
国产GPU摩尔线程的技术突破与产品布局
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
2025年,中国半导体产业在政策和资本的双重推动下正在迎来关键变革。作为国产GPU领域的领军企业,摩尔线程GPU以其全自研的创新架构,突破技术壁垒,在人工智能、视觉渲染与高性能计算领域展现出令人瞩目的实力。
其最新专利技术“计算核心抢占方法”的突破,不仅印证了公司在异构计算领域的创新实力,也代表着国产GPU在高端芯片设计领域迈出重要一步。
摩尔线程
CONTENT
技术新突破
自2020年成立以来,摩尔线程以自主研发驱动高性能计算发展的核心战略。作为国内全功能GPU领域的领军企业,摩尔线程始终聚焦图形渲染与AI计算融合。被誉为“中国版英伟达”的摩尔线程,此次在GPU架构设计上的技术突破和成果进一步巩固了其在异构计算市场的竞争力。
*2025年7月摩尔线程提出“AI工厂”理念
7月25日,上海——在世界人工智能大会(WAIC 2025)开幕前夕,摩尔线程在分享会上创新性提出“AI工厂”理念。创始人兼CEO张建中在主题演讲中表示,这座“AI工厂”的智能“产能”将由五大核心要素(加速计算通用性、单芯片有效算力、单节点/集群效率及稳定性)来构建新一代AI训练基础设施,旨在突破大模型训练效率瓶颈,打造AGI时代的先进模型生产平台。

添加图片注释,不超过 140 字(可选)
*技术专利申请
据国家知识产权局信息显示,2025年4月,摩尔线程智能科技(北京)股份有限公司申请一项名为“计算核心抢占方法、装置、设备、存储介质和程序产品”的专利(公开号CN120510016A),该技术通过优化图形处理器中任务调度机制,显著提升了计算核心的执行效率。
IPO进程
中国半导体产业正迎来历史性跨越,政策东风与资本浪潮共同托举起国产GPU领军企业——摩尔线程的IPO征程。在"自主可控"国家战略指引下,这家覆盖B/C端市场的独角兽企业,即将以科创板IPO为节点,书写国产高性能计算芯片的新篇章。

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
技术应用升级
摩尔线程8月20日发布v310.120显卡驱动,主要升级包括:
系统支持:新增Win11 24H2正式支持,WDDM驱动升级至3.2
专业性能:OpenGL 4.4框架优化,支持Blender 4.x等软件工作流
游戏优化:
《埃尔登法环》平均帧率提升80%+
《双影奇境》平均帧率提升40%
同步优化《黑神话:悟空》《NBA 2K25》等10+款热门游戏
摩尔线程-SoC
CONTENT
摩尔线程的长江系列SoC是在2024年下半年首次对外公开,主要面向智能座舱、AI PC、边缘计算终端等场景。基于自主研发的全功能异构计算架构、AI SoC软硬件协同技术,以及图形+AI软件栈的积累,成功量产了面向智能边缘和智能终端的长江异构计算芯片,集成自研全功能GPU、CPU、NPU、VPU等多元算力于一体。

添加图片注释,不超过 140 字(可选)
摩尔线程-GPU
CONTENT
摩尔线程全功能GPU
苏堤:用于 MTT S10、S30、S50、S1000
春晓:用于 MTT S2000、S3000、S70、S80
曲院:用于 MTT X300、X1000、S90
平湖:用于 MTT S4000、S5000、S6000
尽管摩尔线程目前尚未有 GPU 产品直接应用于汽车领域,但其 GPU 产品线在通用计算领域展现出极强的技术实力与生态潜力。摩尔线程致力于创新面向元计算应用的新一代 GPU,构建融合视觉计算、3D 图形计算、科学计算及人工智能计算的综合计算平台,建立基于云原生 GPU 计算的生态系统,助力驱动数字经济发展。
公司研发设计全功能 GPU 芯片及相关产品,支持 3D 高速图形渲染、AI 训练推理加速、超高清视频编解码和高性能科学计算等多种组合工作负载,兼顾算力与算效,能够为中国科技生态合作伙伴提供强大的计算加速能力,广泛赋能数字经济多个领域。
2022 年 3 月和 2022 年 11 月,摩尔线程已经成功研发并上市两颗 GPU 芯片:苏堤和春晓,围绕着两颗 GPU 芯片,摩尔线程打造了三款服务器 GPU 产品,分别是 MTT S2000,MTT S1000 和 MTT S3000。
苏堤芯片基于摩尔线程第一代 MUSA 架构,具有现代图形渲染、AI 计算加速以及科学计算机物理仿真等功能引擎,是第一款支持 AV1 编解码的 GPU,支持视频云、直播、8K 游戏等智能多媒体应用。
摩尔线程发布的春晓芯片同样基于第一代 MUSA 架构打造,其内部集成了 220 亿个晶体管,内置 MUSA 架构通用计算核心以及张量计算核心,可以支持 FP32、FP16 和 INT8 等计算精度。
MTT S3000 基于春晓芯片,物理形态为全高 3/4 长双槽。作为一款服务器端专用显卡,S3000 采用被动散热方式,整卡功耗 250W,外接供电线为标准 CPU 8pin。显卡的物理接口为 PCIE x16 并具备 PCIe Gen5 x16 的传输速率。在一个全功能的春晓芯片的支持下,S3000 的整体渲染、编解码性能相对于上一代芯片均具备明显的能力提升。
平湖 MTT S4000 是基于摩尔线程曲院 GPU 架构打造的全功能元计算卡,为千亿规模大语言模型的训练、微调和推理进行了定制优化,结合先进的图形渲染能力、视频编解码能力和超高清 8K HDR 显示能力,助力人工智能、图形渲染、多媒体、科学计算与物理仿真等复合应用场景的计算加速。
MTT S4000 全面支持大语言模型的预训练、微调和推理服务,MUSA 软件栈专门针对大规模集群的分布式计算性能进行了优化,适配主流分布式计算加速框架,包括 DeepSpeed, Colossal AI,Megatron 等,支持千亿参数大语言模型的稳定预训练。
2025年7月,在世界人工智能大会 WAIC 期间,MTT S5000、MTT S6000发布。
MTT S4000
CONTENT
大模型训练 / 微调实例
MTT S4000 配备的 Tensor 核心算力、48GB 显存以及超高速卡间互连接口 MTLink,可以有效支持多种主流大语言模型训练,包括: LLaMA / GPT / ChatGLM / Qwen / Baichuan 等。通过摩尔线程大模型训练平台,支持单机 8 卡和多机多卡等多种分布式训练策略,加速从 60 亿参数到千亿参数大语言模型训练以及微调任务。
集群扩展效率
摩尔线程 KUAE 千卡模型训练平台,支持千亿参数模型的预训练、微调和推理,可实现 91% 的千卡集群线性加速比,摩尔线程从应用、分布式系统、训练框架、通讯库、固件、算子、硬件全方位进行优化。
MTLink 是基于 MTT S4000 自研的卡间互连技术,支持 2 卡、4卡、8 卡 MTLink Bridge 互连,提升了卡间互连带宽,卡间互连 I/O 带宽达到 240GB/s,可加速集群从 64 卡到 1024 卡的训练速度以及多卡互连的线性度。
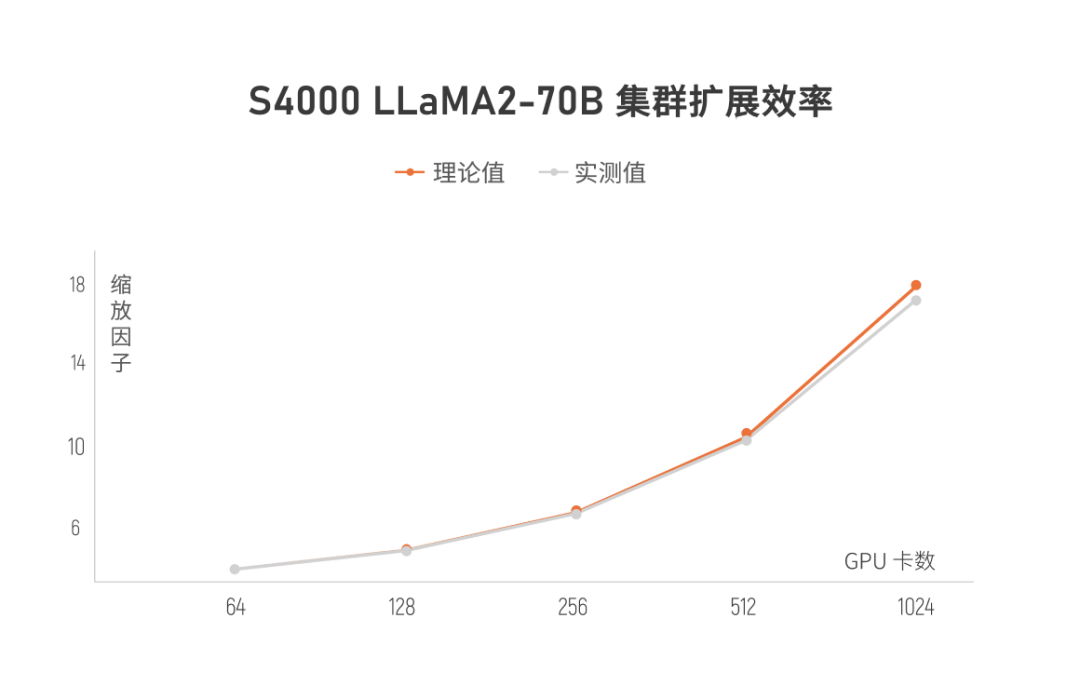
添加图片注释,不超过 140 字(可选)
大模型推理服务平台
MTT S4000 配备的 Tensor 核心算力以及 48GB 显存,可以有效支持主流大语言模型推理,包括:LLaMA / ChatGLM / Qwen / Baichuan 等主流系列大模型。
平台:KUAE ModelStudio - 是面向大语言模型应用场景开发者,基于摩尔线程 GPU 以及官方提供的模型,进行训练、微调和推理的一体化应用平台
MUSA Serving - 是摩尔线程提供的一套推理服务软件,可提供高性能、分布式的推理服务,支持 LLM、图片/视频生成模型、传统 AI 模型等后端模型部署
MT Transformer - 是一套针对摩尔线程 GPU 的分布式推理加速框架,实现了对基于 Transformer 架构 LLM 模型的推理加速
TensorX - 是一套针对摩尔线程 GPU 的推理加速框架,实现了对图片/视频生成、传统 AI 模型的推理加速。
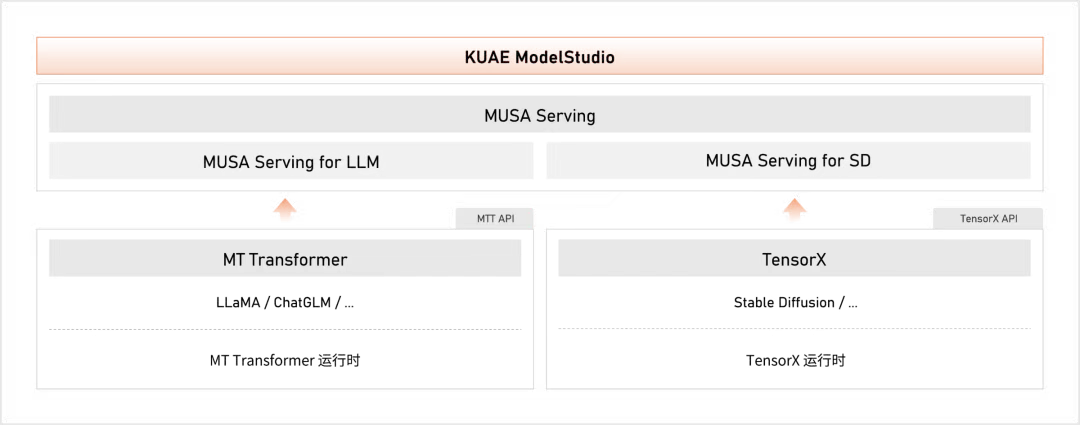
添加图片注释,不超过 140 字(可选)
支持主流图形 API
支持 DirectX、Vulkan、OpenGL、OpenGL ES 等主流图形 API,可为数字孪生、云游戏、云渲染、数字内容创作等场景提供全平台通用图形渲染能力支持。还可配合大模型推理能力,实现 AIGC 等多模态业务场景的一站式解决方案。
摩尔线程的GPU技术方案让计算更高效。其强劲的算力核心、先进的架构设计和开放的软件生态不仅提升了产业效能,也为各领域提供了定制化解决方案。随着技术持续迭代,摩尔线程GPU在未来智能计算中将扮演更关键角色,引领行业创新方向。
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
人工智能芯片与自动驾驶

 浙公网安备 33010602011771号
浙公网安备 33010602011771号