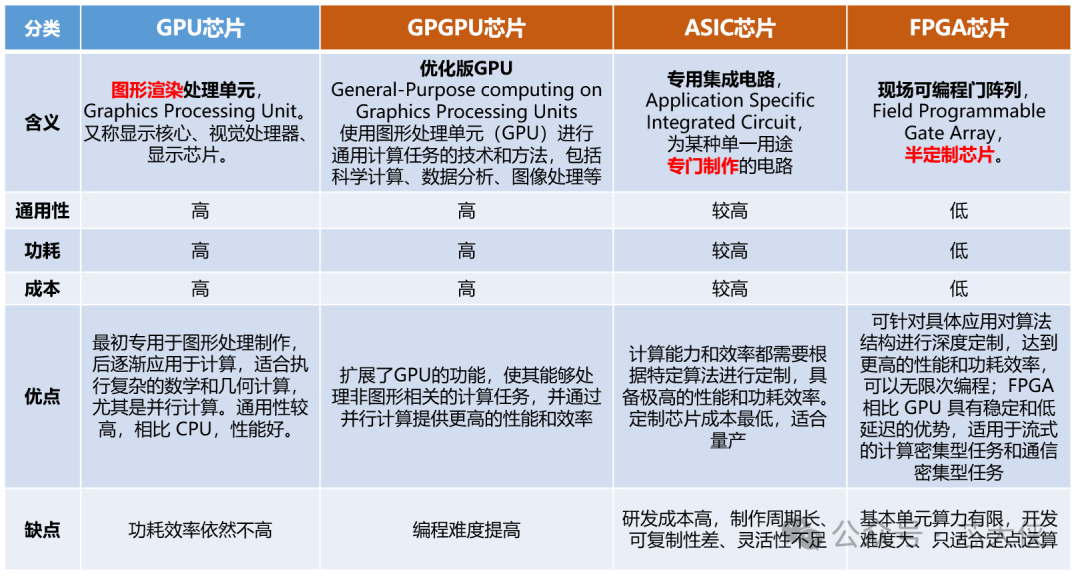
据网上爆料:华为正彻底重构昇腾AI芯片的设计路线,由原本的ASIC(专用集成电路)向 GPGPU(通用图形处理器)转型。

添加图片注释,不超过 140 字(可选)
华为昇腾AI芯片的转向,并非一时兴起,而是基于对当前AI技术发展趋势的深刻洞察,更是无奈之举。在 AI 训练领域,尤其是大模型的训练中,模型的参数规模和复杂性呈指数级增长。ASIC 芯片虽然在特定算法和任务上能够实现极高的能效比,但其“专用性”在面对模型结构快速迭代时,反而成为了限制。相比之下,GPGPU芯片凭借其强大的并行计算能力和高度的编程灵活性,能够更好地适应这种“通用”的、探索性的训练需求。
添加图片注释,不超过 140 字(可选)
华为的战略转向势在必行,通过构建中间件和翻译层技术,让习惯于 CUDA 编程的开发者能够以最小的改动,甚至无需改动,就将现有模型和应用迁移到昇腾硬件上。因此,这一战略调整,致力于通过软件层兼容英伟达(NVIDIA)的CUDA生态,以突破生态壁垒、扩大市场份额,并应对美国制裁下的技术挑战。

添加图片注释,不超过 140 字(可选)
CUDA是Compute Unified Device Architecture的简称,是英伟达(NVIDIA)于 2006 年推出的一种并行计算平台和编程模型。它的核心目标是让开发者能够充分利用 GPU(图形处理单元)的并行计算能力,将原本只能通过 CPU(中央处理单元)完成的计算任务转移到 GPU 上运行。
简单来说,CUDA 是一个软件平台,它提供了一套编程接口和工具,使得开发者可以用高级语言(如 C、C++、Python 等)编写程序,利用 GPU的并行处理能力, 执行像深度学习、科学计算、图像和视频处理等复杂任务,从而显著提高计算效率。
因此,对于国产AI芯片而言,除了性能外,核心还是生态。
🔄 一、战略转向的核心原因
-
生态壁垒突破需求:英伟达(NVIDIA)凭借CUDA平台构建了深厚的生态护城河,全球超过90%的开源AI项目都是基于CUDA开发,已形成了一个庞大的生态系统。其庞大的开发者社区和丰富的软件库(如cuDNN、cuBLAS)形成了极强的黏性。华为昇腾原有的CANN软件生态尽管全栈自研,但在开发者规模、工具链完整性和第三方框架支持上差距显著,导致客户迁移成本高、意愿低。对于华为而言,单纯在硬件性能上追赶英伟达已远远不够,关键在于能否实现对 CUDA 生态的无缝移植。开发者已经习惯了 CUDA 的编程模型和工具链,他们不愿意也没有足够的时间和成本去为一套全新的硬件和软件栈重写所有代码。
-
技术路线灵活性需求:昇腾原有的ASIC架构(达芬奇架构)针对特定AI任务(如矩阵计算)能效高,但通用性不足,难以灵活适应快速迭代的AI算法(如大模型训练中的稀疏计算、双精度浮点运算)和科学计算等多元化场景。转向GPGPU可提升架构的通用性和编程灵活性,更好地满足广泛的计算需求。
-
市场竞争压力:在中国市场,尽管英伟达高端芯片受禁售影响,但其通过“特供版”芯片(如H20)和强大的CUDA生态仍占据主导地位。国内企业甚至宁愿采购“水货”英伟达芯片也不愿迁移平台。华为需通过兼容策略降低用户迁移门槛,提升芯片市场份额。
🛠️ 二、技术实现路径
-
硬件架构重构:
-
从ASIC到GPGPU:新芯片将放弃纯ASIC的“硬化”设计,采用类似英伟达的SIMT(单指令多线程)架构与Tensor Core混合设计,增强通用计算能力(如支持双精度浮点),同时保留部分可配置矩阵单元以兼顾能效。
-
互联技术升级:采用高速互联总线(类似NVLink),支持多芯片堆叠,突破大模型训练中的“内存墙”瓶颈。华为昇腾900超节点展示了其通过高速互联技术实现384颗芯片高效协同的能力。
-
软件生态兼容:
-
动态翻译层:华为将开发“CUDA-to-CANN”转译层,拦截CUDA API调用并将其动态翻译为CANN指令,目标是让开发者无需修改代码即可在昇腾硬件上运行现有CUDA程序。此举类似于开源项目ZLUDA(在AMD硬件上实现CUDA兼容)的思路。
-
开源CANN:华为已宣布开源CANN软件栈,旨在吸引开发者参与生态建设,降低开发门槛,同时为兼容层提供底层支持。开源策略有助于建立信任,汇聚社区力量,并鼓励第三方开发兼容工具。
-
分层解耦策略:华为官方聚焦底层硬件和CANN优化,而鼓励开源社区主导开发兼容CUDA的中间件,以降低法律风险(规避英伟达EULA限制)和技术风险。 三、挑战与风险
-
技术实现复杂度:
-
性能损耗:API转译可能引入性能开销,需极致优化以接近原生CUDA的性能。
-
兼容性覆盖:CUDA生态庞大且持续更新,确保对大量API和库(如cuDNN、cuFFT)的完整兼容是一项长期且艰巨的工程。
-
外部制约因素:
-
先进制程供应:GPGPU对先进制程(如5nm及以下)依赖度高,在美国制裁背景下,如何稳定获得高性能代工产能是重大不确定性因素。
-
知识产权风险:SIMT指令集、缓存一致性协议等核心IP可能涉及英伟达和AMD的专利,需谨慎设计以避免侵权。
-
生态竞争压力:英伟达CUDA生态已形成强大的网络效应和先发优势。国内其他GPU厂商(如沐曦、摩尔线程)也选择了兼容CUDA的路径,华为将面临激烈竞争。
🔮 四、未来影响与展望
-
对国内市场:若成功兼容CUDA,将为国内用户提供一个高性能的“第二选择”,降低对英伟达的依赖,增强供应链安全。云厂商(如阿里、腾讯)和服务器供应商(如浪潮)的议价能力有望提升。
-
对华为自身:这是一次“自我否定”式的战略豪赌。成功则打通生态壁垒,失败可能损失原有ASIC领域的积累。但这也是在外部制裁下寻求破局的必要尝试。
-
对国产AI芯片行业:华为的体量和资源可能对中小国产GPGPU初创公司(如壁仞、沐曦、天数)形成降维打击,但同时也有可能通过开源CANN等方式助力构建更统一的国产软硬件生态。
💎 总结
华为昇腾AI芯片向GPGPU架构转型并兼容CUDA生态,是一次以生态突破为核心的战略重构。其通过硬件通用化、软件开源化、生态兼容化的组合策略,旨在打破英伟达的生态垄断,为中国AI算力基础设施提供更多元、自主的选择。
然而,该战略面临技术、生态和法律的多重挑战,其最终成功与否,取决于华为的工程实现能力、社区运营能力以及应对国际制裁的韧性。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号